一、摘要
UNO-Bench 是面向“单模/全模”统一评测的开源基准,覆盖感知与推理两大维度,提供中文真实场景题目与多步开放问答(MO)。数据与工具强调高质量、人为主导构建,并配套通用打分模型以便自动化评测。
二、核心特性
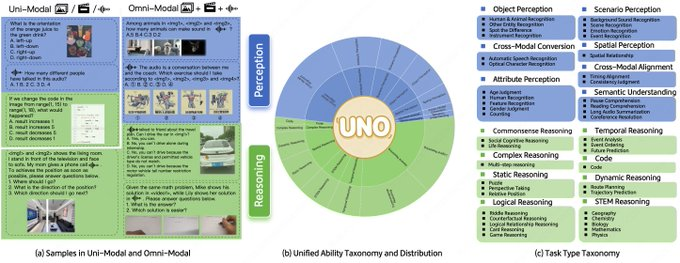
1、统一能力框架:44 类任务、5 种模态组合,单模与全模同一指标口径。
2、高质量与可解性:全模 1250 条,人审构建,跨模态 98% 可解。
3、效率优化:对 18 个公开基准自动压缩,评测加速约 90%,一致性约 98%。
4、题型更贴近真实:加入多步开放问答,覆盖复杂推理链。
5、通用评分:支持 6 类问题类型,OOD 场景下标注一致性约 95%。
6、关键发现:强模型呈“幂律协同”(能力随模态组合呈乘积型提升)。
三、安装
1、数据集:datasets.load_dataset("meituan-longcat/UNO-Bench") 获取默认分片。
2、源码与文档:GitHub 克隆仓库查看 README 与评测脚本示例。
3、环境:Python/Transformers/Datasets 常规环境即可,按仓库说明安装依赖。
四、典型用例
1、模型横向评测:统一尺度下比较单模与全模差异。
2、中文场景验证:生活/文化/社会等真实语境下的感知与推理能力。
3、推理链分析:用多步开放问答诊断长链推理弱点。
4、RAG/多模体系统:验证音频、图像、视频融合后的整体收益。
五、生态与竞品
1、生态:提供数据集、排行榜与论文;后续工具链在完善中。
2、竞品:与 MMBench、MMMU、MathVista 等偏视觉/学科基准相比,UNO-Bench强调“单模—全模统一评测”与中文真实场景;压缩方法便于快速对齐多基准。
六、局限与注意事项
1、自动压缩适用性需按任务验证,个别细分任务可能信息不足。
2、通用打分模型对长答案/生成式输出仍可能有偏差,建议抽样人工复核。
3、目前以中文场景为主,多语扩展与英文版仍在征集协作。
4、“幂律协同”属于经验发现,迁移到新任务需再验证。
七、项目地址
https://github.com/meituan-longcat/UNO-Bench
八、常见问题
Q: UNO-Bench 覆盖哪些模态与任务?
A: 涵盖音频、图像、视频等组合,共 5 种模态搭配与 44 类任务,面向感知与推理两大维度。
Q: 如何快速跑通 UNO-Bench 评测?
A: 通过 Hugging Face 加载数据,用仓库示例脚本与通用打分模型执行推理与评分。
Q: 自动压缩对结果可信度影响多大?
A: 在 18 个公开基准上保持约 98% 排名一致性,但仍建议结合原始集抽检。
Q: 是否支持英文或多语?
A: 官方当前聚焦中文场景,正寻找合作方共建英文与多语版本。
Q: 幂律协同是否对所有模型成立?
A: 主要在强模型上显著;对弱模型更像“短板效应”,需具体评测确认。