I. Zusammenfassung
UNO-Bench ist ein Open-Source-Benchmark zur einheitlichen Bewertung von „Einzelmodell-/Vollmodell“-Fragen, der sowohl Wahrnehmungs- als auch Denkprozesse abdeckt. Er bietet Fragen zu realen chinesischen Szenarien und mehrstufige offene Frage-Antwort-Fragen (MO). Die Daten und Werkzeuge legen Wert auf hohe Qualität und menschliche Expertise bei der Entwicklung und verfügen über ein allgemeines Bewertungsmodell für die automatisierte Auswertung.
II. Kernmerkmale
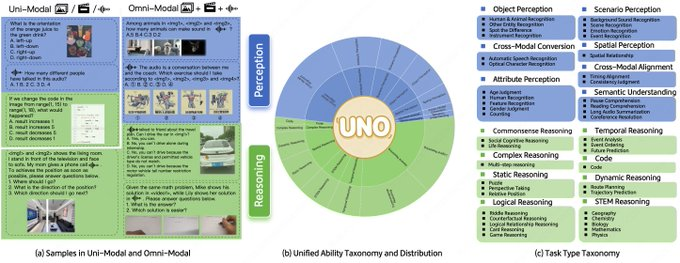
- Einheitliches Fähigkeitsrahmenwerk: 44 Aufgabentypen, 5 Modalitätskombinationen, mit dem gleichen Indikatorkaliber für Aufgaben mit einer einzigen Modalität und Aufgaben mit mehreren Modalitäten.
- Hohe Qualität und Lösbarkeit: 1250 vollmodale Datenpunkte, von Menschen überprüfte Konstruktion, 98 % modalitätsübergreifend lösbar.
- Effizienzoptimierung: Die automatische Komprimierung von 18 öffentlichen Benchmarks beschleunigt die Auswertung um ca. 90 % und verbessert die Konsistenz um ca. 98 %.
- Realistischere Fragetypen: Um auch komplexe Gedankengänge abzudecken, wurden mehrstufige, offene Fragen und Antworten hinzugefügt.
- Allgemeine Bewertung: Unterstützt 6 Fragetypen mit einer Übereinstimmung von ca. 95 % bei der Annotation in OOD-Szenarien.
- Wichtigste Erkenntnisse: Starke Modelle weisen eine „Potenzgesetz-Synergie“ auf (die Fähigkeiten nehmen mit den Modalkombinationen multiplikativ zu).
III. Installation
1. Dataset: datasets.load_dataset("meituan-longcat/UNO-Bench") Ruft die Standard-Shards ab.
- Quellcode und Dokumentation: Die README-Datei und Beispiele für Auswertungsskripte finden Sie im geklonten GitHub-Repository.
- Umgebung: Python/Transformers/Datasets. Eine Standardumgebung ist ausreichend. Installieren Sie die Abhängigkeiten gemäß den Anweisungen im Repository.
IV. Typische Anwendungsfälle
- Querschnittsbewertung des Modells: Vergleich der Unterschiede zwischen Einzelmodell und Gesamtmodell unter Verwendung einer einheitlichen Skala.
- Überprüfung chinesischer Szenarien: Wahrnehmungs- und Denkvermögen in realen/kulturellen/sozialen Kontexten.
- Analyse von Argumentationsketten: Verwenden Sie mehrstufige, offene Fragen, um Schwächen in langen Argumentationsketten zu diagnostizieren.
- RAG/Multimodales System: Validierung der Gesamtvorteile der Audio-, Bild- und Videofusion.
V. Ökologie und Wettbewerber
- Ökosystem: Bietet Datensätze, Ranglisten und wissenschaftliche Artikel; die Toolchain befindet sich in der Entwicklung.
- Konkurrenten: Im Vergleich zu visuellen/fachspezifischen Benchmarks wie MMBEC, MMMU und MathVista legt UNO-Bench Wert auf die „einheitliche Bewertung vom Einzelmodus bis zum Vollmodus“ und auf reale chinesische Szenarien; seine Komprimierungsmethode ermöglicht eine schnelle Ausrichtung mehrerer Benchmarks.
VI. Einschränkungen und Vorsichtsmaßnahmen
- Die Anwendbarkeit der automatischen Komprimierung muss für jede Aufgabe einzeln geprüft werden; für einige Teilaufgaben fehlen möglicherweise ausreichende Informationen.
- Das allgemeine Bewertungsmodell kann bei längeren Antworten/generativen Ausgaben noch Verzerrungen aufweisen, und es wird empfohlen, Beispiele manuell zu überprüfen.
- Derzeit liegt der Schwerpunkt auf chinesischsprachigen Szenarien, und wir sind weiterhin auf der Suche nach Kooperationen für mehrsprachige Erweiterungen und englische Versionen.
- Die „Potenzgesetz-Synergie“ ist eine empirische Entdeckung und muss bei der Übertragung auf neue Aufgaben erneut überprüft werden.
VII. Projektadresse
https://github.com/meituan-longcat/UNO-Bench
VIII. Häufig gestellte Fragen
F: Welche Modalitäten und Aufgaben deckt UNO-Bench ab?
A: Es umfasst Kombinationen aus Audio, Bildern und Video mit insgesamt 5 modalen Kombinationen und 44 Aufgabenkategorien, die sowohl die Wahrnehmungs- als auch die Denkdimension ansprechen.
F: Wie kann ich den UNO-Bench-Benchmark schnell ausführen?
A: Laden Sie Daten über Hugging Face und führen Sie Inferenz und Bewertung mithilfe von Beispielskripten aus dem Repository und einem allgemeinen Bewertungsmodell durch.
F: Wie stark beeinflusst die automatische Komprimierung die Zuverlässigkeit der Ergebnisse?
A: Die Übereinstimmung der Rangliste bleibt über 18 öffentlich verfügbare Benchmarks hinweg bei etwa 98 % erhalten, es wird jedoch weiterhin empfohlen, dies mit einer Stichprobenprüfung des ursprünglichen Datensatzes zu kombinieren.
F: Unterstützt es Englisch oder mehrere Sprachen?
A: Derzeit liegt der offizielle Schwerpunkt auf der chinesischen Sprachversion, und wir suchen Partner für die gemeinsame Entwicklung englischer und mehrsprachiger Versionen.
F: Gilt die Potenzgesetz-Kollaboration für alle Modelle?
A: Bei starken Modellen ist dies vor allem relevant; bei schwachen Modellen ähnelt es eher einem „Schwächste-Glied-Effekt“ und muss gesondert bewertet und bestätigt werden.