1. Abstract
QwenLong-L1.5 is a set of "long context reasoning + memory management" post-training recipe that the Tongyi Zhiwen team open-sourced in the Qwen-Doc repository. It revolves around three things: complex inference data synthesis for long documents, reinforcement learning stable training methods (AEPO, etc.) for long sequences, and memory management frameworks that still work outside the physical context window, and the corresponding model QwenLong-L1.5-30B-A3B (based on Qwen3-30B-A3B-Thinking) was released.
2. Core features
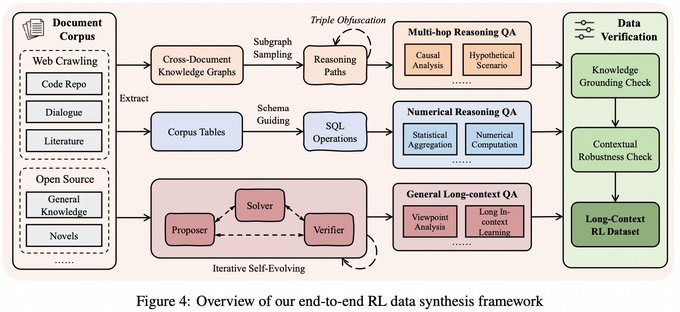
- Long context inference data synthesis: Through the method of "atomic fact decomposition + verifiable combination", long document reasoning samples that require multi-hop evidence concatenation are generated, not just simple retrieval tasks.
- Long-sequence RL stable training: Strategies such as task balanced sampling are introduced, and AEPO (Adaptive Entropy-Controlled Policy Optimization) is proposed to regulate the training process with entropy-related mechanisms to alleviate the common instability problems of long-context RL.
- Memory management and ultra-long input: Perform a single inference in the model's physical window (256K window mentioned in the example), and combine it with iterative memory updates to expand the processing range to millions or even longer input streams (the paper description covers 1M-4M token-level tasks).
- Open source reproducible: Provide model weights and supporting dependency descriptions to facilitate researchers to reproduce experiments or do secondary development (the model license is Apache-2.0, the specific repository/model card shall prevail).
3. Installation
1. Create an environment (example): conda create -n qwenlongl1_5 python==3.10 && conda activate qwenlongl1_5
2. Install dependencies: Execute pip3 install -r requirements.txt in the corresponding directory (subject to the actual file).
3. Install the RL training library: Install the verl according to the project's recommendation (example is cloning volcengine/verl and cutting to the pip3 install -e . after v0.4).
- Inference side dependencies: Use Transformers to load models and tokenizers (you can also adjust device_map, dtype, etc. according to your inference framework).
4. Typical use cases
- Long document Q&A (DocQA): Cross-paragraph multi-hop reasoning and answer attribution on technical documents, compliance materials, and papers/reports.
- "Read and answer" ultra-long materials: When the input scale exceeds a single context, the memory agent process is used for segmented reading, memory update and final comprehensive answer.
- Enterprise knowledge analysis: Structural key point extraction, conflict detection and consistency check on annual reports, bidding documents, and demand documents.
- Research reproduction and training practice: used to explore the sampling strategy, reward design, training stability and evaluation system of long-context RL.
5. Ecology and competing products
- Same repository ecosystem: Qwen-Doc also includes QwenLong-L1 (earlier long-context RL exploration) and SPELL (self-game RL framework), which is suitable for comparative experiments on the "data-training-agent" full link.
- Relationship with RAG/compression scheme: RAG is more "retrieval hit rate and context splicing", while QwenLong-L1.5 emphasizes "reasoning ability and memory process after reading long text"; The two can be combined in engineering (retrieval first, then long reasoning/memory summary).
- Competitive product reference: closed-source long-context models and various open-source long-context fine-tuning/sparse attention/compression methods have their own trade-offs; The difference of QwenLong-L1.5 is that "long inference data synthesis + long sequence RL stable training + memory agent" is given as a set of post-training formulas.
6. Limitations and precautions
- Computing power and latency: Long sequence inference and RL training are more memory/throughput, especially in 256K-level windows or memory proxy loops, the cost will increase significantly.
- Memory is not "absolutely correct": memory update may introduce omissions and deviations, and it is recommended to retain evidence traceability and manual review mechanisms in key scenarios.
- Training reproduction threshold: RL's rewards, sampling, and superparameters are sensitive to results. Different clusters/inference backends can also affect stability.
- Evaluate extrapolation risks: Benchmark improvement does not mean that all real document tasks are improved, and domain data regression and security assessment should be done before implementation.
7. Project address
https://github.com/Tongyi-Zhiwen/Qwen-Doc/tree/main/QwenLong-L1.5
8. Frequently asked questions
Q: What problem does QwenLong-L1.5 solve?
A: Mainly for long document tasks of "cross-chapter, multi-evidence, multi-hop reasoning", the goal is to enable the model to not only retrieve fragments, but also complete chain reasoning and consistency judgment in a long range.
Q: What is the AEPO of QwenLong-L1.5 and how does it relate to common PPOs?
A: AEPO is one of the strategy optimization methods designed for long-context training stability, which regulates the exploration and update intensity through entropy-related mechanisms. It belongs to the same strategy optimization paradigm as PPO, but the implementation details and stabilization methods are different (subject to the paper and code implementation).
Q: How long does the QwenLong-L1.5-30B-A3B need to use the context window?
A: The model works in a combination of "physical window + memory mechanism"; The example material mentions doing a single inference in a 256K window and can be extended to longer inputs with a memory proxy. The actual available length depends on the inference framework, memory, and configuration.
Q: I just want to do reasoning, not training, how can I get started with QwenLong-L1.5 the fastest?
A: Directly use Transformers to load weights and tokenizers from the model warehouse, and prepare long text and question prompts. To reproduce the memory proxy process, refer to the project supporting script and paper description.
Q: Should I choose between QwenLong-L1.5 and RAG?
A: Not necessarily. RAG solves the problem of "finding", and QwenLong-L1.5 emphasizes "reading and understanding, pushing far, and remembering"; A common combination in engineering practice is "retrieval narrowing + long reasoning/memory summarization to complete complex questions and answers".