I. Zusammenfassung
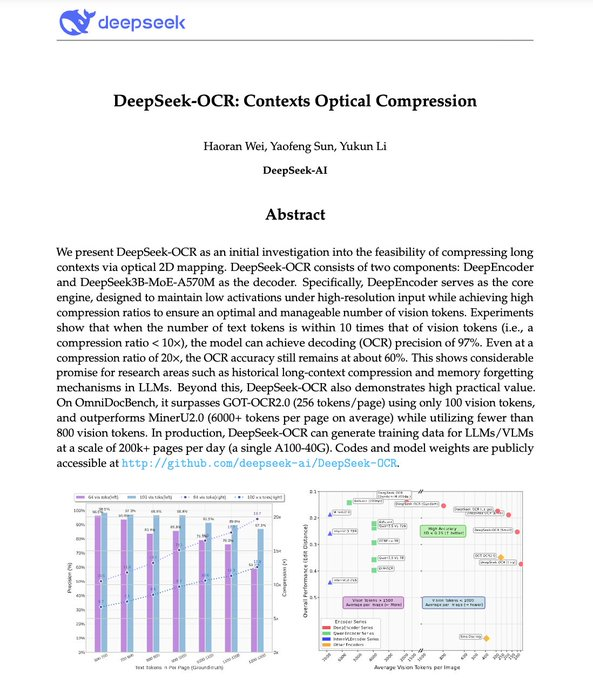
DeepSeek-OCR ist DeepSeeks Open-Source-Modell zur „kontextuellen optischen Komprimierung“. Es kodiert Dokumenttext in visuelle Token und dekodiert diese anschließend wieder in Text. Ziel ist es, die Kosten für kontextuelle Token von LLM deutlich zu senken und gleichzeitig die Erkennungsgenauigkeit beizubehalten. Community- und Medienberichten zufolge erreicht es bei etwa 10-facher Komprimierung eine Dekodierungsgenauigkeit von ca. 97 % und bei 20-facher Komprimierung eine nutzbare Genauigkeit von ca. 60 % . Das Modell bietet mehrere Auflösungen und dynamische Zuschneidemodi und eignet sich daher für Hochdurchsatz-Inferenz bei PDFs und Bildern. Die oben genannte Leistung basiert auf offiziellen und Medienberichten, die auf experimentellen Ergebnissen basieren. Die tatsächliche Wirksamkeit muss mit internen Daten überprüft werden.
2. Kernfunktionen
1. Visuelle Textkomprimierung : Ersetzen Sie einfache Texttoken durch visuelle Kodierungen, wodurch die Kontextlänge und die Inferenzkosten erheblich reduziert werden.
2. Modi mit mehreren Auflösungen : Winzig/Klein/Basis/Groß (64/100/256/400 visuelle Token) und dynamische Auflösung („Gundam“-Lösung).
3. Flexibler Argumentationspfad : Bietet sowohl vLLM- als auch Transformers-Argumentationsskripte und unterstützt die Stapelverarbeitung von Bildern und PDFs.
4. Verständnis der Dokumentstruktur : Beispiele für Markdown-Konvertierung und strukturierte Extraktionsanweisungen für Layout/Tabelle/Diagramm.
5. Open Source und reproduzierbar : MIT-Lizenz, das Repository enthält Installations-, Konfigurations- und Visualisierungsbeispiele.
3. Installation
1. Klonen Sie das Repository: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git und geben Sie das Verzeichnis ein.
2. Umgebung erstellen: conda create -n deepseek-ocr python=3.12.9 -y && conda activate deepseek-ocr.
3. Abhängigkeitsinstallation: Installieren Sie die in der README-Datei angegebene CUDA/PyTorch-Version, pip install -r requirements.txt, und installieren Sie die passende vLLM/Flash-Attention.
4. Gewichtung und Inferenz: Ziehen Sie deepseek-ai/DeepSeek-OCR aus Hugging Face und führen Sie Bild-/PDF-OCR und Auswertung gemäß dem im Repository bereitgestellten vLLM- oder Transformers-Skript aus.
Typische Anwendungsfälle
1. OCR für lange Dokumente → Markdown : Konvertieren Sie Journale/Berichte schnell in bearbeitbaren Text und reduzieren Sie so die manuelle Bereinigung.
2. Enterprise-Archivierung und -Abruf : Verwenden Sie visuelle Token, um den Kontext in RAG (Retrieval Enhanced Generation) zu komprimieren und so den Umfang des Abrufs und der Frage-Beantwortung zu erweitern.
3. Strukturierung von Rechnungen/Formularen : Positionieren und analysieren Sie das Layout/Formular/Diagramm, um halbstrukturierte Ergebnisse zu erzielen.
4. Batch-PDF-Durchsatz : Verarbeiten Sie mehrere PDF-Seiten gleichzeitig in einer einzigen Kartenumgebung, wodurch Rechenleistung und Kostendruck reduziert werden.
5. Ökosystem und Wettbewerbsprodukte
1. Ökosystem : Nativ kompatibel mit Hugging Face; Skripte decken vLLM/Transformers ab; README bietet PDF/Bilder und Beispiele für die Stapelauswertung.
2. Vergleich mit Konkurrenzprodukten : Community-Berichte zeigen, dass dieses Produkt GOT-OCR2.0 und MinerU in Bezug auf Komprimierung/Genauigkeit und Token-Effizienz übertrifft und den Token-Verbrauch deutlich reduziert. Unterschiedliche Benchmarks und Datenverteilungen wirken sich jedoch erheblich auf die Ergebnisse aus, sodass erneute Tests mit denselben Daten und Bewertungsverfahren erforderlich sind.
VI. Einschränkungen und Vorsichtsmaßnahmen
1. Übertragbarkeit der Indikatoren : 10×≈97 % und 20×≈60 % sind offizielle/mediale experimentelle Werte. Die Übertragung auf rechtliche, medizinische und andere Szenarien erfordert eine separate Überprüfung.
2. Abhängigkeit von der Bildqualität : Niedrig aufgelöste/komplexe Layouts beeinträchtigen die Dekodierungsqualität. Es wird empfohlen, Layoutanalyse und Resampling zu kombinieren.
3. Rechenleistung und Umgebung : Obwohl es weniger Token gibt, erfordert die visuelle Codierung immer noch GPU-Speicher und entsprechende CUDA-/Treiberversionen.
4. Compliance und Datenschutz : Bei der Verarbeitung von Dokumenten mit vertraulichen Informationen sollte der lokalen Bereitstellung Vorrang eingeräumt und die Richtlinien zur Datenkonformität befolgt werden.
7. Projektadresse
https://github.com/deepseek-ai/DeepSeek-OCR
8. Häufig gestellte Fragen
F: Wie verstehen Sie die „10-fache Komprimierung ≈ 97 % Dekodierungsgenauigkeit“ und „20-fach ≈ 60 %“ von DeepSeek-OCR?
A: Dies bezieht sich auf die Genauigkeit der Dekodierung in Text, wenn das Verhältnis von visuellen Token zu Texttoken etwa 1:10/1:20 erreicht. Damit Labore und Medien Ergebnisse veröffentlichen können, müssen diese anhand ihrer eigenen Daten überprüft werden.
F: Was sind die Unterschiede bei der Token-Nutzung und dem Durchsatz im Vergleich zu GOT-OCR2.0 und MinerU?
A: Die offizielle README-Datei und Medienberichte behaupten, dass es Vorteile bei der Komprimierungsrate und Token-Effizienz bietet. Unterschiedliche Benchmarks, Hardware und Parallelitätsstrategien beeinflussen den Vergleich jedoch. Wir empfehlen die Verwendung eines einheitlichen Evaluierungsskripts und die erneute Prüfung der Daten.
F: Welcher Pfad wird für die Bereitstellung und Inferenz empfohlen (vLLM vs. Transformers)?
A: vLLM eignet sich für Szenarien mit hohem Durchsatz und gleichzeitiger Nutzung; Transformers erleichtert die sekundäre Entwicklung und Integration. Skripte für beide sind im Repository verfügbar, sodass Sie je nach Szenario auswählen können.
F: Wann wird die dynamische Auflösung (Gundam) aktiviert?
A: Wenn eine Seite eine Mischung aus kleinem Text und großen Symbolen enthält, können durch dynamisches Zuschneiden + hochauflösende Hauptansicht sowohl Details als auch das Gesamtlayout berücksichtigt werden.



