I. Résumé
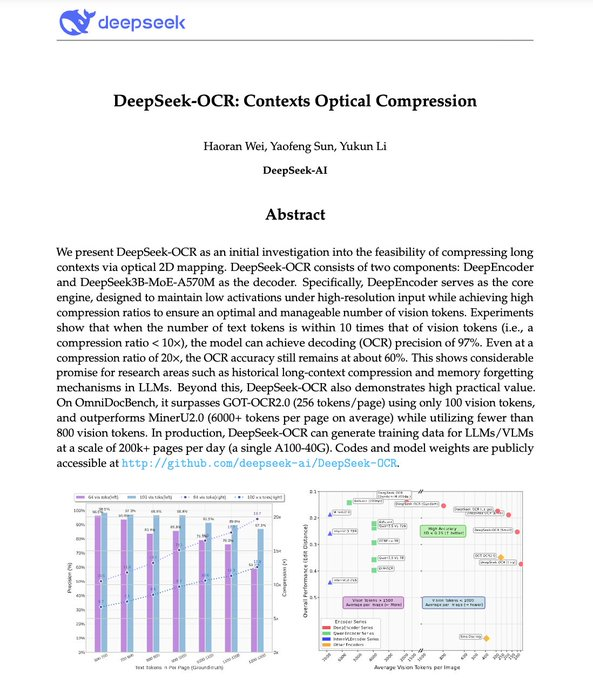
DeepSeek-OCR est le modèle open source de « compression optique contextuelle » de DeepSeek. Il encode le texte des documents en jetons visuels , puis les décode à nouveau en texte. Son objectif est de réduire significativement le coût des jetons contextuels de LLM tout en maintenant la précision de la reconnaissance. Des rapports de la communauté et des médias indiquent qu'il atteint une précision de décodage d'environ 97 % avec une compression d'environ 10x , et maintient une précision utilisable d'environ 60 % avec une compression de 20x . Le modèle offre plusieurs résolutions et modes de recadrage dynamiques, ce qui le rend idéal pour l'inférence haut débit sur les PDF et les images. Les performances ci-dessus sont basées sur des rapports officiels et des rapports médiatiques basés sur des résultats expérimentaux. L'efficacité réelle doit être vérifiée avec des données internes.
2. Fonctionnalités principales
1. Compression de texte visuel : remplacez les jetons de texte brut par des encodages visuels, réduisant ainsi considérablement la longueur du contexte et les coûts d'inférence.
2. Modes multi-résolution : Tiny/Small/Base/Large (64/100/256/400 jetons visuels) et résolution dynamique (solution « Gundam »).
3. Chemin de raisonnement flexible : fournit des scripts de raisonnement vLLM et Transformers et prend en charge le traitement par lots d'images et de PDF.
4. Compréhension de la structure du document : exemples de conversion Markdown et instructions d'extraction structurées pour la mise en page/le tableau/le diagramme.
5. Open source et reproductible : licence MIT, le référentiel contient des exemples d'installation, de configuration et de visualisation.
3. Installation
1. Clonez le référentiel : git clone https://github.com/deepseek-ai/DeepSeek-OCR.git et entrez dans le répertoire.
2. Créez l'environnement : conda create -n deepseek-ocr python=3.12.9 -y && conda activate deepseek-ocr.
3. Installation des dépendances : installez la version CUDA/PyTorch spécifiée dans le fichier README, pip install -r requirements.txt, et installez le vLLM/Flash-Attention correspondant.
4. Pondération et inférence : extrayez deepseek-ai/DeepSeek-OCR de Hugging Face et exécutez l'OCR et l'évaluation de l'image/PDF conformément au script vLLM ou Transformers fourni dans le référentiel.
Cas d'utilisation typiques
1. Document long OCR → Markdown : convertissez rapidement les journaux/rapports en texte modifiable pour réduire le nettoyage manuel.
2. Archivage et récupération d'entreprise : utilisez des jetons visuels pour compresser le contexte dans RAG (Retrieval Enhanced Generation) afin d'étendre la portée de la récupération et de la réponse aux questions.
3. Structuration des factures/formulaires : Positionner et analyser la mise en page/formulaire/schéma pour produire des résultats semi-structurés.
4. Débit PDF par lots : traitez simultanément plusieurs pages PDF dans un seul environnement de carte, réduisant ainsi la puissance de calcul et la pression sur les coûts.
5. Écosystème et produits compétitifs
1. Écosystème : nativement compatible avec Hugging Face ; les scripts couvrent vLLM/Transformers ; README fournit des PDF/images et des exemples d'évaluation par lots.
2. Comparaison avec les produits concurrents : Les rapports de la communauté indiquent que ce produit surpasse GOT-OCR2.0 et MinerU en termes d'efficacité de compression et de précision des jetons, et réduit considérablement leur utilisation. Cependant, des benchmarks et des distributions de données différents impactent considérablement les résultats, nécessitant de nouveaux tests avec les mêmes données et les mêmes procédures d'évaluation.
VI. Limitations et précautions
1. Transférabilité des indicateurs : 10 × ≈ 97 % et 20 × ≈ 60 % sont des valeurs expérimentales officielles/médiatiques. Leur transposition aux contextes juridique, médical et autres nécessite une vérification distincte.
2. Dépendance à la qualité de l'image : Les mises en page basse définition/complexes affectent la qualité du décodage. Il est recommandé de combiner l'analyse de la mise en page et le rééchantillonnage.
3. Puissance de calcul et environnement : Bien qu'il y ait moins de jetons, le codage visuel nécessite toujours de la mémoire GPU et des versions CUDA/pilotes appropriées.
4. Conformité et confidentialité : lors du traitement de documents contenant des informations sensibles, le déploiement local doit être prioritaire et les politiques de conformité des données doivent être suivies.
7. Adresse du projet
https://github.com/deepseek-ai/DeepSeek-OCR
8. Questions fréquemment posées
Q : Comment comprenez-vous les expressions « compression 10× ≈ 97 % de précision de décodage » et « 20× ≈ 60 % » de DeepSeek-OCR ?
R : Il s’agit du niveau de précision du décodage en texte lorsque le rapport entre les symboles visuels et les symboles textuels atteint environ 1:10/1:20. Pour que les laboratoires et les médias puissent divulguer leurs résultats, ceux-ci doivent être vérifiés sur la base de leurs propres données.
Q : Quelles sont les différences dans l’utilisation des jetons et le débit par rapport à GOT-OCR2.0 et MinerU ?
R : Le fichier README officiel et les articles de presse affirment que ce protocole présente des avantages en termes de taux de compression et d'efficacité des jetons. Cependant, des différences de benchmarks, de matériel et de stratégies de concurrence peuvent influencer la comparaison. Nous vous recommandons d'utiliser un script d'évaluation unifié et de retester les données.
Q : Quel est le chemin recommandé pour le déploiement et l’inférence (vLLM vs Transformers) ?
R : vLLM est adapté aux scénarios à haut débit et à forte concurrence ; Transformers facilite le développement secondaire et l'intégration. Des scripts pour les deux sont disponibles dans le dépôt, vous permettant de choisir en fonction de votre scénario.
Q : Quand la résolution dynamique (Gundam) sera-t-elle activée ?
R : Lorsqu'une page contient un mélange de petit texte et de grandes icônes, le recadrage dynamique + la vue principale haute résolution peuvent prendre en compte à la fois les détails et la mise en page générale.



