一、摘要
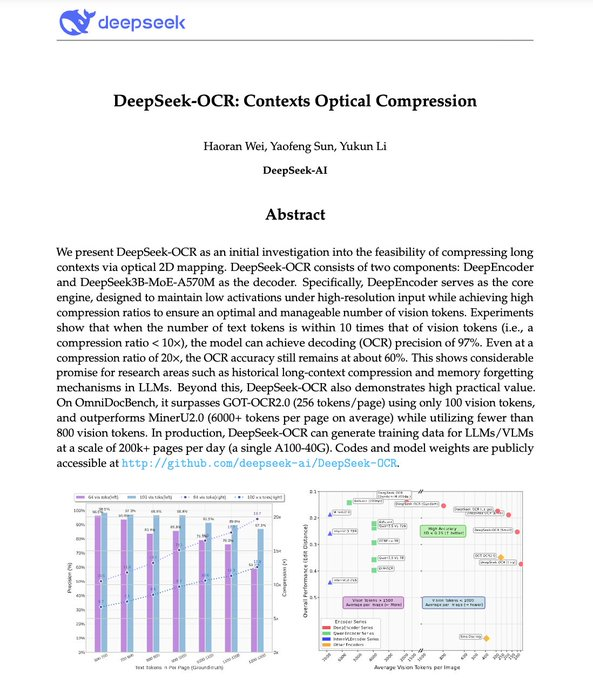
DeepSeek-OCR 是 DeepSeek 开源的“上下文光学压缩”模型,将文档文本编码为视觉 token后再解码为文字,目标是在保持识别准确度的同时显著降低 LLM 的上下文 token 成本。社区与媒体报道显示:在约 10× 压缩下可达约 97% 解码精度,20× 时仍有约 60% 可用准确度;模型提供多分辨率与动态裁切模式,适配 PDF/图片的高吞吐推理。上述性能为官方与媒体给出的实验结果,落地效果需以自有数据验证。
二、核心特性
1、视觉-文本压缩:以视觉编码替代纯文本 token,显著减少上下文长度与推理费用。
2、多分辨率模式:Tiny/Small/Base/Large(64/100/256/400 视觉 token)与动态分辨率(“Gundam”方案)。
3、推理路径灵活:同时提供 vLLM 与 Transformers 推理脚本,支持图片与 PDF 批处理。
4、文档结构理解:面向版面/表格/图示的转 Markdown 与结构化抽取指令示例。
5、开源可复现:MIT 许可,仓库含安装、配置与可视化示例。
三、安装
1、克隆仓库:git clone https://github.com/deepseek-ai/DeepSeek-OCR.git 并进入目录。
2、创建环境:conda create -n deepseek-ocr python=3.12.9 -y && conda activate deepseek-ocr。
3、依赖安装:按 README 指定的 CUDA/PyTorch 版本安装,pip install -r requirements.txt,并安装匹配的 vLLM/Flash-Attention。
4、权重与推理:在 Hugging Face 拉取 deepseek-ai/DeepSeek-OCR,按仓库提供的 vLLM 或 Transformers 脚本运行图片/PDF OCR 与评测。
四、典型用例
1、长文档 OCR→Markdown:将期刊/报告快速转可编辑文本,减少人工清洗。
2、企业归档与检索:在 RAG(检索增强生成)中以视觉 token 压缩上下文,扩展检索与问答范围。
3、票据/表格结构化:对版面/表格/图示进行定位解析,产出半结构化结果。
4、批量 PDF 吞吐:在单卡环境下并发处理多页 PDF,降低算力与成本压力。
五、生态与竞品
1、生态:原生适配 Hugging Face;脚本覆盖 vLLM/Transformers;README 提供 PDF/图片与批量评测示例。
2、竞品对比:社区报道称在压缩/准确度-token 效率上优于 GOT-OCR2.0 与 MinerU,并显著降低 token 使用量;但不同基准与数据分布对结果影响较大,需以相同数据与评测规程复测。
六、局限与注意事项
1、指标可迁移性:10×≈97%、20×≈60% 为官方/媒体实验数值,迁移到法律、医疗等场景需单独校验。
2、图像质量依赖:低清晰度/复杂版面会影响解码质量,建议结合版面分析与重采样。
3、算力与环境:尽管 token 更少,视觉编码仍需 GPU 显存与合适的 CUDA/驱动版本。
4、合规与隐私:处理含敏感信息的文档时,应优先本地化部署并遵循数据合规政策。
七、项目地址
https://github.com/deepseek-ai/DeepSeek-OCR
八、常见问题
Q: DeepSeek-OCR 的“10× 压缩≈97% 解码精度”与“20×≈60%”如何理解?
A: 指在视觉 token 与文本 token 的比例达到约 1:10/1:20 时,解码回文字的准确度水平;为实验室与媒体披露结果,需在自有数据上复核。
Q: 与 GOT-OCR2.0、MinerU 在 token 使用与吞吐上的差异?
A: 官方 README 与媒体称其在压缩率与 token 效率上具优势;但基准、硬件与并发策略不同会影响对比,建议统一评测脚本与数据复测。
Q: 部署与推理推荐路径(vLLM vs Transformers)?
A: vLLM 适合高吞吐/并发场景;Transformers 易于二次开发与集成。两者脚本均在仓库提供,可按场景选择。
Q: 动态分辨率(Gundam)何时开启?
A: 当页面含细小文本与大幅图示混排时,动态裁切+高分辨率主视图可兼顾细节与整体版面。



