I. 要約
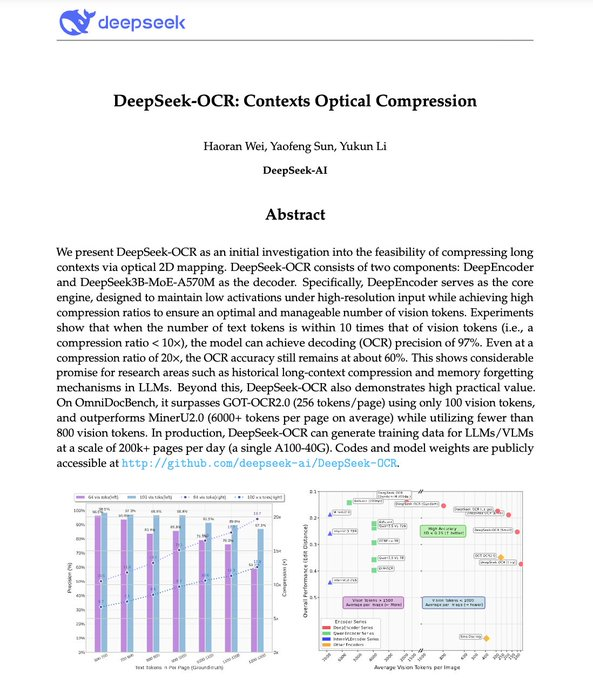
DeepSeek-OCRは、DeepSeekのオープンソース「コンテキスト光学圧縮」モデルです。文書テキストを視覚トークンにエンコードし、それをテキストにデコードします。認識精度を維持しながら、LLMのコンテキストトークンコストを大幅に削減することを目指しています。コミュニティやメディアの報告によると、約10倍の圧縮で約97%のデコード精度を達成し、 20倍の圧縮でも約60%の実用精度を維持しています。このモデルは複数の解像度と動的なクロッピングモードを備えており、PDFや画像に対する高スループット推論に適しています。上記のパフォーマンスは、公式レポートおよびメディアレポートの実験結果に基づいています。実際の有効性については、社内データによる検証が必要です。
2. コア機能
1.ビジュアルテキスト圧縮: プレーンテキスト トークンをビジュアル エンコーディングに置き換えて、コンテキストの長さと推論コストを大幅に削減します。
2.マルチ解像度モード: Tiny/Small/Base/Large (64/100/256/400 ビジュアル トークン) およびダイナミック解像度 (「ガンダム」ソリューション)。
3.柔軟な推論パス: vLLM と Transformers の両方の推論スクリプトを提供し、画像と PDF のバッチ処理をサポートします。
4.文書構造の理解:レイアウト/表/図のMarkdown変換と構造化抽出指示の例。
5.オープンソースで再現可能: MIT ライセンス、リポジトリにはインストール、構成、視覚化の例が含まれています。
3. インストール
1. リポジトリ:git clone https://github.com/deepseek-ai/DeepSeek-OCR.git をクローンし、ディレクトリに入ります。
2. 環境を作成します: conda create -n deepseek-ocr python=3.12.9 -y && conda activate deepseek-ocr。
3. 依存関係のインストール: README、pip install -r requirements.txt に指定されている CUDA/PyTorch バージョンをインストールし、一致する vLLM/Flash-Attention をインストールします。
4. 重み付けと推論: Hugging Face から deepseek-ai/DeepSeek-OCR を取得し、リポジトリで提供されている vLLM または Transformers スクリプトに従って画像/PDF OCR と評価を実行します。
典型的な使用例
1.長い文書の OCR → Markdown : ジャーナル/レポートを編集可能なテキストにすばやく変換して、手動でのクリーニングを減らします。
2.エンタープライズ アーカイブと検索: ビジュアル トークンを使用して RAG (検索拡張生成) のコンテキストを圧縮し、検索と質問応答の範囲を拡大します。
3.請求書/フォームの構造化: レイアウト/フォーム/図を配置して分析し、半構造化された結果を生成します。
4.バッチ PDF スループット: 単一のカード環境で複数の PDF ページを同時に処理し、計算能力とコストの圧力を軽減します。
5. エコシステムと競合製品
1.エコシステム: Hugging Face とネイティブに互換性があり、スクリプトは vLLM/Transformers をカバーし、README には PDF/画像とバッチ評価の例が提供されています。
2.競合製品との比較:コミュニティレポートによると、本製品は圧縮率/精度とトークン効率の点でGOT-OCR2.0およびMinerUを上回り、トークン使用量を大幅に削減します。ただし、ベンチマークとデータ分布の違いが結果に大きな影響を与えるため、同じデータと評価手順を用いて再テストを行う必要があります。
VI. 制限事項と注意事項
1.指標の転用可能性:10×≈97%および20×≈60%は公式/メディア実験値です。法務、医療、その他のシナリオへの転用には別途検証が必要です。
2.画質依存性:低解像度または複雑なレイアウトはデコード品質に影響を与えます。レイアウト解析とリサンプリングを組み合わせることをお勧めします。
3.計算能力と環境: トークンは少なくなりますが、ビジュアル コーディングには GPU メモリと適切な CUDA/ドライバー バージョンが必要です。
4.コンプライアンスとプライバシー: 機密情報を含むドキュメントを処理する場合は、ローカル展開を優先し、データ コンプライアンス ポリシーに従う必要があります。
7. プロジェクト住所
https://github.com/deepseek-ai/DeepSeek-OCR
8. よくある質問
Q: DeepSeek-OCR の「10 倍の圧縮 ≒ 97% のデコード精度」と「20 倍 ≒ 60%」をどのように理解すればよいでしょうか?
A: これは、視覚トークンとテキストトークンの比率が約1:10/1:20に達したときに、テキストへのデコード精度がどの程度になるかを指します。研究機関やメディアが結果を公表するには、自らのデータに基づいて検証する必要があります。
Q: GOT-OCR2.0 や MinerU と比較した場合のトークン使用量とスループットの違いは何ですか?
A: 公式READMEおよびメディアレポートでは、圧縮率とトークン効率の点で優位性があるとされていますが、ベンチマーク、ハードウェア、同時実行戦略の違いにより、比較は異なります。統一された評価スクリプトを使用し、データを再テストすることをお勧めします。
Q: デプロイメントと推論 (vLLM と Transformers) に推奨されるパスは何ですか?
A: vLLMは高スループット/同時実行シナリオに適しており、Transformersは二次開発と統合を容易にします。両方のスクリプトがリポジトリで入手可能ですので、シナリオに応じてどちらかを選択できます。
Q:ダイナミックレゾリューション(ガンダム)はいつ有効になりますか?
A: ページに小さなテキストと大きなアイコンが混在している場合、動的クロッピング + 高解像度のメインビューを使用すると、詳細と全体的なレイアウトの両方を考慮できます。



