I. Zusammenfassung
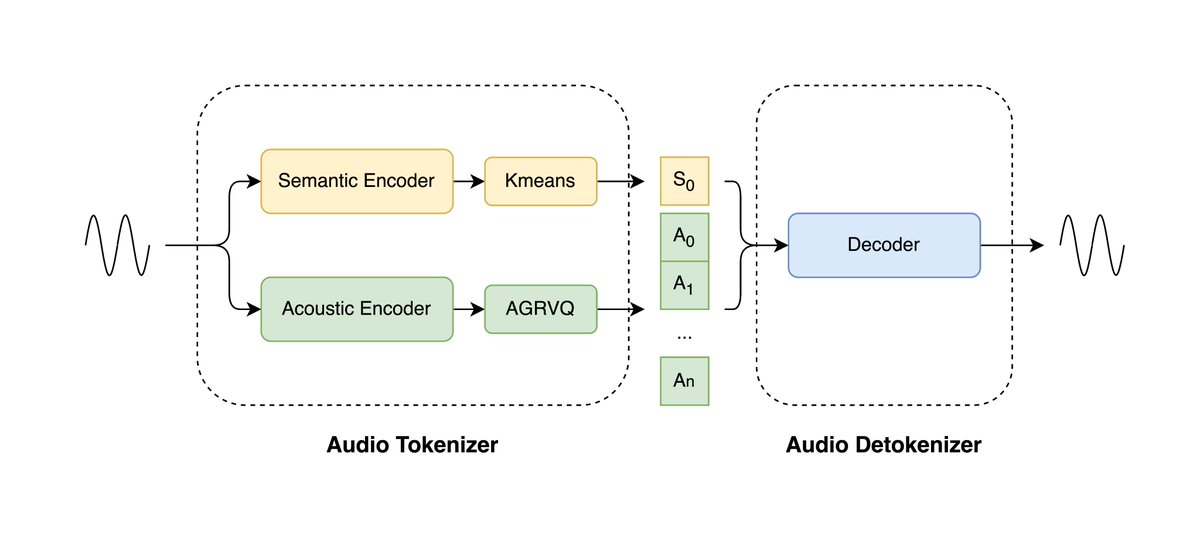
LongCat-Audio-Codec ist eine Open-Source-Audio-Codec-Lösung, die vom Meituan LongCat-Team entwickelt und für das Speech Large Scale Model (LLM) optimiert wurde. Das Projekt nutzt eine Dual-Token-Architektur, um semantische und akustische Informationen gleichzeitig zu modellieren und so Sprachverständlichkeit und -qualität bei einer ultraniedrigen Bitrate von nur 0,43 kbps zu gewährleisten. Der Echtzeit-Streaming-Decoder hält Latenzen im Hunderter-Millisekunden-Bereich aufrecht und unterstützt Sprachinteraktion sowie eingebettete Bereitstellung. Das integrierte Super-Resolution-Modul des Decoders verbessert die Klangqualität zusätzlich, ohne dass zusätzliche Modelle erforderlich sind, und reduziert so den Ressourcenaufwand von End-to-End-Sprachsystemen erheblich.
2. Kernfunktionen
1. Dual-Token-Parallelcodierung : Extrahiert gleichzeitig semantische und akustische Token und erreicht so eine effiziente Merkmalsmodellierung bei einer niedrigen Bildrate von 16,7 Hz (60 ms).
2. Extrem niedrige Bitrate und hochpräzise Rekonstruktion : Behält die hohe Verständlichkeit bei 0,43 kbps bei und verbessert so die Bandbreitennutzung erheblich.
3. Echtzeit-Dekodierung mit geringer Latenz : Durch die Verwendung einer Streaming-Architektur wird die Gesamtlatenz bei Hunderten von Millisekunden gehalten, wodurch die Anforderungen der Sprachgenerierung und -interaktion in Echtzeit erfüllt werden.
4. Dekodierungsseitige Super-Resolution-Verbesserung : Ein integriertes Super-Resolution-Modul verbessert die Klangqualitätsdetails, ohne dass ein externes Modell erforderlich ist.
5. Leichtgewichtige und mobile Optimierung : Architekturoptimierung zur Behebung der Rechenleistungsbeschränkungen eingebetteter und mobiler Geräte.
3. Installation
1. Repository klonen: git clone https://github.com/meituan-longcat/LongCat-Audio-Codec
2. Installationsabhängigkeit: pip install -r requirements.txt
3. Laden Sie das Modell: Sie können die entsprechenden Gewichte von meituan-longcat/LongCat-Audio-Codec über Hugging Face herunterladen.
- Führen Sie das Beispiel aus: Führen Sie das Inferenzskript im Repository aus, um die Kodierungs- und Dekodierungsüberprüfung durchzuführen.
Typische Anwendungsfälle
- Front-End-Komprimierung großer Sprachmodelle: Reduzierung der Eingangsbandbreite bei gleichzeitiger Beibehaltung der Verständlichkeit.
- Echtzeit-Sprachinteraktionssystem: Erreichen Sie eine Übertragung mit geringer Latenz in Konversations-KI oder Sprachassistenten.
- Sprachsynthese auf Edge- und Mobilgeräten: Generieren oder dekodieren Sie Sprache lokal.
- Sprachkommunikation über große Entfernungen: Sorgen Sie für eine klare Sprachübertragungsqualität in Umgebungen mit extrem geringer Bandbreite.
5. Ökosystem und Wettbewerbsprodukte
1. Ökosystemintegration : LongCat-Audio-Codec ist Teil des Ökosystems der Meituan LongCat-Serie und arbeitet mit Modellen wie LongCat-Flash zusammen, um die Sprachgenerierung und das Sprachverständnis zu optimieren.
2. Vergleich mit Wettbewerbern : Im Vergleich zu neuronalen Codec-Lösungen wie SemantiCodec, UniCodec und LMCodec erreicht LongCat-Audio-Codec niedrigere Bitraten und eine stärkere Echtzeitleistung im Sprachbereich.
3. Bedeutung für die Branche : Senkt die Einsatzschwelle von Voice-LLM und bietet Infrastrukturunterstützung für mobile KI-Assistenten und Sprachdienste.
VI. Einschränkungen und Vorsichtsmaßnahmen
- Selbst bei extrem niedrigen Bitraten kann die Tonqualität unter Detailverlusten leiden.
- Die Streaming-Dekodierung stellt hohe Anforderungen an die Echtzeitleistung der Hardware.
- Bei verschiedenen Modellversionen kann es zu Kompromissen zwischen Latenz und Klangqualität kommen.
- Die Integration eines Superauflösungsmoduls erhöht den Rechenaufwand.
7. Projektadresse
https://github.com/meituan-longcat/LongCat-Audio-Codec
8. Häufig gestellte Fragen
F: Unterstützt LongCat-Audio-Codec die Offline-Bereitstellung?
A: Es kann vollständig offline ausgeführt werden, aber Sie müssen die entsprechenden Modellgewichte und die abhängige Umgebung vorbereiten.
F: Wie kann ich diesen Codec auf Mobilgeräten integrieren?
A: Es kann durch quantisierte Modelle oder leichtgewichtige Inferenz-Frameworks auf mobile oder eingebettete Plattformen portiert werden.
F: Kann es für nicht-sprachliches Audio verwendet werden?
A: Die aktuelle Version ist hauptsächlich für Sprachaufgaben optimiert und andere Audiotypen erfordern zusätzliches Training.



