I. Résumé
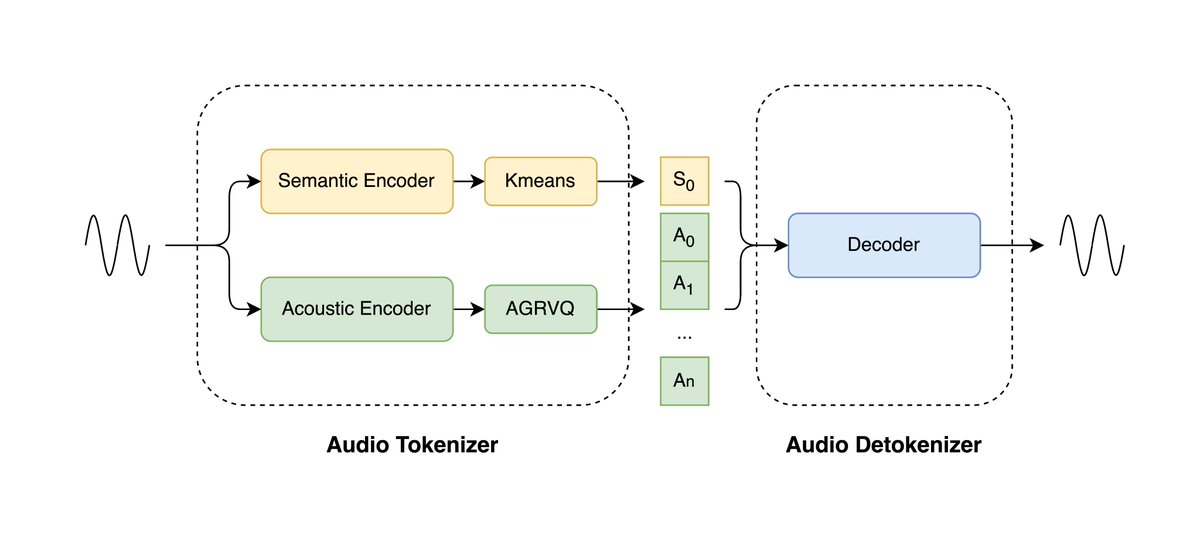
LongCat-Audio-Codec est une solution de codec audio open source développée par l'équipe Meituan LongCat et optimisée pour le modèle de parole à grande échelle (LLM). Ce projet utilise une architecture à double jeton pour modéliser simultanément les informations sémantiques et acoustiques, préservant l'intelligibilité et la qualité de la parole à un débit binaire ultra-faible de seulement 0,43 kbit/s. Son décodeur de streaming en temps réel maintient une latence de quelques centaines de millisecondes, prenant en charge l'interaction vocale et le déploiement embarqué. Le module de super-résolution intégré au décodeur améliore encore la qualité sonore sans nécessiter de modèles supplémentaires, réduisant ainsi considérablement la charge de ressources des systèmes vocaux de bout en bout.
2. Fonctionnalités principales
1. Codage parallèle à double jeton : extrait simultanément les jetons sémantiques et acoustiques, permettant une modélisation efficace des fonctionnalités à une faible fréquence d'images de 16,7 Hz (60 ms).
2. Débit binaire extrêmement faible et reconstruction haute fidélité : maintient une intelligibilité élevée à 0,43 kbps, améliorant considérablement l'utilisation de la bande passante.
3. Décodage à faible latence en temps réel : grâce à une architecture de streaming, la latence globale est maintenue à quelques centaines de millisecondes, répondant ainsi aux besoins de génération et d'interaction vocales en temps réel.
4. Amélioration de la super-résolution côté décodage : un module de super-résolution intégré améliore les détails de la qualité sonore sans avoir besoin d'un modèle externe.
5. Optimisation légère et mobile : Optimisation architecturale pour répondre aux limitations de puissance de calcul des appareils embarqués et mobiles.
3. Installation
1. Cloner le dépôt : git clone https://github.com/meituan-longcat/LongCat-Audio-Codec
2. Dépendance d'installation : pip install -r requirements.txt
3. Chargez le modèle : vous pouvez télécharger les poids correspondants de meituan-longcat/LongCat-Audio-Codec via Hugging Face.
- Exécutez l'exemple : exécutez le script d'inférence dans le référentiel pour effectuer la vérification de l'encodage et du décodage.
Cas d'utilisation typiques
- Compression frontale de grands modèles de parole : réduction de la bande passante d'entrée tout en maintenant l'intelligibilité.
- Système d'interaction vocale en temps réel : obtenez une transmission à faible latence dans l'IA conversationnelle ou les assistants vocaux.
- Synthèse vocale sur les appareils mobiles et périphériques : générer ou décoder la parole localement.
- Communication vocale longue distance : maintenez une qualité de transmission vocale claire dans des environnements à bande passante extrêmement faible.
5. Écosystème et produits compétitifs
1. Intégration de l'écosystème : LongCat-Audio-Codec fait partie de l'écosystème de la série Meituan LongCat et fonctionne en collaboration avec des modèles tels que LongCat-Flash pour optimiser la génération et la compréhension de la parole.
2. Comparaison avec les concurrents : Comparé aux solutions de codec neuronal telles que SemantiCodec, UniCodec et LMCodec, LongCat-Audio-Codec atteint des débits binaires inférieurs et des performances en temps réel plus élevées dans le domaine vocal.
3. Importance pour l'industrie : abaisse le seuil de déploiement du LLM vocal et fournit un support d'infrastructure pour les assistants IA mobiles et les services vocaux.
VI. Limitations et précautions
- Même à des débits binaires extrêmement faibles, la qualité sonore peut encore souffrir d'une perte de détails.
- Le décodage en continu a des exigences élevées en matière de performances matérielles en temps réel.
- Différentes versions de modèles peuvent présenter un compromis entre la latence et la qualité sonore.
- L’intégration d’un module de super-résolution augmentera la charge de calcul.
7. Adresse du projet
https://github.com/meituan-longcat/LongCat-Audio-Codec
8. Questions fréquemment posées
Q : LongCat-Audio-Codec prend-il en charge le déploiement hors ligne ?
R : Il peut être exécuté entièrement hors ligne, mais vous devez préparer les poids de modèle correspondants et l'environnement dépendant.
Q : Comment intégrer ce codec sur les appareils mobiles ?
R : Il peut être porté sur des plateformes mobiles ou embarquées via des modèles quantifiés ou des cadres d’inférence légers.
Q : Peut-il être utilisé pour l’audio non vocal ?
R : La version actuelle est principalement optimisée pour les tâches vocales, et d’autres types d’audio nécessitent une formation supplémentaire.



