I. Summary
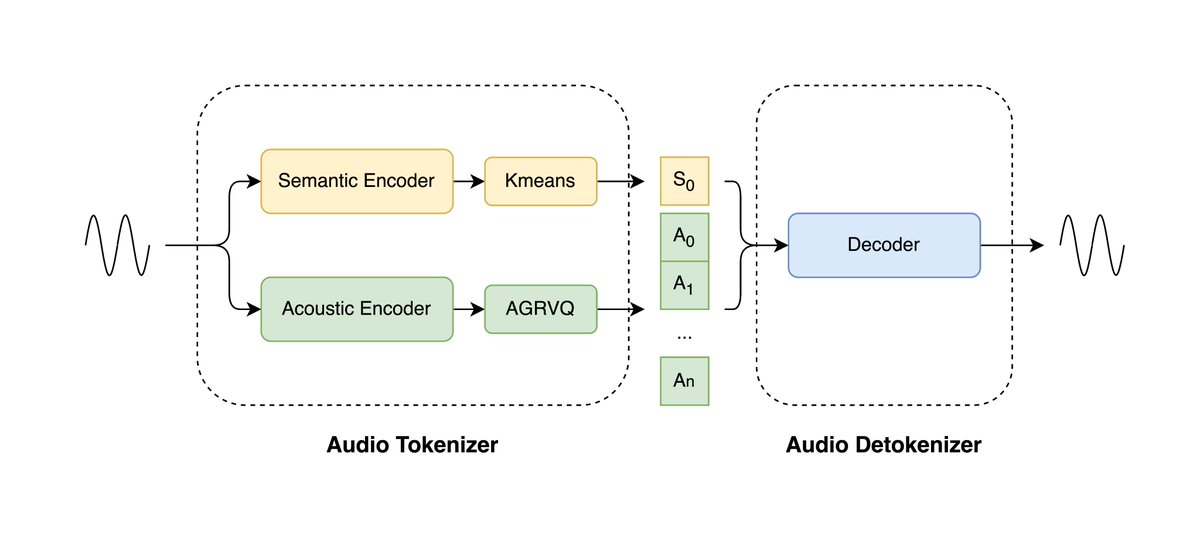
LongCat-Audio-Codec is an open-source audio codec solution developed by the Meituan LongCat team, optimized for the Speech Large Scale Model (LLM). This project utilizes a dual-token architecture to concurrently model semantic and acoustic information, maintaining speech intelligibility and quality at an ultra-low bitrate of just 0.43 kbps. Its real-time streaming decoder maintains latency in the hundreds of milliseconds, supporting voice interaction and embedded deployment. The decoder's integrated super-resolution module further enhances sound quality without requiring additional models, significantly reducing the resource overhead of end-to-end speech systems.
2. Core Features
1. Dual-Token Parallel Encoding : Simultaneously extracts semantic and acoustic tokens, achieving efficient feature modeling at a low frame rate of 16.7 Hz (60 ms).
2. Extremely low bitrate and high-fidelity reconstruction : Maintains high intelligibility at 0.43 kbps, significantly improving bandwidth utilization.
3. Real-time low-latency decoding : Using a streaming architecture, the overall latency is maintained at hundreds of milliseconds, meeting the needs of real-time speech generation and interaction.
4. Decoding-side super-resolution enhancement : An integrated super-resolution module improves sound quality details without the need for an external model.
5. Lightweight and mobile optimization : Architectural optimization to address the computing power limitations of embedded and mobile devices.
3. Installation
1. Clone repository: git clone https://github.com/meituan-longcat/LongCat-Audio-Codec
2. Installation dependency: pip install -r requirements.txt
3. Load the model: You can download the corresponding weights of meituan-longcat/LongCat-Audio-Codec through Hugging Face.
- Run the example: Execute the inference script in the repository to perform encoding and decoding verification.
Typical Use Cases
- Front-end compression of large speech models: reducing input bandwidth while maintaining intelligibility.
- Real-time voice interaction system: Achieve low-latency transmission in conversational AI or voice assistants.
- Speech synthesis on edge and mobile devices: Generate or decode speech locally.
- Long-distance voice communication: Maintain clear voice transmission quality in extremely low-bandwidth environments.
5. Ecosystem and Competitive Products
1. Ecosystem Integration : LongCat-Audio-Codec is part of the Meituan LongCat series ecosystem, and works collaboratively with models such as LongCat-Flash to optimize speech generation and understanding.
2. Comparison with competitors : Compared with neural codec solutions such as SemantiCodec, UniCodec, and LMCodec, LongCat-Audio-Codec achieves lower bit rates and stronger real-time performance in the voice field.
3. Industry significance : Lowers the deployment threshold of voice LLM and provides infrastructure support for mobile AI assistants and voice services.
VI. Limitations and Precautions
- Even at extremely low bit rates, the sound quality may still suffer from loss of details.
- Streaming decoding has high requirements for hardware real-time performance.
- Different model versions may have a trade-off between latency and sound quality.
- Integrating a super-resolution module will increase the computational burden.
7. Project Address
https://github.com/meituan-longcat/LongCat-Audio-Codec
8. Frequently Asked Questions
Q: Does LongCat-Audio-Codec support offline deployment?
A: It can be run completely offline, but you need to prepare the corresponding model weights and dependent environment.
Q: How to integrate this codec on mobile devices?
A: It can be ported to mobile or embedded platforms through quantized models or lightweight inference frameworks.
Q: Can it be used for non-speech audio?
A: The current version is mainly optimized for voice tasks, and other types of audio require additional training.



