一、摘要
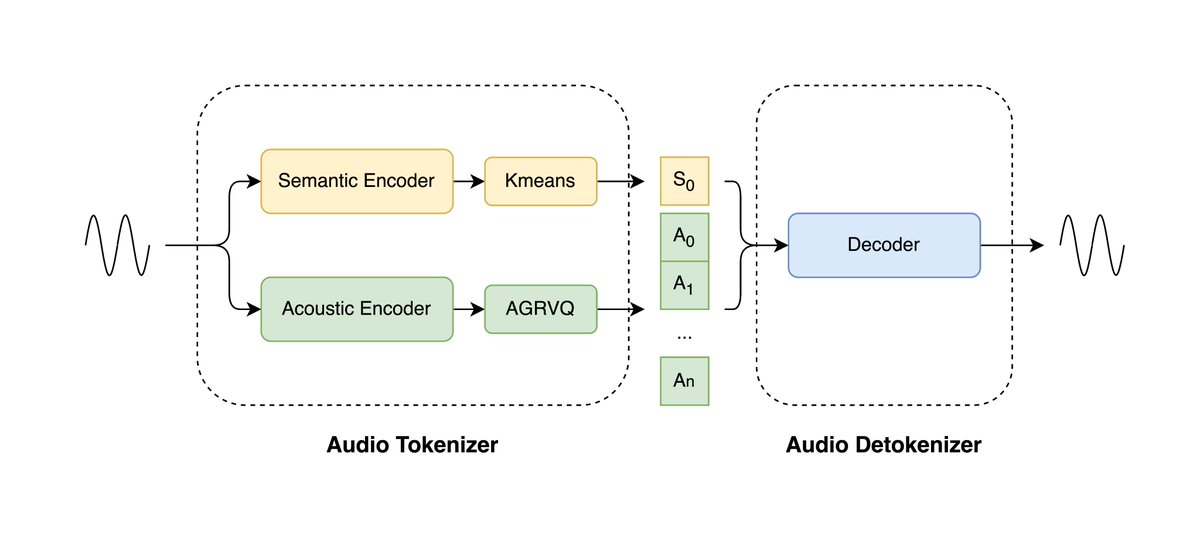
LongCat-Audio-Codec 是美团 LongCat 团队开源的音频编解码方案,专为语音大模型(Speech LLM)优化。项目以“双 Token”架构实现语义与声学信息的并行建模,在仅 0.43 kbps 的超低码率下仍保持语音可懂度与音质。其实时流式解码器延迟控制在百毫秒级,支持语音交互和嵌入式部署。解码器集成的超分辨率模块进一步提升音质,无需额外模型,显著降低端到端语音系统的资源开销。
二、核心特性
1、双 Token 并行编码:同时提取语义与声学 Token,在 16.7Hz(60ms)低帧率下实现高效特征建模。
2、极低码率与高保真重建:在 0.43 kbps 下仍能保持高可懂度,显著提升带宽利用率。
3、实时低延迟解码:采用流式架构,整体延迟维持在百毫秒级,满足实时语音生成与交互需求。
4、解码端超分辨率增强:集成超分辨率模块,无需外部模型即可提升音质细节。
5、轻量化与移动端优化:针对嵌入式和移动设备的算力限制进行架构优化。
三、安装
1、克隆仓库:git clone https://github.com/meituan-longcat/LongCat-Audio-Codec
2、安装依赖:pip install -r requirements.txt
3、加载模型:可通过 Hugging Face 下载 meituan-longcat/LongCat-Audio-Codec 对应权重。
4、运行示例:执行仓库中的推理脚本进行编码与解码验证。
四、典型用例
1、语音大模型前端压缩:减少输入带宽并保持可懂度。
2、实时语音交互系统:在对话式 AI 或语音助手中实现低延迟传输。
3、边缘与移动设备语音合成:在本地生成或解码语音。
4、远程语音通信:在极低带宽环境中保持清晰的语音传输质量。
五、生态与竞品
1、生态集成:LongCat-Audio-Codec 是 Meituan LongCat 系列生态的一部分,与 LongCat-Flash 等模型协同优化语音生成与理解。
2、竞品比较:与 SemantiCodec、UniCodec、LMCodec 等神经编解码方案相比,LongCat-Audio-Codec 在语音领域实现更低码率与更强实时性。
3、行业意义:降低语音 LLM 的部署门槛,为移动端 AI 助手与语音服务提供基础设施支持。
六、局限与注意事项
1、极低码率下音质仍可能出现细节损失。
2、流式解码对硬件实时性要求较高。
3、不同模型版本可能在延迟与音质间存在权衡。
4、集成超分辨率模块会增加一定计算负担。
七、项目地址
https://github.com/meituan-longcat/LongCat-Audio-Codec
八、常见问题
Q: LongCat-Audio-Codec 是否支持离线部署?
A: 可完全离线运行,需准备相应的模型权重与依赖环境。
Q: 如何在移动端集成该编解码器?
A: 可通过量化模型或轻量化推理框架移植至移动或嵌入式平台。
Q: 是否可用于非语音类音频?
A: 当前版本主要针对语音任务优化,其他类型音频需额外训练。



