开源语音方案对比:Fun-CosyVoice3 vs 常见 TTS、Fun-ASR-Nano vs 主流 ASR
一、摘要 阿里通义语音团队(FunAudioLLM)开源两类音频模型:面向语音合成的 Fun-CosyVoice3-0.5B-2512(TTS),以及面向语音识别的 Fun-ASR-Nano-2512(ASR)。前者强调多语种、零样本声音克隆与低延迟流式合成;后者强调 31 语种识别、方言口音覆盖与...
Admin •
619
一、摘要 阿里通义语音团队(FunAudioLLM)开源两类音频模型:面向语音合成的 Fun-CosyVoice3-0.5B-2512(TTS),以及面向语音识别的 Fun-ASR-Nano-2512(ASR)。前者强调多语种、零样本声音克隆与低延迟流式合成;后者强调 31 语种识别、方言口音覆盖与...

一、摘要 GLM-TTS 是面向工业级语音生成的开源 TTS 系统,支持仅 3 秒语音样本的音色克隆,并提供可控的情绪表达能力。其架构采用两阶段生成流程,并引入基于 GRPO 的强化学习机制,在字符错误率(CER)与情感维度达到开源领先水平。项目强调低训练成本与高可扩展性,适用于教育、电子书、有声内...

一、摘要 Open-AutoGLM 是智谱AI开源的手机智能体(Agent)框架,核心模型为 AutoGLM-Phone-9B。它通过理解手机屏幕内容并模拟真实用户操作,实现“看得懂界面、听得懂指令、点得动手机”。框架主要面向 Android 场景,适合构建手机助手、自动化运营、测试等多种应用。 二...
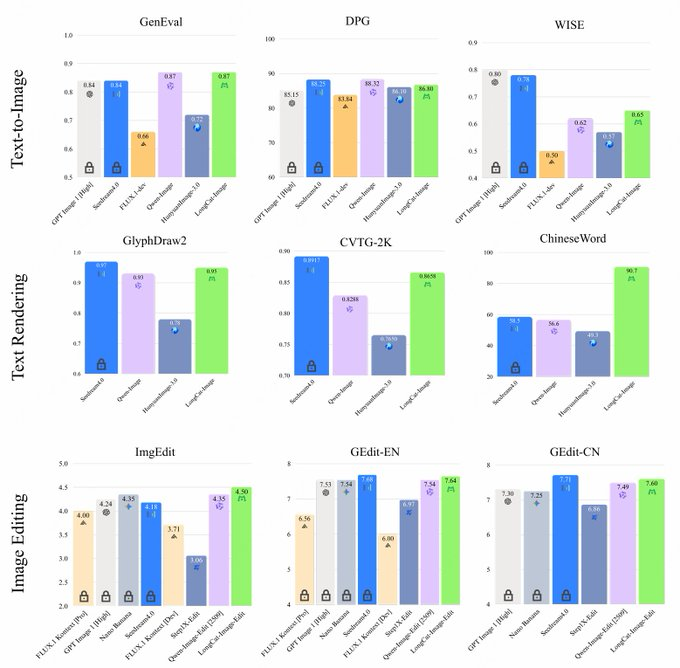
一、摘要 LongCat-Image 是美团 LongCat 团队开源的中英双语图像生成与编辑模型,参数约 6B,采用混合 DiT 架构,在多项公开基准上可比肩甚至超过部分 20B 级别开源模型。项目重点提升多语言文本渲染、图像一致性和写实效果,并兼顾推理速度与显存占用,适合研究与业务落地。 二、核...
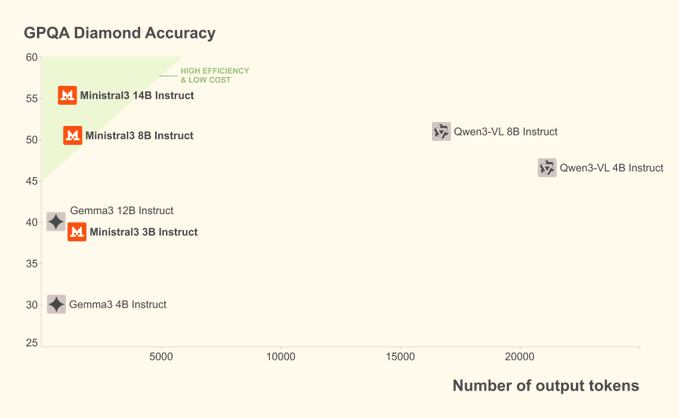
一、摘要 Mistral 3 是 Mistral AI 推出的新一代开源模型家族,包含稀疏专家架构的 Mistral Large 3,以及面向本地与边缘场景的 Ministral 3 系列(3B/8B/14B)。所有权重以 Apache 2.0 许可开放,支持多模态(文本+图像)与多语言,覆盖从个人...
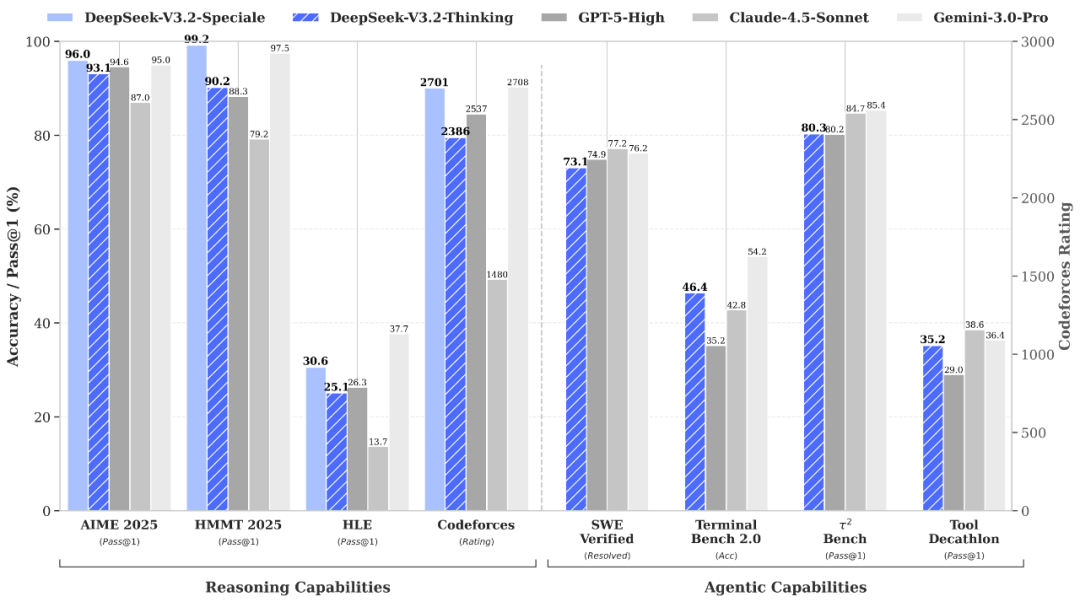
一、摘要 DeepSeek-V3.2 是在 V3.2-Exp 基础上正式发布的版本,重点优化了推理效率与输出长度,并沿用 DSA 稀疏注意力机制以提升长上下文性能。DeepSeek-V3.2-Speciale 聚焦极限数学推理、编程竞赛与严谨逻辑验证,在多个国际竞赛评测中表现突出。当前网页端、APP...