
Qwen-Image-Layered 开源解读:把一张图拆成可编辑 RGBA 图层的“原生分层”模型
一、摘要 Qwen-Image-Layered 是 Qwen 团队开源的图像“层分解”模型:输入一张普通 RGB 图片,输出多张彼此物理隔离的 RGBA 图层。与常见的“在同一张扁平图上做编辑”不同,它把主体与结构拆到独立层,使得重着色、移动、缩放、删除等基础操作更接近设计软件的无损流程,并支持把某...
Admin •
303
一、摘要 Qwen-Image-Layered 是 Qwen 团队开源的图像“层分解”模型:输入一张普通 RGB 图片,输出多张彼此物理隔离的 RGBA 图层。与常见的“在同一张扁平图上做编辑”不同,它把主体与结构拆到独立层,使得重着色、移动、缩放、删除等基础操作更接近设计软件的无损流程,并支持把某...
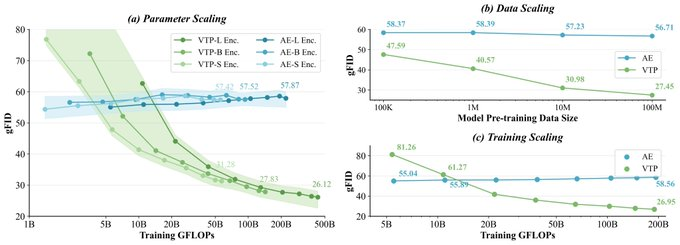
一、摘要 VTP(Visual Tokenizer Pre-training)是 MiniMax(Hailuo)团队开源的视觉 tokenizer 预训练框架,面向扩散模型与 Diffusion Transformer(DiT)等下一代生成模型。项目指出传统“仅重建”的 tokenizer 训练会让...
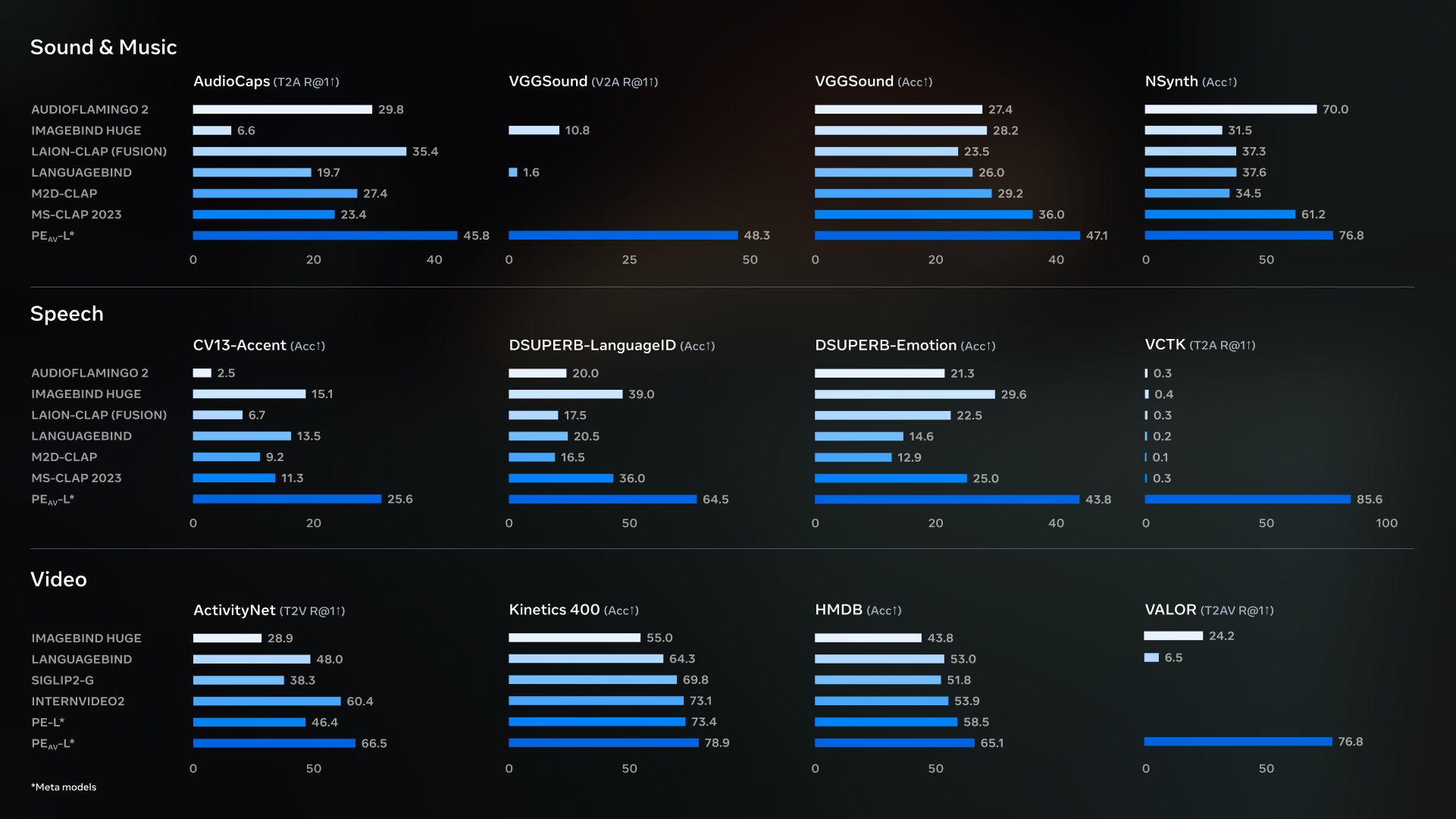
一、摘要 PE-AV(Perception Encoder Audiovisual)是 Meta 开源的音频-视觉联合编码器家族,在 Perception Encoder 基础上加入原生音频能力,用统一嵌入空间对齐视频、音频、音视频与文本表征。它被用于支撑 SAM Audio 的关键组件,并在多项音...

一、摘要 HY World 1.5(WorldPlay)是腾讯混元团队开源的实时世界模型框架,核心是一个支持流式生成的视频扩散模型。该系统可根据文本或图像输入,实时生成并更新可交互的 3D 世界,支持用户以第一人称或第三人称视角自由行走、观察和操作。其目标是解决当前世界模型在生成速度、长期一致性与上...
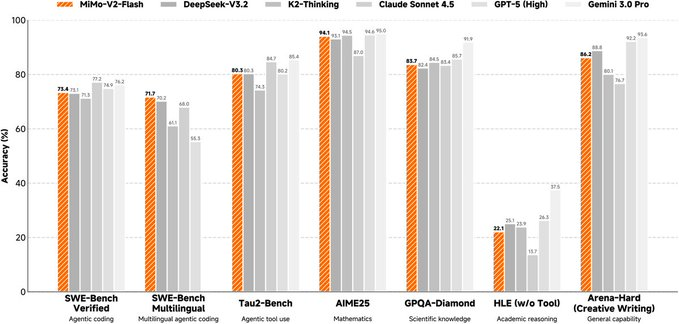
一、摘要 MiMo-V2-Flash 是小米 MiMo 团队开源的混合专家(MoE)大语言模型,总参数约 309B、推理时激活参数约 15B,主打在较低推理成本下兼顾推理、编程与智能体(Agent)工作流。它强调长上下文能力(最高 256K)与推理效率之间的平衡,并提供可复现的技术报告、权重与推理部...
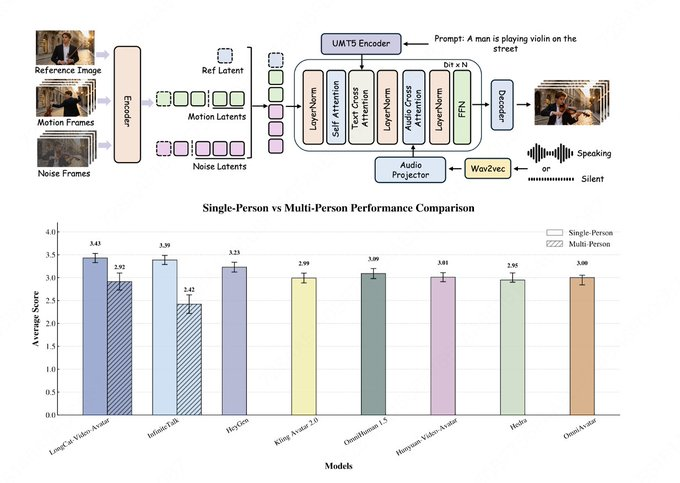
一、摘要 LongCat-Video-Avatar 是基于 LongCat-Video 架构打造的音频驱动 Avatar(虚拟人)视频生成模型,面向“长时序、强一致性、写实动态”场景。它将音频与文本(可选参考图)作为条件,原生支持 Audio-Text-to-Video(AT2V)、Audio-Te...