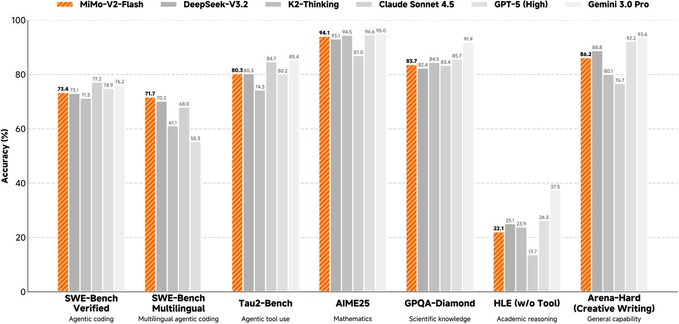
一、摘要
MiMo-V2-Flash 是小米 MiMo 团队开源的混合专家(MoE)大语言模型,总参数约 309B、推理时激活参数约 15B,主打在较低推理成本下兼顾推理、编程与智能体(Agent)工作流。它强调长上下文能力(最高 256K)与推理效率之间的平衡,并提供可复现的技术报告、权重与推理部署示例。
二、核心特性
1、MoE 高性价比推理:总参数规模大,但每次仅激活部分专家,降低单位请求算力消耗。
2、Hybrid Attention 架构:交错使用滑动窗口注意力与全局注意力,减少 KV cache 压力,同时维持长上下文效果。
3、多 Token 预测(MTP):在训练/推理中集成的多 token 预测模块,用于提升生成吞吐与整体推理速度。
4、面向 Agent 的后训练:结合多教师蒸馏与大规模 Agent 强化学习,使其在代码代理与复杂推理评测上更偏“可执行”。
5、长上下文支持:提供 32K 原生训练序列长度与最高 256K 上下文窗口的配置/推理建议(实际效果与资源需求强相关)。
三、安装
1、获取权重:从 Hugging Face 拉取对应模型(如 XiaomiMiMo/MiMo-V2-Flash)。
2、安装推理框架:官方推荐使用 SGLang(pip install sglang),并按示例启动 server。
3、启动与调用:通过 OpenAI 兼容的 chat/completions 接口进行请求;建议按官方给出的 temperature/top_p 与上下文长度参数进行初始对齐。
四、典型用例
1、代码生成与修复:面向仓库 issue、补丁生成、单测驱动修复等任务。
2、工具调用型 Agent:浏览、检索、执行脚本、编排多步骤任务(需要配合工具管理与权限隔离)。
3、长文档推理:长文总结、跨章节问答、长对话记忆(更适合“结构化输入 + 明确目标”的场景)。
4、高并发在线推理:借助 MoE 与高效注意力设计,适用于对吞吐和成本敏感的服务端场景。
五、生态与竞品
1、生态:提供 GitHub 仓库、技术报告与 Hugging Face 权重;并给出 SGLang 作为重点部署路径。
2、竞品:可对比同样强调推理/代码/Agent 的开源模型(如 DeepSeek、Kimi 等体系)。MiMo-V2-Flash 的差异点更集中在“长上下文 + KV 友好 + MTP 加速 + MoE 激活参数较小”的组合。不同业务需以自测为准。
六、局限与注意事项
1、资源门槛:即便激活参数较小,309B 级 MoE 的部署依然对多卡互联、显存与工程栈要求高。
2、长上下文成本:256K 输入会显著放大显存占用与延迟,需谨慎设置 chunked prefill、并发与上下文管理策略。
3、工具调用的“历史保留”要求:多轮思考/工具调用场景需要正确保留并回传推理字段与历史消息,否则容易断链。
4、许可证与合规:以仓库 LICENSE 为准;商用与分发需核对许可证条款、权重使用条款及数据合规要求。
七、项目地址
https://github.com/XiaomiMiMo/MiMo-V2-Flash
八、常见问题
Q: MiMo-V2-Flash 的关键规格(309B/15B、256K)分别代表什么?
A: 309B 是总参数规模,15B 是单次推理激活的参数规模;256K 是最大上下文窗口配置,越长越吃显存与延迟。
Q: MiMo-V2-Flash 推荐用什么方式部署推理?
A: 官方更推荐 SGLang 路线,按示例启动 server 并通过兼容接口调用;超长上下文与高并发需要结合多卡并行与缓存策略调参。
Q: MiMo-V2-Flash 的 Hybrid Attention 与 MTP 对我有什么实际收益?
A: 主要收益是降低长上下文 KV cache 压力并提升生成吞吐,从而在相近质量下减少推理成本;具体增益依赖硬件、批量大小与服务配置。
Q: MiMo-V2-Flash 适合本地单卡运行吗?
A: 通常不适合;更现实的路径是多卡服务器部署,或使用第三方托管/API 体验。