1. Abstract
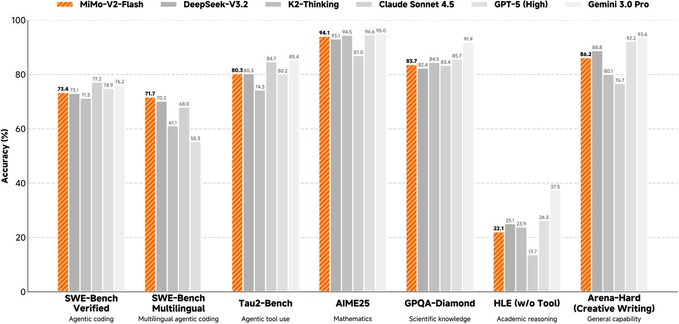
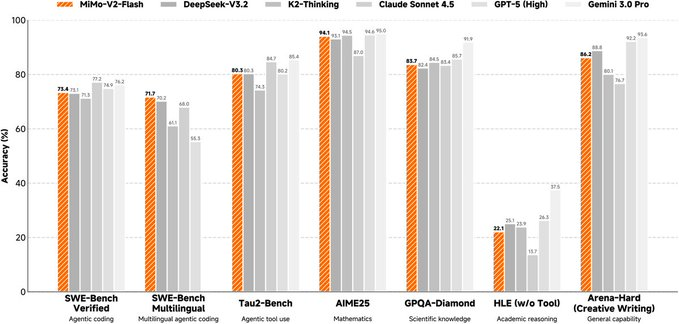
MiMo-V2-Flash is an open-sourced hybrid expert (MoE) large language model from the Xiaomi MiMo team, with a total parameter of about 309B and an activation parameter of about 15B during inference, focusing on balancing inference, programming, and agent workflows at a low inference cost. It emphasizes the balance between long-context capabilities (up to 256K) and inference efficiency, and provides reproducible technical reports, weights, and examples of inference deployments.
2. Core features
- MoE cost-effective reasoning: The total parameter scale is large, but only some experts are activated each time, reducing the computing power consumption per unit request.
- Hybrid Attention architecture: Staggered use of sliding window attention and global attention to reduce the pressure of KV cache while maintaining long context effects.
- Multi-token prediction (MTP): A multi-token prediction module integrated in training/inference to improve generation throughput and overall inference speed.
- Post-training for agents: Combines multi-teacher distillation with large-scale agent reinforcement learning to make it more "executable" in code agents and complex reasoning evaluations.
- Long context support: Provides configuration/inference suggestions for 32K native training sequence length and up to 256K context window (actual effect is strongly related to resource requirements).
3. Installation
- Get weights: Pull the corresponding model (such as XiaomiMiMo/MiMo-V2-Flash) from Hugging Face.
- Install the inference framework: The official recommends using SGLang (pip install sglang) and start the server as per the example.
- Startup and call: Make a request through OpenAI's compatible chat/completions interface; It is recommended to initially align the official temperature/top_p with the context length parameter.
4. Typical Use Cases
- Code generation and repair: For tasks such as repository issues, patch generation, and single test-driven repair.
- Tool-calling agents: browse, retrieve, execute scripts, and orchestrate multi-step tasks (need to cooperate with tool management and permission isolation).
- Long document reasoning: long text summary, cross-chapter Q&A, long dialogue memory (more suitable for "structured input + clear goals" scenarios).
- High concurrency online inference: With MoE and efficient attention design, it is suitable for server-side scenarios that are sensitive to throughput and cost.
5. Ecosystem and competitors
- Ecosystem: Provide GitHub repositories, technical reports, and Hugging Face weights. And give SGLang as the key deployment path.
- Competing products: can be compared with open source models that also emphasize reasoning/code/agent (such as DeepSeek, Kimi, etc.). The difference between MiMo-V2-Flash is more focused on the combination of "long context + KV-friendly + MTP acceleration + small MoE activation parameters". Different businesses need to be subject to self-testing.
6. Limitations and precautions
- Resource threshold: Even if the activation parameters are small, the deployment of 309B-level MoE still requires high requirements for multi-card interconnection, video memory, and engineering stack.
- Long context cost: 256K input can significantly increase memory usage and latency, so chunked prefill, concurrency, and context management policies need to be set carefully.
- "History retention" requirements for tool calls: Multi-round thinking/tool call scenarios need to correctly retain and return inference fields and historical messages, otherwise it is easy to break the chain.
- License and compliance: the warehouse LICENSE shall prevail; Commercial and distribution require checking license terms, weighted usage terms, and data compliance requirements.
7. Project address
https://github.com/XiaomiMiMo/MiMo-V2-Flash
8. FAQ
Q: Key specifications of MiMo-V2-Flash (309B/15B, 256K) stands for each?
A: 309B is the total parameter scale, and 15B is the parameter scale for a single inference activation; 256K is the maximum context window configuration, and the longer it is, the more memory and latency it eats.
Q: What is the recommended way to deploy inference with MiMo-V2-Flash?
A: The official recommends the SGLang route, which starts the server according to the example and calls it through a compatible interface. Ultra-long contexts and high concurrency require a combination of multi-card parallelism and caching strategies.
Q: What are the real benefits of MiMo-V2-Flash's Hybrid Attention and MTP for me?
A: The main benefit is to reduce the pressure of long-context KV cache and increase the generation throughput, thereby reducing inference costs at similar quality; The specific gain depends on the hardware, batch size, and service configuration.
Q: Is MiMo-V2-Flash suitable for local single-card operation?
A: Generally not suitable; A more realistic path is a multi-card server deployment, or using a third-party hosting/API experience.