1. Abstract
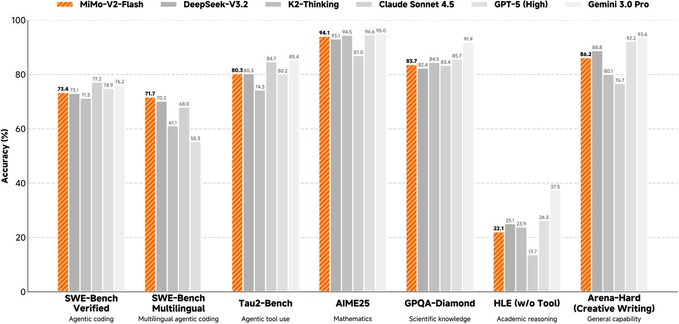
MiMo-V2-Flashは、Xiaomi MiMoチームによるオープンソースのハイブリッドエキスパート(MoE)大規模言語モデルで、推論中の総パラメータは約309B、活性化パラメータは約15Bで、推論、プログラミング、エージェントワークフローのバランスを低コストで行うことに重点を置いています。 長文脈能力(最大256K)と推論効率のバランスを強調し、再現可能な技術報告書、重み付け、推論展開の例を提供します。
2. コア機能
- MoEのコスト効率合理的推論:全体のパラメータスケールは大きいものの、毎回アクティブされるエキスパートは一部ののみであり、単位要求あたりの計算能力消費を削減します。
- ハイブリッドアテンションアーキテクチャ:スライディングウィンドウアテンションとグローバルアテンションを段階的に用いて、KVキャッシュの圧力を軽減しつつ、長いコンテキスト効果を維持します。
- マルチトークン予測(MTP):生成スループットと全体の推論速度を向上させるためにトレーニング/推論に統合されたマルチトークン予測モジュール。
- エージェントのポストトレーニング:マルチティーチャーによる蒸留と大規模なエージェント強化学習を組み合わせ、コードエージェントや複雑な推論評価においてより「実行可能」にします。
- 長いコンテキストサポート:32Kのネイティブトレーニングシーケンス長と最大256Kコンテキストウィンドウ(実際の効果はリソース要件と強く関連)に対して設定/推論提案を提供します。
3. 設置
- ウェイトを入手:対応モデル(例えばXiaomiMiMo/MiMo-V2-Flash)をHugging Faceから取り出します。
- 推論フレームワークのインストール:公式の方はSGLang(pip install sglang)を使い、例通りサーバーを起動することを推奨しています。
- 起動および通話:OpenAIの対応チャット/完了インターフェースを通じてリクエストを行う; 公式の温度/top_pを最初にコンテキストの長さパラメータに合わせることが推奨されます。
4. 典型的なユースケース
- コード生成と修復:リポジトリの問題、パッチ生成、単一テスト駆動の修復などのタスクに用いられます。
- ツール呼び出しエージェント:ブラウズ、取得、スクリプト実行、多段階タスクのオーケストレーション(ツール管理および権限分離と協力が必要)。
- 長い文書推論:長いテキスト要約、章をまたぐQ&A、長い対話記憶(「構造化された入力+明確な目標」シナリオにより適している)。
- 高並行性オンライン推論:MoEと効率的な注意設計により、スループットやコストに敏感なサーバー側シナリオに適しています。
5. エコシステムと競合他社
- エコシステム:GitHubリポジトリ、技術レポート、Hugging Faceの重みを提供します。 そしてSGLangを主要な展開経路として設定してください。
- 競合製品:推論・コード・エージェントを重視するオープンソースモデル(DeepSeek、Kimiなど)と比較できます。 MiMo-V2-Flashの違いは「長いコンテキスト+KVに優しい+MTP加速+小さなMoE活性化パラメータ」の組み合わせにより焦点が当てられています。 異なる企業が自己検査を受ける必要があります。
6. 制限と注意事項
- リソース閾値:アクティベーションパラメータが小さくても、309BレベルのMoEの展開にはマルチカード相互接続、ビデオメモリ、エンジニアリングスタックの高い要件が求められます。
- 長いコンテキストコスト:256Kの入力はメモリ使用量と遅延を大幅に増加させるため、チャンクプリフィル、並行性、コンテキスト管理のポリシーを慎重に設定する必要があります。
- ツール呼び出しの「履歴保持」要件:複数ラウンド思考やツール呼び出しのシナリオでは、推論フィールドや履歴メッセージを正しく保持・返す必要があり、そうでなければ連鎖が途切れやすくなります。
- ライセンスおよび遵守:倉庫のライセンスが優先されます。 商用および配信では、ライセンス条件、加重利用条件、データコンプライアンス要件の確認が必要です。
7. プロジェクトアドレス
https://github.com/XiaomiMiMo/MiMo-V2-Flash
8. FAQ
Q: MiMo-V2-Flash(309B/15B)の主要仕様 256K)はそれぞれの略ですか?
A: 309Bは総パラメータスケール、15Bは単一推論活性化のパラメータスケールです。 256Kが最大コンテキストウィンドウ構成であり、長ければ長いほどメモリやレイテンシを消費します。
Q: MiMo-V2-Flashで推論を展開する推奨方法は何ですか?
A: 公式はSGLangルートを推奨しており、例に従ってサーバーを起動し、互換インターフェースで呼び出す方法です。 超長コンテキストや高並行処理には、マルチカード並列処理とキャッシュ戦略の組み合わせが必要です。
Q: MiMo-V2-FlashのハイブリッドアテンションとMTPの本当の利点は何ですか?
A: 主な利点は、長文脈KVキャッシュの負荷を軽減し、生成スループットを向上させることで、同等の品質で推論コストを削減できることです。 具体的な利得はハードウェア、バッチサイズ、サービス構成によって異なります。
Q: MiMo-V2-Flashはローカルのシングルカード操作に適していますか?
A: 一般的に適していません。 より現実的な方法は、マルチカードサーバーの展開やサードパーティのホスティング/API体験を利用することです。