1. 추상
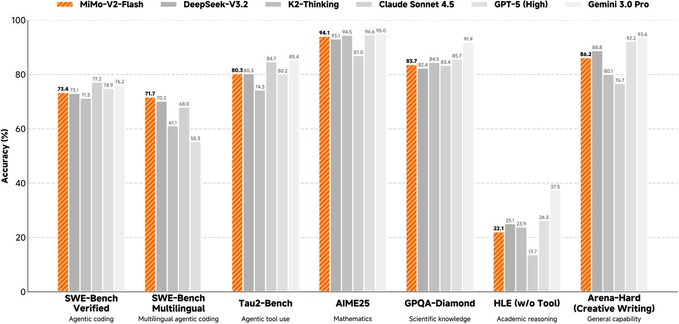
MiMo-V2-Flash는 Xiaomi MiMo 팀의 오픈 소스 하이브리드 전문가(MoE) 대형 언어 모델로, 총 매개변수 약 309B, 추론 중 활성화 매개변수 약 15B를 가지며, 추론, 프로그래밍, 에이전트 워크플로우를 낮은 추론 비용으로 균형 있게 조정하는 데 중점을 둡니다. 장기 컨텍스트 기능(최대 256K)과 추론 효율성 간의 균형을 강조하며, 재현 가능한 기술 보고서, 가중치, 추론 배포 사례를 제공합니다.
2. 핵심 특징
- MoE 비용 효율적인 추론: 전체 매개변수 규모는 크지만, 매번 일부 전문가만 활성화되어 단위 요청당 연산 에너지 소비를 줄입니다.
- 하이브리드 어텐션 아키텍처: 슬라이딩 윈도우 어텐션과 글로벌 어텐션을 단계적으로 사용하여 KV 캐시의 압력을 줄이면서 긴 컨텍스트 효과를 유지하는 방식.
- 다중 토큰 예측(MTP): 생성 처리량과 전체 추론 속도를 향상시키기 위해 훈련/추론에 통합된 다중 토큰 예측 모듈입니다.
- 에이전트 사후 학습: 다중 교사 증류와 대규모 에이전트 강화 학습을 결합하여 코드 에이전트와 복잡한 추론 평가에서 더 '실행 가능'하게 만듭니다.
- 긴 컨텍스트 지원: 32K 네이티브 훈련 시퀀스 길이와 최대 256K 컨텍스트 윈도우에 대한 구성/추론 제안을 제공합니다(실제 효과는 자원 요구량과 밀접하게 관련됨).
3. 설치
- 무게추 확보: Hugging Face에서 해당 모델(예: XiaomiMiMo/MiMo-V2-Flash)을 꺼내세요.
- 추론 프레임워크 설치: 공식 안내원은 SGLang(pip install sglang)을 사용해 예시처럼 서버를 시작하라고 권장합니다.
- 시작 및 통화: OpenAI의 호환 채팅/완료 인터페이스를 통해 요청을 할 수 있습니다; 공식적인 온도/top_p 값을 처음에는 맥락 길이 매개변수와 일치시키는 것이 권장됩니다.
4. 일반적인 사용 사례
- 코드 생성 및 수리: 저장소 문제, 패치 생성, 단일 테스트 기반 복구와 같은 작업에 적합합니다.
- 툴 호출 에이전트: 탐색, 검색, 스크립트 실행 및 다단계 작업 조정(도구 관리 및 권한 격리와 협력 필요).
- 긴 문서 추론: 긴 텍스트 요약, 장을 넘는 질의응답, 긴 대화 기억('구조화된 입력 + 명확한 목표' 시나리오에 더 적합함).
- 높은 동시성 온라인 추론: MoE와 효율적인 주의 설계를 통해 처리량과 비용에 민감한 서버 측 시나리오에 적합합니다.
5. 생태계와 경쟁자
- 생태계: GitHub 저장소, 기술 보고서, 그리고 Hugging Face 가중치를 제공하세요. 그리고 SGLang을 핵심 배포 경로로 설정하세요.
- 경쟁 제품: 추론/코드/에이전트를 강조하는 오픈 소스 모델(예: DeepSeek, Kimi 등)과 비교할 수 있습니다. MiMo-V2-Flash의 차이는 "긴 컨텍스트 + KV 친화적 + MTP 가속 + 작은 MoE 활성화 파라미터"의 조합에 더 집중되어 있습니다. 각 기업마다 자가 검사를 받아야 합니다.
6. 제한 및 주의사항
- 자원 임계값: 활성화 매개변수가 작더라도 309B 수준의 MoE 배포는 다중 카드 상호 연결, 비디오 메모리, 엔지니어링 스택에 대한 높은 요구를 요구합니다.
- 긴 컨텍스트 비용: 256K 입력은 메모리 사용량과 지연 시간을 크게 증가시킬 수 있으므로, 청크 프리필, 동시성, 컨텍스트 관리 정책을 신중하게 설정해야 합니다.
- 도구 호출에 대한 "역사 보존" 요구사항: 다중 라운드 사고/도구 호출 시나리오는 추론 필드와 과거 메시지를 올바르게 유지하고 반환해야 하며, 그렇지 않으면 체인이 끊기기 쉽습니다.
- 라이선스 및 준수: 창고 라이선스가 우선합니다; 상업용 및 배포는 라이선스 조건, 가중 사용 조건, 데이터 준수 요건을 확인해야 합니다.
7. 프로젝트 주소
https://github.com/XiaomiMiMo/MiMo-V2-Flash
8. FAQ
Q: MiMo-V2-Flash (309B/15B, 256K)는 각각을 나타내는 약자인가요?
답변: 309B는 전체 매개변수 척도이고, 15B는 단일 추론 활성화의 매개변수 척도입니다; 256K가 최대 컨텍스트 윈도우 구성이며, 길이가 길수록 메모리와 지연 시간을 더 많이 소비합니다.
Q: MiMo-V2-Flash를 사용하는 추론을 배포하는 권장 방법은 무엇인가요?
답변: 관계자는 예시에 따라 서버를 시작하고 호환 인터페이스를 통해 호출하는 SGLang 경로를 권장합니다. 초장기 컨텍스트와 높은 동시성은 다중 카드 병렬성과 캐싱 전략의 조합이 필요합니다.
Q: MiMo-V2-Flash의 하이브리드 어텐션과 MTP가 저에게 실제로 어떤 이점을 가지고 있나요?
A: 주요 이점은 장기 컨텍스트 KV 캐시의 압력을 줄이고 생성 처리량을 증가시켜 유사한 품질로 추론 비용을 줄이는 것입니다; 구체적인 이득은 하드웨어, 배치 크기, 서비스 구성에 따라 다릅니다.
Q: MiMo-V2-Flash는 로컬 싱글 카드 사용에 적합한가요?
답변: 일반적으로 적합하지 않습니다; 더 현실적인 방법은 멀티 카드 서버 배포나 서드파티 호스팅/API 경험을 사용하는 것입니다.