一、摘要
Qwen3-ASR 与 Qwen3-ForcedAligner 是面向“嘈杂、复杂、不可控”真实录音场景的开源语音模型与对齐组件。它们主打多语种自动识别、对噪声与混响的鲁棒性、最长约 20 分钟的长音频处理,以及在部分语言上提供词/短语级高精度时间戳对齐能力,并配套开源的推理与微调工程栈,便于落地到批量转写、流式字幕与在线服务。
二、核心特性
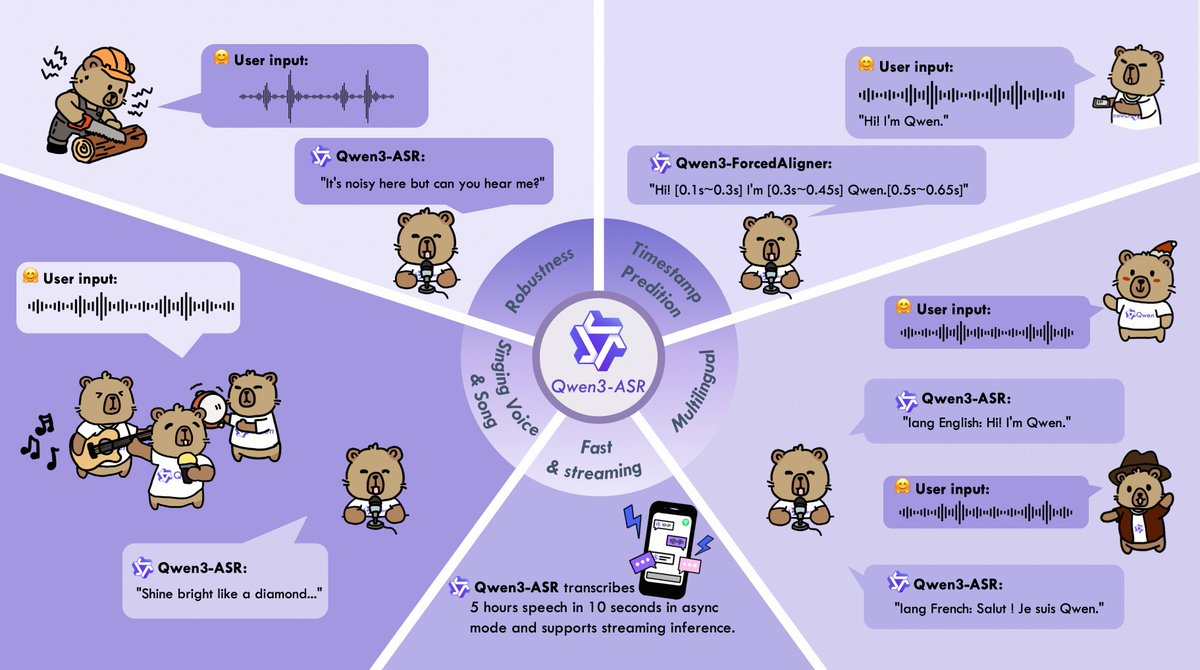
1、多语种与自动语种识别:覆盖 52 种语言与方言/口音(30 种语言 + 22 种方言/口音),支持自动 Language ID。
2、复杂音频鲁棒性:面向噪声、多人说话、远场、混响等场景优化;也覆盖更“非典型”的音频形态(如歌声与歌曲片段)。
3、长音频支持:单次处理最长可达约 20 分钟,减少长录音切分带来的上下文断裂与工程复杂度。
4、词/短语级时间戳:通过 Qwen3-ForcedAligner 在 11 种语言上提供高精度对齐,面向字幕、检索与审校流程更友好。
5、工程化栈:提供完整开源的推理与微调体系,包含 vLLM 批处理、流式与异步服务能力,便于上线与压测。
三、安装
1、获取代码:克隆仓库后按 README 安装依赖(建议使用隔离环境与固定版本)。
2、获取权重:从 Hugging Face 或 ModelScope 选择合适的模型与配置。
3、运行方式:按场景选批量离线转写(batch)、在线流式(streaming)或异步服务(async serving),并根据吞吐量配置并发与队列。
四、典型用例
1、呼叫中心/会议转写:噪声、口音、多说话人情况下做批量转写与质检抽样。
2、字幕生产与回放检索:用 ForcedAligner 生成词/短语级时间戳,支持“点词跳转”、高亮跟随与片段复核。
3、短视频与音乐类素材处理:对含背景音乐、节奏明显或歌声片段的素材做可用转写与解释性输出。
4、长录音归档:面向 10–20 分钟音频的分段策略简化,结合时间戳快速定位重点。
5、边端到云端混合:边端做初筛或降噪预处理,云端用批量/异步服务集中转写与对齐。
五、生态与竞品
1、生态入口:GitHub 提供代码与论文材料;Hugging Face / ModelScope 提供模型集合与在线 Demo,便于评估与集成。
2、竞品思路:在“强对齐”领域,常见方案包括 MFA 以及基于 CTC/CIF 风格的对齐器。Qwen3-ForcedAligner 的定位是把对齐能力作为可落地组件,面向字幕与审校的精度与稳定性优化。实际优劣仍建议用自有数据集做 A/B(口音、噪声、说话风格、领域术语差异会显著影响结果)。
六、局限与注意事项
1、算力与成本:多语种、长音频与高精度对齐会提高推理时延与资源占用,需做吞吐量评估与弹性扩缩容设计。
2、数据分布偏差:极端口音、强混响、重叠语音、领域术语与低资源语种仍可能带来误识别或时间戳漂移,建议引入人工复核闭环。
3、长音频策略:即使支持 20 分钟单次处理,仍建议在超长素材上结合分段、重叠窗口与后处理拼接,以降低边界错误。
4、对齐语言范围:ForcedAligner 的高精度对齐目前强调 11 种语言覆盖;其余语言可先以句级/段级时间戳满足检索,再视需求补齐。
七、项目地址
https://github.com/QwenLM/Qwen3-ASR
八、常见问题
Q: Qwen3-ASR 是否支持 52 种语言与方言的自动语种识别(Language ID)?
A: 支持,包含 30 种语言与 22 种方言/口音,并可自动识别语种后进行转写。
Q: Qwen3-ASR 能处理嘈杂环境或带背景音乐、歌声的真实音频吗?
A: 目标就是提升噪声与复杂音频的鲁棒性,包含对歌曲/歌声片段的适配,但建议用你的真实素材做抽样评估。
Q: Qwen3-ASR 单次最长能处理多长音频?
A: 标称可支持最长约 20 分钟/次的处理;更长素材建议结合分段与重叠窗口策略。
Q: Qwen3-ForcedAligner 的“词/短语级时间戳”适用哪些语言?
A: 目前强调在 11 种语言上提供高精度对齐能力,适合字幕、检索与审校。
Q: Qwen3-ForcedAligner 相比 MFA/CTC/CIF 风格对齐器有什么价值?
A: 侧重把对齐能力做成可直接集成的工程组件,面向词/短语级时间戳的精度与稳定性;最终以你的任务数据对比为准。
Q: 是否提供生产可用的推理与微调(finetuning)工具链?
A: 提供完整开源栈,覆盖 vLLM 批处理、流式与异步服务,并包含微调相关流程,便于部署与迭代。