1. Abstract
Qwen3-ASR and Qwen3-ForcedAligner are open-source voice models and alignment components for "noisy, complex, and uncontrollable" real-world recording scenarios. They focus on multilingual automatic recognition, robustness to noise and reverberation, long audio processing up to about 20 minutes, and word/phrase-level high-precision timestamp alignment capabilities in select languages, and are equipped with an open-source inference and fine-tuning engineering stack for batch transcription, streaming subtitling, and online services.
2. Core features
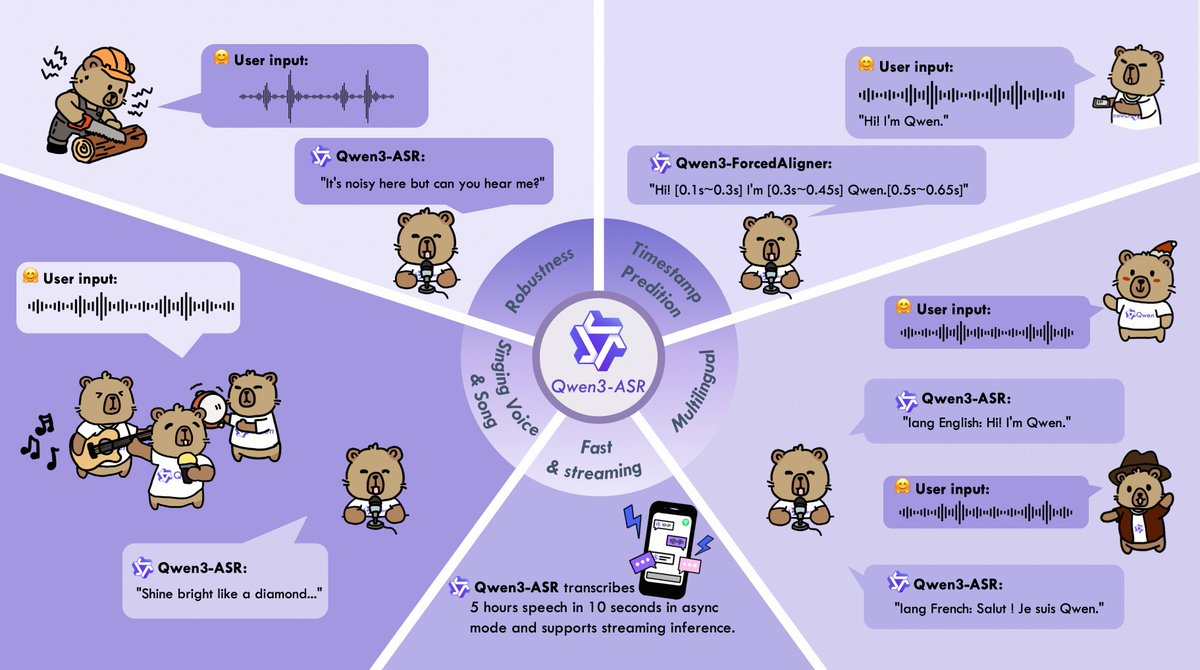
- Multilingual and automatic language recognition: covers 52 languages and dialects/accents (30 languages + 22 dialects/accents), and supports automatic Language ID.
- Complex audio robustness: optimized for noise, multiple people, far-field, reverberation and other scenarios; It also covers more "atypical" audio forms (such as vocals and song clips).
- Long audio support: A single processing can be up to about 20 minutes, reducing the context breakage and engineering complexity caused by long recording segmentation.
- Word/phrase-level timestamps: Provide high-precision alignment in 11 languages with Qwen3-ForcedAligner, making it more user-friendly for subtitles, retrieval, and review processes.
- Engineering stack: Provides a complete and open-source inference and fine-tuning system, including vLLM batch processing, streaming and asynchronous service capabilities, making it easy to go online and test.
3. Installation
- Get the code: After cloning the repository, press the README to install the dependencies (it is recommended to use an isolated environment and a fixed version).
- Obtain weights: Select the appropriate model and configuration from Hugging Face or ModelScope.
- Operation mode: Select batch offline transcription (batch), online streaming (streaming) or async serving (async serving) according to the scenario, and configure concurrency and queue according to throughput.
4. Typical use cases
- Call center/conference transcription: batch transcription and quality inspection sampling in the case of noise, accent, and multiple speakers.
- Subtitle production and playback retrieval: Use ForcedAligner to generate word/phrase-level timestamps, support "dot jumping", highlight following, and clip review.
- Short video and music material processing: Transcribe and explanatory output of materials containing background music, obvious rhythm or singing clips.
- Long recording archiving: Simplify segmentation strategies for 10–20 minutes of audio, combined with timestamps to quickly locate key points.
- Edge-to-cloud mixing: The edge-end does initial screening or noise reduction preprocessing, and the cloud uses batch/asynchronous services to centrally transcribe and align.
5. Ecology and competing products
- Ecological entrance: GitHub provides code and paper materials; Hugging Face / ModelScope provides model collections and online demos for easy evaluation and integration.
- Competitive product ideas: In the field of "strong alignment", common solutions include MFA and aligners based on CTC/CIF-style aligners. Qwen3-ForcedAligner is positioned to optimize the accuracy and stability of subtitles and proofreading with alignment capabilities as a landable component. It is still recommended to use your own dataset for A/B (differences in accent, noise, speaking style, and domain terminology will significantly affect the results).
6. Limitations and precautions
- Computing power and cost: Multilingual, long-form audio and high-precision alignment will increase inference latency and resource occupation, and need to do throughput evaluation and elastic scaling design.
- Data distribution bias: Extreme accents, strong reverberation, overlapping voices, domain terminology, and low-resource languages may still lead to misidentification or timestamp drift, so it is recommended to introduce a closed loop of manual review.
- Long audio strategy: Even if a 20-minute single processing is supported, it is still recommended to combine segmentation, overlapping windows, and post-processing splicing on ultra-long footage to reduce boundary errors.
- Alignment Language Range: ForcedAligner's high-precision alignment currently emphasizes 11 language coverage; The rest of the languages can be searched with sentence/paragraph level timestamps and then supplemented as needed.
7. Project address
https://github.com/QwenLM/Qwen3-ASR
8. Frequently asked questions
Q: Does Qwen3-ASR support automatic language ID for 52 languages and dialects?
A: Yes, including 30 languages and 22 dialects/accents, and can automatically recognize the language and transcribe.
Q: Can the Qwen3-ASR handle noisy environments or real audio with background music and singing?
A: The goal is to improve the robustness of noise and complex audio, including adaptation to songs/vocal clips, but it is recommended to sample your real footage.
Q: How long can the Qwen3-ASR handle in a single session?
A: Nominal can support up to about 20 minutes/time processing; Longer clips are recommended in combination with segmentation and overlapping window strategies.
Q: What languages is Qwen3-ForcedAligner's "word/phrase-level timestamp" available in?
A: The current emphasis is on providing high-precision alignment capabilities in 11 languages, suitable for subtitling, retrieval, and proofreading.
Q: What is the value of the Qwen3-ForcedAligner compared to MFA/CTC/CIF style aligners?
A: Focus on making alignment capabilities into directly integrated engineering components, oriented to the accuracy and stability of word/phrase-level timestamps; In the end, the comparison of your task data shall prevail.
Q: Is there a production-ready inference and finetuning toolchain?
A: It provides a complete open-source stack covering vLLM batch, streaming, and asynchronous services, and includes fine-tuning related processes for easy deployment and iteration.