1. Zusammenfassung
Qwen3-ASR und Qwen3-ForcedAligner sind Open-Source-Sprachmodelle und Ausrichtungskomponenten für "verrauschte, komplexe und unkontrollierbare" reale Aufzeichnungsszenarien. Sie konzentrieren sich auf mehrsprachige automatische Erkennung, Robustheit gegenüber Rauschen und Hall, lange Audioverarbeitung von bis zu etwa 20 Minuten sowie hochpräzise Zeitstempelausrichtung auf Wort-/Phrasenebene in ausgewählten Sprachen und sind mit einem Open-Source-Inferenz- und Feinabstimmungs-Engineering-Stack für Batch-Transkription, Streaming-Untertitelung und Online-Dienste ausgestattet.
2. Kernmerkmale
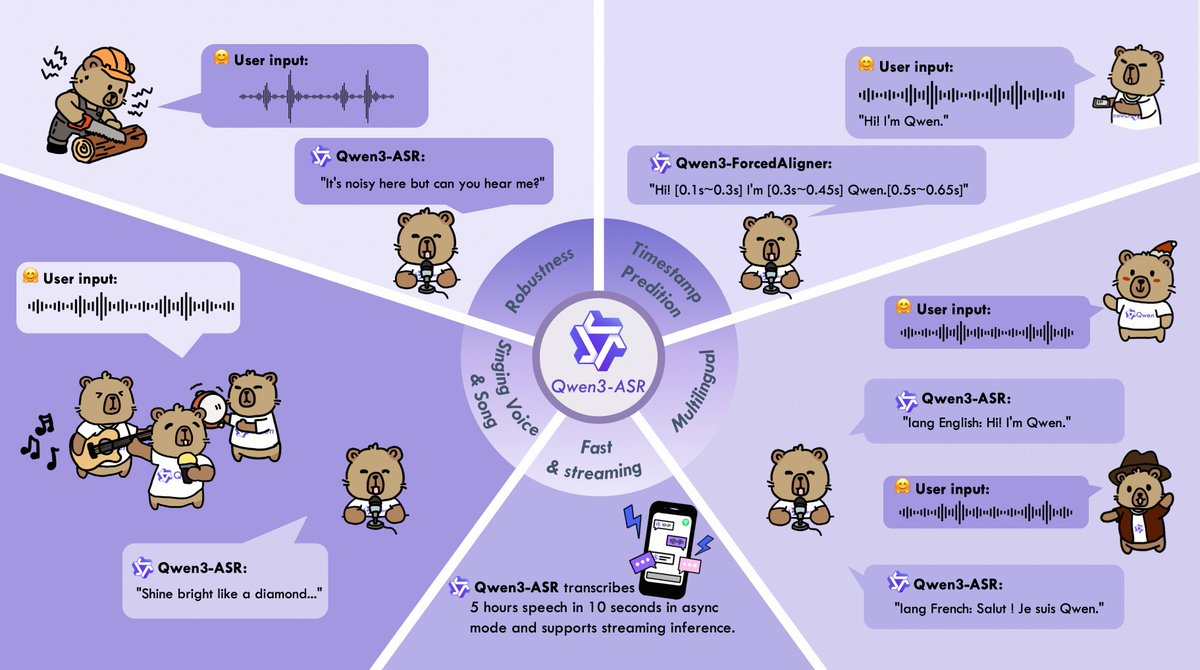
- Mehrsprachige und automatische Spracherkennung: umfasst 52 Sprachen und Dialekte/Akzente (30 Sprachen + 22 Dialekte/Akzente) und unterstützt automatische Spracherkennung.
- Komplexe Audiorobustheit: optimiert für Rauschen, mehrere Personen, Fernfeld, Nachhall und andere Szenarien; Es behandelt auch mehr "atypische" Audioformen (wie Gesang und Songclips).
- Langes Audio-Support: Eine einzelne Verarbeitung kann bis zu etwa 20 Minuten dauern, was den Kontextbruch und die technische Komplexität durch lange Aufnahmesegmentierung reduziert.
- Zeitstempel auf Wort-/Phrasenebene: Bieten Sie eine hochpräzise Ausrichtung in 11 Sprachen mit Qwen3-ForcedAligner, was die Benutzerfreundlichkeit für Untertitel, Abruf und Überprüfungsprozesse erleichtert.
- Engineering-Stack: Bietet ein vollständiges und quelloffenes Inferenz- und Feinabstimmungssystem, einschließlich vLLM-Batchverarbeitung, Streaming und asynchronen Service-Funktionen, was es einfach macht, online zu testen und zu testen.
3. Installation
- Code abholen: Nach dem Klonen des Repositorys drücken Sie die README, um die Abhängigkeiten zu installieren (es wird empfohlen, eine isolierte Umgebung und eine feste Version zu verwenden).
- Gewichte erhalten: Wählen Sie das passende Modell und die Konfiguration aus Hugging Face oder ModelScope aus.
- Betriebsmodus: Wählen Sie je nach Szenario Batch-Offline-Transkription (Batch), Online-Streaming (Streaming) oder asynchrones Servieren (asynchrones Servieren) und konfigurieren Sie Nebenläufigkeit und Warteschlange entsprechend dem Durchsatz.
4. Typische Anwendungsfälle
- Callcenter-/Konferenz-Transkription: Batch-Transkription und Qualitätsprüfung bei Rauschen, Akzent und mehreren Lautsprechern.
- Untertitelproduktion und Wiedergabe: Verwenden Sie ForcedAligner, um Zeitstempel auf Wort-/Phrasenebene zu generieren, "Dot-Jumping" zu unterstützen, Highlight-Folgen zu folgen und Clip-Review zu überprüfen.
- Kurzvideo- und Musikmaterialverarbeitung: Transkribierende und erklärende Ausgaben von Materialien mit Hintergrundmusik, offensichtlichen Rhythmus- oder Gesangsclips.
- Langzeitarchivierung: Vereinfachen Sie Segmentierungsstrategien für 10–20 Minuten Audio, kombiniert mit Zeitstempeln, um wichtige Punkte schnell zu finden.
- Edge-to-Cloud-Mixing: Das Edge-End führt das erste Screening oder die Rauschreduzierung durch, und die Cloud nutzt Batch-/asynchrone Dienste, um zentral zu transkribieren und auszurichten.
5. Ökologie und konkurrierende Produkte
- Ökologischer Eingang: GitHub stellt Code und Papiermaterial bereit; Hugging Face / ModelScope bietet Modellsammlungen und Online-Demos zur einfachen Bewertung und Integration an.
- Wettbewerbsfähige Produktideen: Im Bereich der "starken Ausrichtung" sind gängige Lösungen MFA und Aligner basierend auf CTC/CIF-ähnlichen Aligner verwendet. Qwen3-ForcedAligner ist darauf ausgelegt, die Genauigkeit und Stabilität von Untertiteln und Korrekturlesen mit Ausrichtungsfunktionen als landfähiger Komponente zu optimieren. Es wird dennoch empfohlen, den eigenen Datensatz für A/B zu verwenden (Unterschiede in Akzent, Rauschen, Sprechstil und Domänenterminologie beeinflussen die Ergebnisse erheblich).
6. Einschränkungen und Vorsichtsmaßnahmen
- Rechenleistung und Kosten: Mehrsprachige, langformige Audio- und hochpräzise Ausrichtung erhöhen die Inferenzlatenz und den Ressourcenverbrauch und erfordern Durchsatzbewertungen und elastische Skalierungsdesigns.
- Datenverteilungsverzerrung: Extreme Akzente, starker Nachhall, überlappende Stimmen, Domänenterminologie und ressourcenarme Sprachen können weiterhin zu Fehlidentifikationen oder Zeitstempelabweichungen führen, daher wird empfohlen, eine geschlossene manuelle Überprüfung einzuführen.
- Long-Audio-Strategie: Selbst wenn eine 20-minütige Einzelverarbeitung unterstützt wird, wird dennoch empfohlen, Segmentierung, überlappende Fenster und Nachbearbeitungs-Splicing auf ultralangen Filmmaterial zu kombinieren, um Randfehler zu reduzieren.
- Ausrichtungssprachbereich: ForcedAligners hochpräzise Ausrichtung legt derzeit Wert auf 11 Sprachabdeckungen; Die übrigen Sprachen können mit Zeitstempeln auf Satz-/Absatzebene durchsucht und dann bei Bedarf ergänzt werden.
7. Projektadresse
https://github.com/QwenLM/Qwen3-ASR
8. Häufig gestellte Fragen
F: Unterstützt Qwen3-ASR automatische Spracherkennung für 52 Sprachen und Dialekte?
A: Ja, einschließlich 30 Sprachen und 22 Dialekten/Akzenten, und kann die Sprache automatisch erkennen und transkribieren.
F: Kann der Qwen3-ASR laute Umgebungen oder echten Ton mit Hintergrundmusik und Gesang bewältigen?
A: Das Ziel ist es, die Robustheit von Rauschen und komplexem Audio zu verbessern, einschließlich der Anpassung an Songs/Gesangsclips, aber es wird empfohlen, dein echtes Material zu samplen.
F: Wie lange hält der Qwen3-ASR in einer einzigen Sitzung aus?
A: Nominal kann bis zu etwa 20 Minuten pro Verarbeitungszeit unterstützen; Längere Clips werden in Kombination mit Segmentierung und überlappenden Fensterstrategien empfohlen.
F: In welchen Sprachen ist Qwen3-ForcedAligners "Wort-/Phrasen-Level-Zeitstempel" verfügbar?
A: Der aktuelle Schwerpunkt liegt auf hochpräzisen Ausrichtungsmöglichkeiten in 11 Sprachen, die sich für Untertitel, Abruf und Korrekturlesen eignen.
F: Welchen Wert hat der Qwen3-ForcedAligner im Vergleich zu MFA/CTC/CIF-Aligner im Stil?
A: Fokus darauf, Ausrichtungsfähigkeiten in direkt integrierte technische Komponenten umzuwandeln, die auf die Genauigkeit und Stabilität von Zeitstempeln auf Wort-/Phrasenebene ausgerichtet sind; Am Ende wird der Vergleich Ihrer Aufgabendaten durchsetzen.
F: Gibt es eine produktionsreife Inferenz- und Feinabstimmungs-Toolchain?
A: Es bietet einen vollständigen Open-Source-Stack, der vLLM-Batch-, Streaming- und asynchrone Dienste abdeckt und die Feinabstimmung der damit verbundenen Prozesse für eine einfache Bereitstellung und Iteration beinhaltet.