1. 要旨
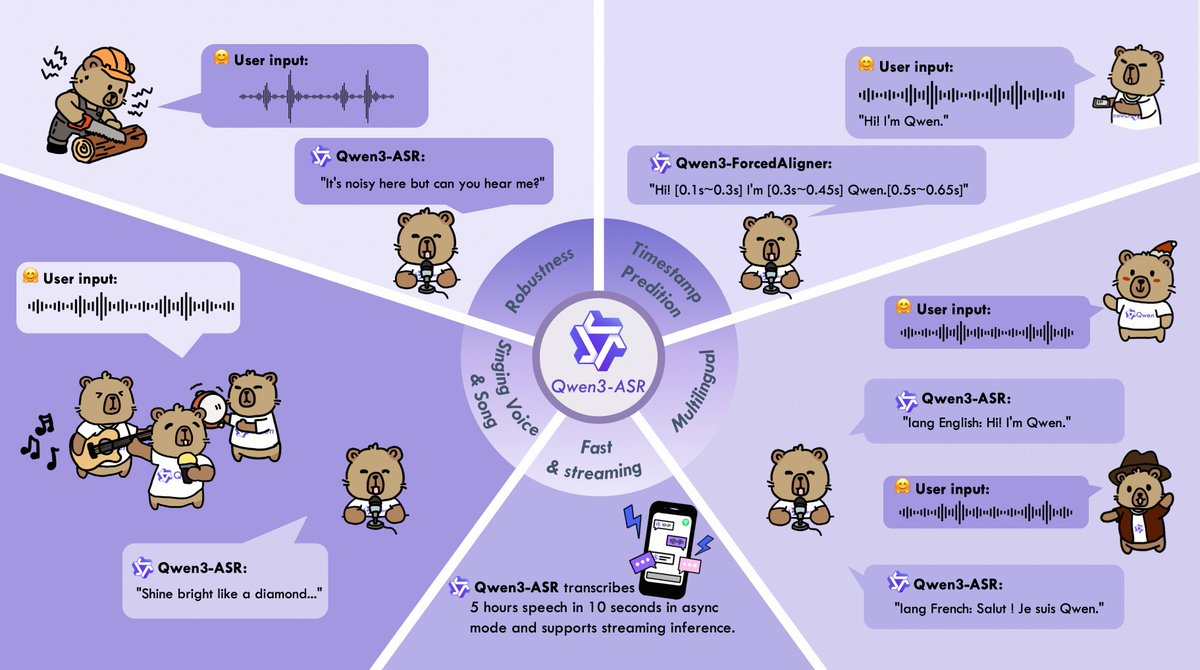
Qwen3-ASRおよびQwen3-ForcedAlignerは、「ノイズが多く、複雑で制御不能」な実際の録音シナリオ向けのオープンソースの音声モデルおよびアライメントコンポーネントです。 多言語自動認識、ノイズや残響への強靭性、約20分までの長時間音声処理、特定の言語での単語/フレーズレベルの高精度タイムスタンプ整合能力に注力し、バッチ文字起こし、ストリーミング字幕作成、オンラインサービス向けのオープンソース推論および微調整エンジニアリングスタックを備えています。
2. コア機能
- 多言語自動言語認識:52言語および方言・アクセント(30言語+22方言/アクセント)をカバーし、自動言語IDをサポートしています。
- 複雑なオーディオの堅牢性:ノイズ、複数人、遠方場、残響、その他のシナリオに最適化; また、ボーカルや曲クリップなど、より「非典型的」な音声形式もカバーしています。
- 長時間の音声サポート:単一処理で最大約20分まで可能で、長時間の録音セグメンテーションによるコンテキストの崩れやエンジニアリングの複雑さを軽減します。
- 単語/フレーズレベルのタイムスタンプ:Qwen3-ForcedAlignerで11言語で高精度な整合を提供し、字幕、検索、レビューの操作をより使いやすくします。
- エンジニアリングスタック:vLLMのバッチ処理、ストリーミング、非同期サービス機能を含む完全かつオープンソースの推論および微調整システムを提供し、オンライン接続やテストを容易にします。
3. 設置
- コードを取得:リポジトリをクローンした後、READMEを押して依存関係をインストールします(分離された環境と固定バージョンの使用が推奨されます)。
- 重みを取得する:Hugging FaceまたはModelScopeから適切なモデルと構成を選択します。
- 運用モード:シナリオに応じてバッチオフライン文字起こし(バッチ)、オンラインストリーミング(ストリーミング)、または非同期サービング(非同期サービング)を選択し、スループットに応じて並行性とキューを設定します。
4. 典型的なユースケース
- コールセンター/会議の書き起こし:ノイズ、アクセント、複数のスピーカーの場合、バッチでの文字起こしおよび品質検査サンプリング。
- 字幕制作と再生取得:ForcedAlignerを使って単語やフレーズレベルのタイムスタンプを生成し、「ドットジャンプ」をサポートし、フォローアップをハイライトし、クリップレビューを行います。
- 短いビデオおよび音楽素材の処理:背景音楽、明らかなリズム、歌唱クリップを含む資料の文字起こしおよび解説出力。
- 長時間の録音アーカイブ:10〜20分の音声のセグメント化戦略を簡素化し、タイムスタンプと組み合わせて重要なポイントを素早く特定します。
- エッジ・トゥ・クラウドのミキシング:エッジエンドが初期のスクリーニングやノイズリダクションの前処理を行い、クラウドはバッチ/非同期サービスを使って中央で文字起こしと整合を行います。
5. 生態系と競合製品
- 生態学的入口:GitHubはコードと紙の資料を提供しています。 Hugging Face / ModelScopeは、モデルコレクションやオンラインデモを提供し、評価と統合を容易にしています。
- 競合製品アイデア:「強アライメント」分野において、一般的な解決策にはMFAやCTC/CIFスタイルのアライナーを使ったアライナーが含まれます。 Qwen3-ForcedAlignerは、字幕の正確さと校正の最適化を目的としており、アライメント機能も設置可能なコンポーネントとして機能しています。 それでもA/Bには自分のデータセットを使うことが推奨されます(アクセント、ノイズ、話し方、ドメイン用語の違いが結果に大きく影響します)。
6. 制限事項と注意事項
- 計算能力とコスト:多言語、長尺音声、高精度アライメントは推論遅延とリソース占有を増加させ、スループット評価と弾力的スケーリング設計が必要です。
- データ分布バイアス:極端なアクセント、強い残響、重なり合う声、ドメイン用語、資源の少ない言語は誤認やタイムスタンプドリフトを引き起こす可能性があるため、手動レビューのクローズドループ導入が推奨されます。
- 長音音声戦略:たとえ20分の単一処理に対応しても、超長尺映像では境界誤差を減らすためにセグメンテーション、重なりウィンドウ、後処理スプライシングを組み合わせることが推奨されます。
- アライメント言語範囲:ForcedAlignerの高精度アラインメントは現在、11言語カバレッジを重視しています。 他の言語は文や段落レベルのタイムスタンプで検索し、必要に応じて補足できます。
7. プロジェクトアドレス
https://github.com/QwenLM/Qwen3-ASR
8. よくある質問
Q: Qwen3-ASRは52言語・方言の自動言語識別をサポートしていますか?
A: はい、30言語と22の方言・アクセントを含み、言語を自動的に認識して文字起こしが可能です。
Q: Qwen3-ASRは騒がしい環境や、バックグラウンドミュージックや歌声を伴うリアルオーディオにも対応できますか?
A: 目的はノイズや複雑な音声の堅牢性を向上させること、曲やボーカルクリップへの適応性を含みますが、実際の映像をサンプリングすることをおすすめします。
Q: Qwen3-ASRは1セッションでどれくらいの時間を処理できますか?
A: Nominalは約20分/時間の処理をサポートします。 より長いクリップは、セグメント化やウィンドウの重なり戦略と組み合わせて推奨されます。
Q: Qwen3-ForcedAlignerの「単語/フレーズレベルのタイムスタンプ」はどの言語で利用可能ですか?
A: 現在の重点は、字幕作成、検索、校正に適した高精度アラインメント機能の提供にあります。
Q: Qwen3-ForcedAlignerはMFA/CTC/CIFスタイルのアライナーと比べてどのような価値がありますか?
A: アライメント機能を直接統合されたエンジニアリングコンポーネントにまとめ、ワード/フレーズレベルのタイムスタンプの正確性と安定性に向けたものに注力すること。 最終的には、あなたのタスクデータの比較が優先されます。
Q: 本番環境で推論・微調整のツールチェーンはありますか?
A: vLLMのバッチ処理、ストリーミング、非同期サービスをカバーする完全なオープンソーススタックを提供し、展開や反復を容易にするための関連プロセスの微調整も含まれます。