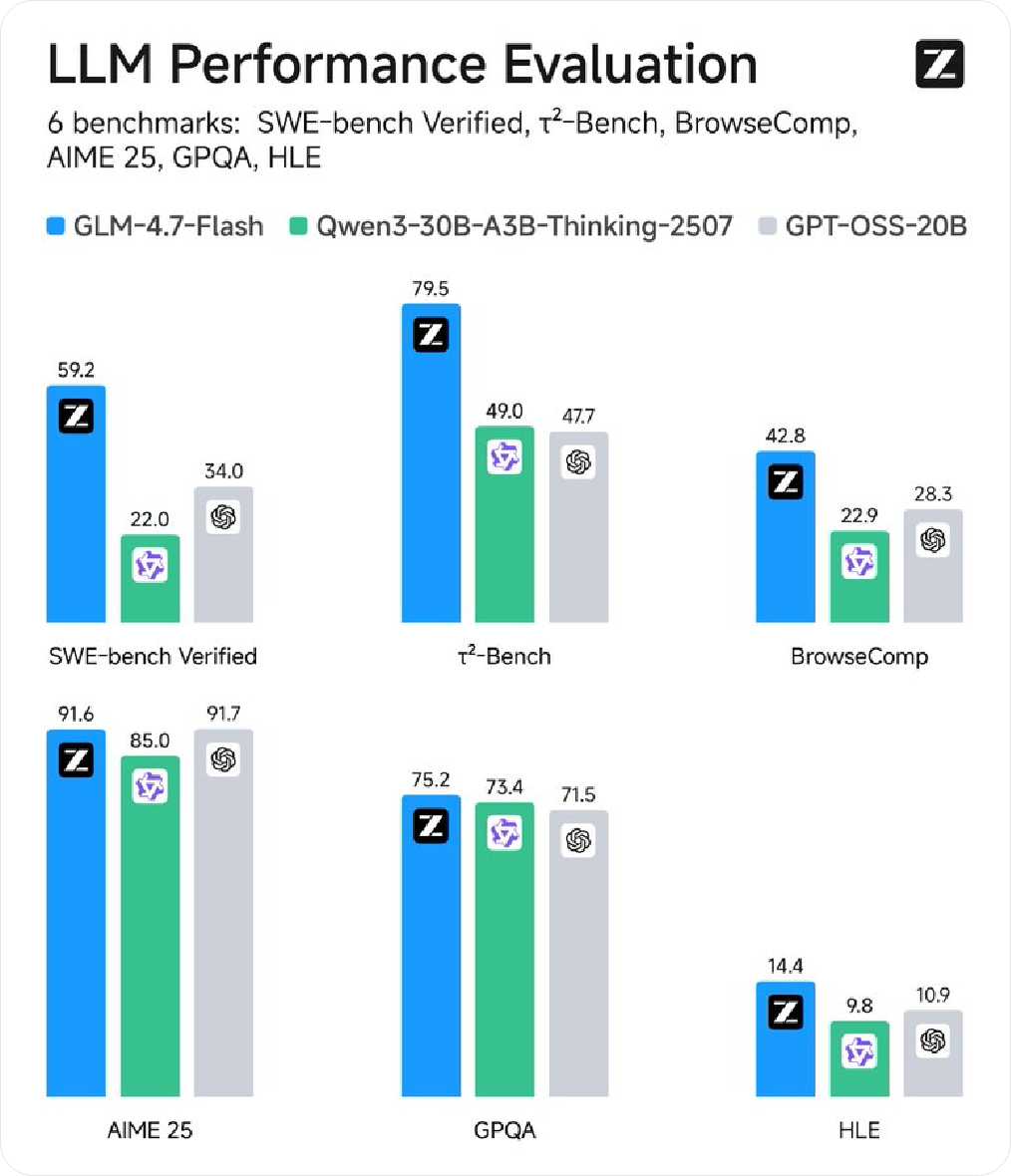
Z.ai 相关账号在 X 发布信息,介绍新模型 GLM-4.7-Flash,定位为“本地 coding 与 agentic assistant”,强调在 30B 级别中兼顾高性能与高效率,适合作为轻量化部署选项。同步信息显示,模型权重已在 Hugging Face 提供,并支持通过 Z.ai 的 API 调用。
官方开发者文档将 GLM-4.7-Flash 描述为免费层模型,标注“1 并发”限制;同时提供 GLM-4.7-FlashX 作为“更高速且更经济”的可选版本。除编程外,公开介绍还建议其用于创意写作、翻译、长上下文任务与角色扮演等场景。
需要注意的是,“本地运行”的实际门槛仍取决于部署方式与硬件资源;此外,免费层并发与商业使用条件应以平台最新定价与条款页面为准,避免将演示口径误解为通用可用性承诺。
常见问题
Q:GLM-4.7-Flash 的核心定位是什么?
A:GLM-4.7-Flash 主打轻量部署,重点面向本地编码辅助与智能体工作流。
Q:GLM-4.7-Flash 是否提供模型权重下载?
A:GLM-4.7-Flash 权重已在 Hugging Face 的 zai-org 账号下提供。
Q:GLM-4.7-Flash 的 API 是否免费?
A:Z.ai 文档标注 GLM-4.7-Flash 为免费层,但默认限制为 1 并发。
Q:GLM-4.7-FlashX 与 GLM-4.7-Flash 有何区别?
A:公开说明称 GLM-4.7-FlashX 更偏向高速与性价比,面向更高频调用场景。
Q:GLM-4.7-Flash 适合哪些非编程用途?
A:公开介绍提到可用于创意写作、翻译、长上下文任务与角色扮演等。