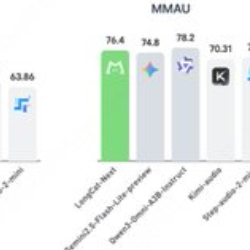
LongCat-Next 오픈 소스 릴리스: 텍스트, 이미지, 오디오를 통합하는 네이티브 멀티모달 모델
- 초록 LongCat-Next는 Meituan의 LongCat 팀이 개발한 오픈 소스 이산형 자기회귀 멀티모달 모델로, 텍스트, 시각 자료, 오디오를 동일한 프레임워크 내에서 통합하는 것을 목표로 합니다. 프로젝트는 약 68.5B의 총 매개변수와 약 3B의 활성화 매...
Admin •
129
- 초록 LongCat-Next는 Meituan의 LongCat 팀이 개발한 오픈 소스 이산형 자기회귀 멀티모달 모델로, 텍스트, 시각 자료, 오디오를 동일한 프레임워크 내에서 통합하는 것을 목표로 합니다. 프로젝트는 약 68.5B의 총 매개변수와 약 3B의 활성화 매...
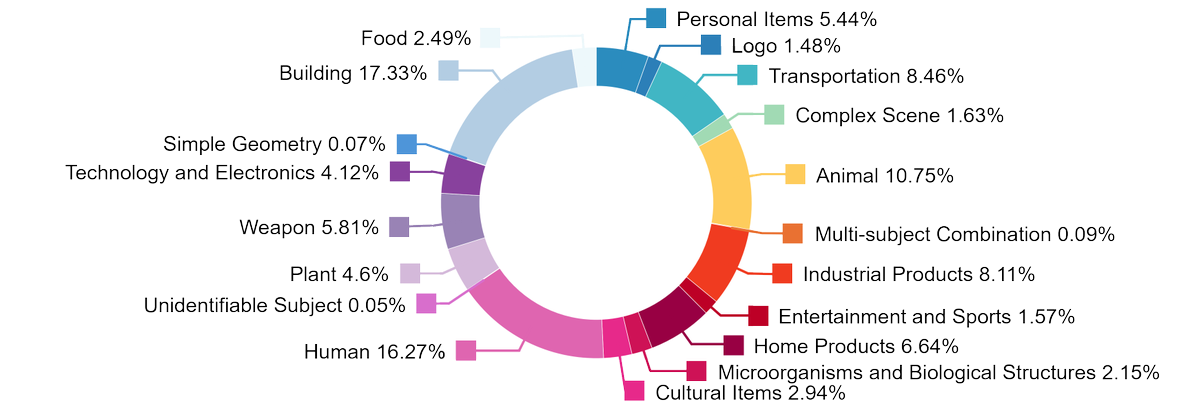
1. 초록 HY3D-Bench는 텐센트의 훈위안 팀이 만든 오픈 소스 통합 3D 자산 데이터 생태계로, 3D 생성 분야에서 흔히 겪는 "데이터 희소성, 높은 잡음, 일관성 없는 평가"라는 공통 문제를 완화하는 것을 목표로 하고 있습니다. 이 프로젝트는 세 가지 유형의 ...
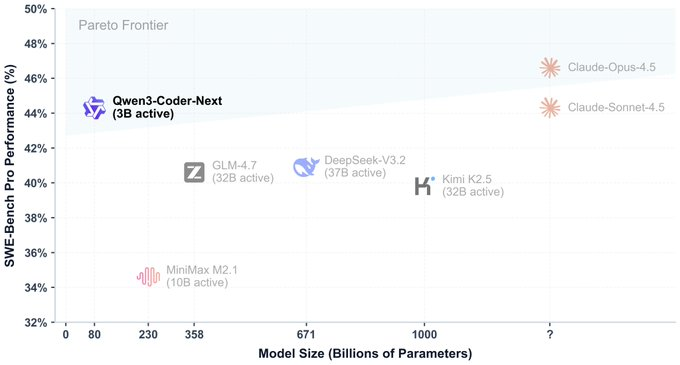
1. 초록 Qwen3-Coder-Next는 Qwen Team에서 출시한 오픈소스 가중 코드 모델로, 코딩 에이전트와 로컬 개발 시나리오에 적합합니다. 핵심 아이디어는 "초희소 MoE + 에이전트 훈련"으로, 총 매개변수 수는 약 80B이지만, 토큰당 활성화되는 매개변수...
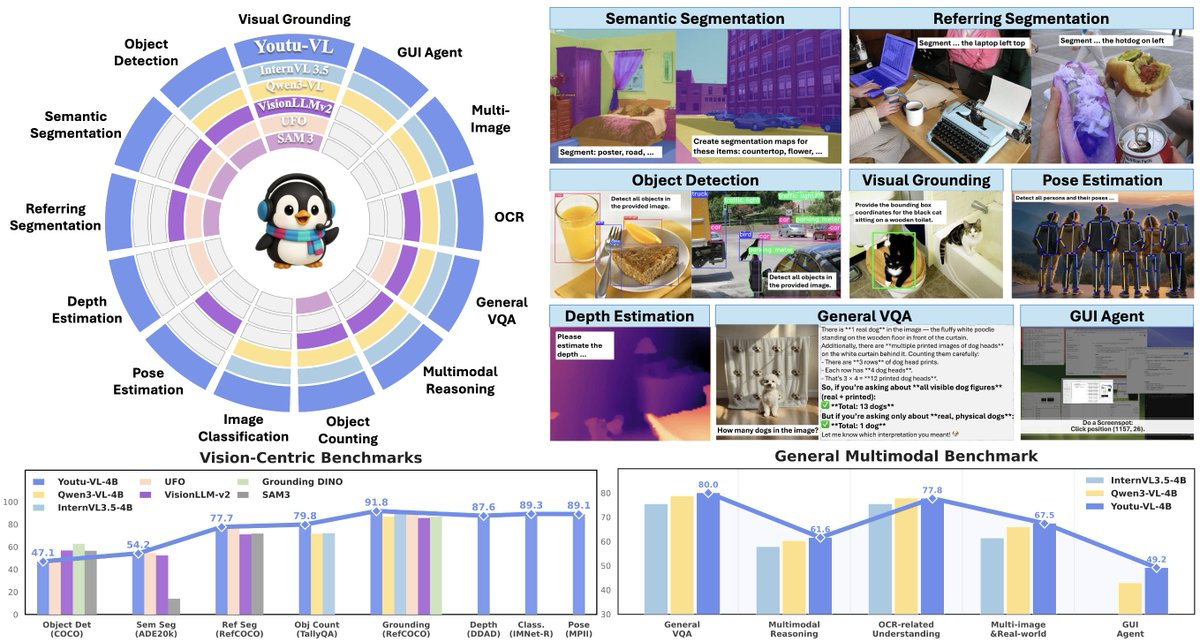
1. 초록 Youtu-VL-4B-Instruct는 Tencent Youtu가 제공하는 4B 매개변수 규모의 소형 시각 언어 모델로, VLUAS(Vision-Language Unified Autoregressive Supervision)를 제안합니다. 이 모델은 "입력에...
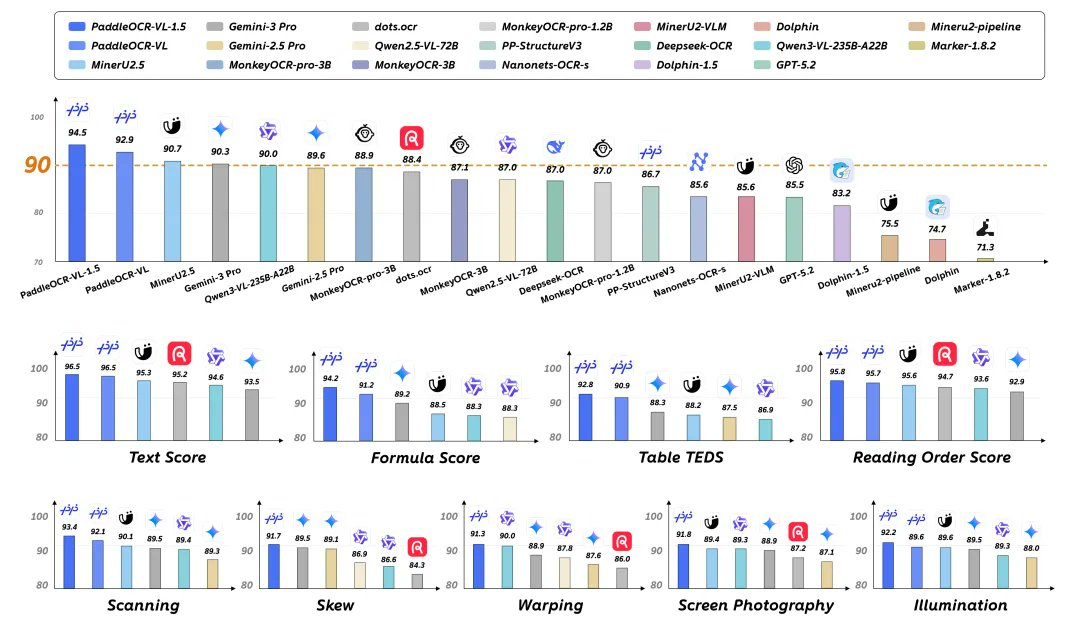
1. 초록 PaddleOCR-VL-1.5는 PaddlePaddle의 오픈 소스 0.9B 파라메트릭 문서 다중 모달 모델로, 레이아웃 위치 지정, 읽기 순서부터 텍스트/표/공식 등 구조화된 분석까지 "굽힘, 왜곡, 기울기, 스크린 촬영, 복잡한 조명"과 같은 실제 획득 ...

1. 초록 PaddleOCR은 PaddlePaddle을 기반으로 한 오픈 소스 OCR 및 문서 해석 도구로, 이미지와 PDF에 대해 "텍스트 인식 + 구조화된 추출"을 제공합니다. 3.x 시스템에서 PP-OCRv5는 일반적인 텍스트 감지 및 인식을 포함하며, PP-St...