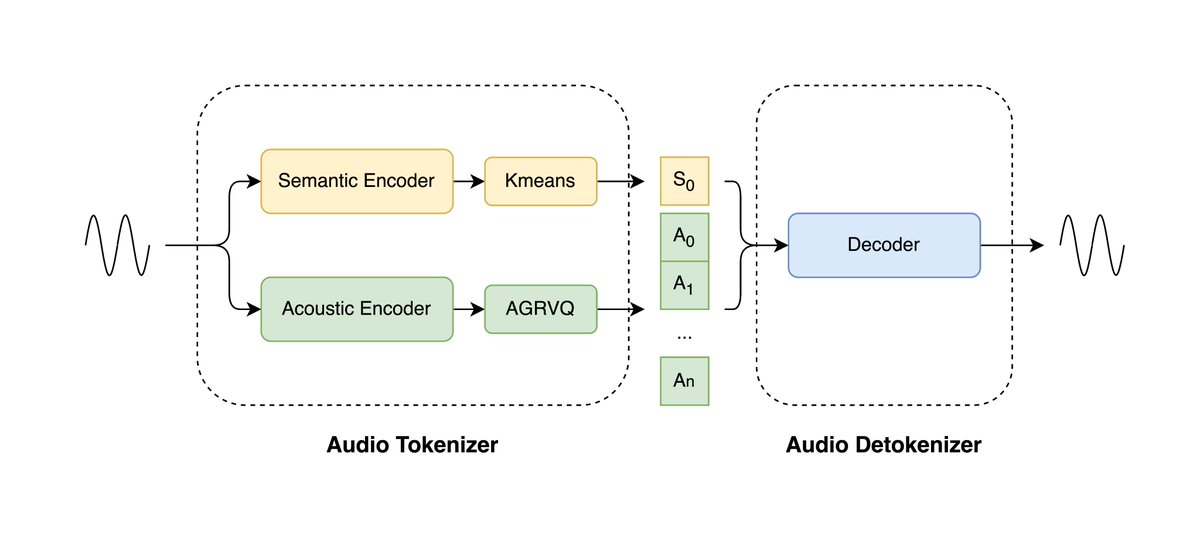
LongCat-Audio-Codec 오픈 소스: 대규모 음성 모델을 위한 초저비트레이트 오디오 코덱
I. 요약 LongCat-Audio-Codec은 Meituan LongCat 팀이 개발한 오픈소스 오디오 코덱 솔루션으로, 음성 대규모 모델(LLM)에 최적화되어 있습니다. 이 프로젝트는 듀얼 토큰 아키텍처를 활용하여 의미 정보와 음향 정보를 동시에 모델링하여 0.43...
Admin •
137
I. 요약 LongCat-Audio-Codec은 Meituan LongCat 팀이 개발한 오픈소스 오디오 코덱 솔루션으로, 음성 대규모 모델(LLM)에 최적화되어 있습니다. 이 프로젝트는 듀얼 토큰 아키텍처를 활용하여 의미 정보와 음향 정보를 동시에 모델링하여 0.43...

I. 요약 Qwen3Guard는 Alibaba Cloud Qwen 팀이 출시한 오픈소스 보안 보호 시스템으로, 추론 및 출력 과정에서 대규모 언어 모델의 보안을 향상시키도록 설계되었습니다. 이 시스템은 Qwen3-4B-SafeRL 강화 학습 정렬 모델과 Qwen3Gua...
I. 요약 HunyuanImage 3.0은 텐센트 Hunyuan의 오픈소스 네이티브 멀티모달 텍스트-이미지 변환 모델입니다. MoE 아키텍처와 트랜스퓨전 방식을 활용하여 텍스트와 이미지 학습을 통합합니다. 공식 정보에 따르면, 이 모델은 80바이트 이상의 매개변수를 제...

I. 요약 Hunyuan3D-Part는 Tencent Hunyuan의 오픈 소스 컴포넌트 수준 3D 형상 생성 및 분해 솔루션입니다. P3-SAM (네이티브 3D 파트 분할)과 X-Part (제어 가능한 파트 생성)로 구성되어 있으며, 학습 과정에서 2D SAM에 의존...

I. 요약 Qwen3-VL은 알리바바 클라우드 Qwen 팀이 개발한 오픈소스 비전 언어 모델입니다. 이미지, 비디오, 텍스트에 대한 통합적인 이해와 추론을 위해 설계되었습니다. 주요 특징으로는 256KB의 네이티브 컨텍스트(최대 1MB까지 확장 가능), 최대 약 2시간...
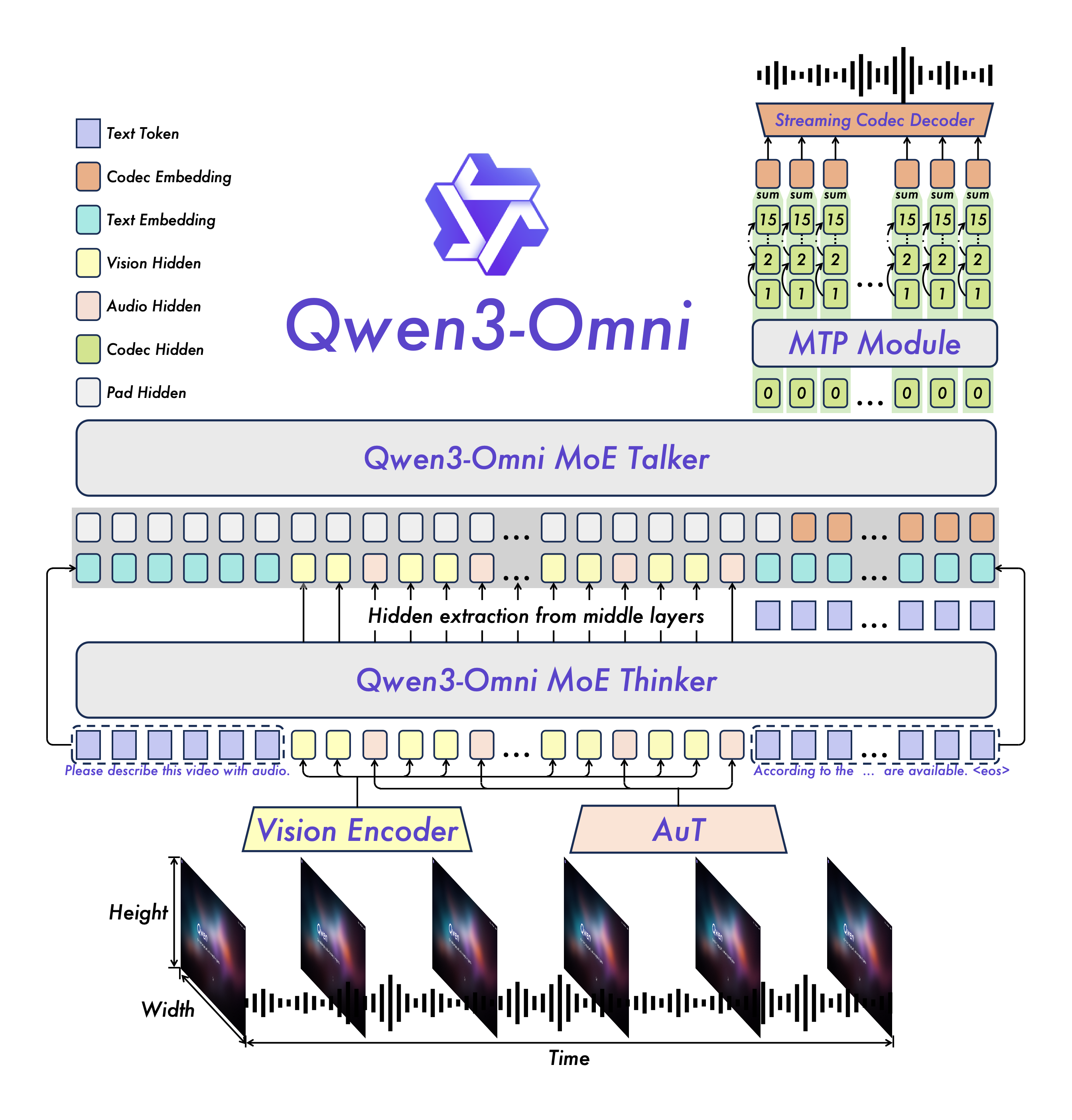
Qwen3-Omni는 멀티모달 AI와 엔드 투 엔드 추론을 결합합니다. 단일 모델이 텍스트, 이미지, 오디오 및 비디오의 입력과 출력을 통합하여 속도와 정확성의 균형을 유지합니다. 공개 테스트에서 Qwen3-Omni는 광범위한 오디오 및 비디오 벤치마크에서 최고의 결과...