
디즈니는 OpenAI와 3년간의 소라 라이선스 계약을 체결하고 10억 달러를 투자했습니다
월트 디즈니 컴퍼니와 OpenAI는 3년간의 콘텐츠 라이선스 및 전략적 협력 협약을 체결했으며, 디즈니는 소라 플랫폼에서 최초의 주요 콘텐츠 라이선스 파트너가 되었습니다. 이 계약은 Sora와 ChatGPT Images가 사용자 텍스트 프롬프트를 기반으로 디즈니, 마블...
Admin •
98
월트 디즈니 컴퍼니와 OpenAI는 3년간의 콘텐츠 라이선스 및 전략적 협력 협약을 체결했으며, 디즈니는 소라 플랫폼에서 최초의 주요 콘텐츠 라이선스 파트너가 되었습니다. 이 계약은 Sora와 ChatGPT Images가 사용자 텍스트 프롬프트를 기반으로 디즈니, 마블...
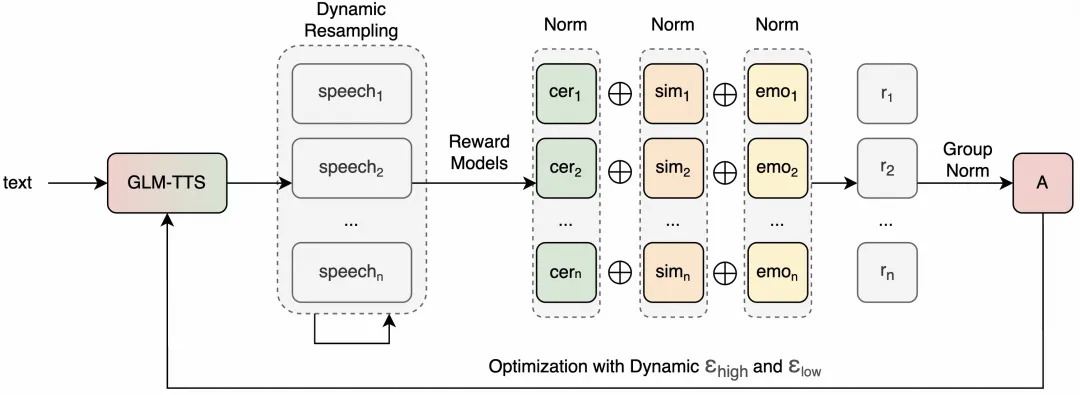
Zhipu AI는 공식적으로 출시되었고, 산업용 음성 합성 시스템인 GLM-TTS를 오픈소스로 제공했습니다. 시스템은 약 3초간의 음성 샘플을 통해 화자의 음색과 말하기 습관을 학습할 수 있으며, 일반 독서, 감정 더빙, 교육 평가, 전자책, 오디오 고객 서비스 등 실...

텐센트는 해외 소셜 플랫폼 공식 계정을 통해 대형 모델 브랜드 "텐센트 훈위안"이 공식적으로 "텐센트 HY"로 이름을 변경했다고 발표했으며, 이는 "동일한 강력한 AI, 더 간결한 이름"을 강조하는 의미입니다. 공식 성명은 이번 조정이 주로 브랜드명을 업그레이드하고 단...

구글은 공식 블로그를 통해 Gemini 2.5 플래시와 Gemini 2.5 Pro 텍스트-음성(TTS) 미리보기 모델에 중요한 업그레이드를 했다고 발표했습니다. 이번 업데이트는 감정과 톤의 다양성 향상, 스타일 지침 준수, 다중 캐릭터 대화 시나리오의 일관성을 높이는 ...

OpenAI는 "AI 역량 발전에 따른 사이버 회복력 강화"라는 제목의 최신 보안 발표를 발표했으며, 이는 사이버 보안 분야에서 모델 역량 향상에 중점을 두고 전반적인 사이버 회복력 전략을 제시합니다. OpenAI는 Capture the Flag와 같은 사이버 공격 및...
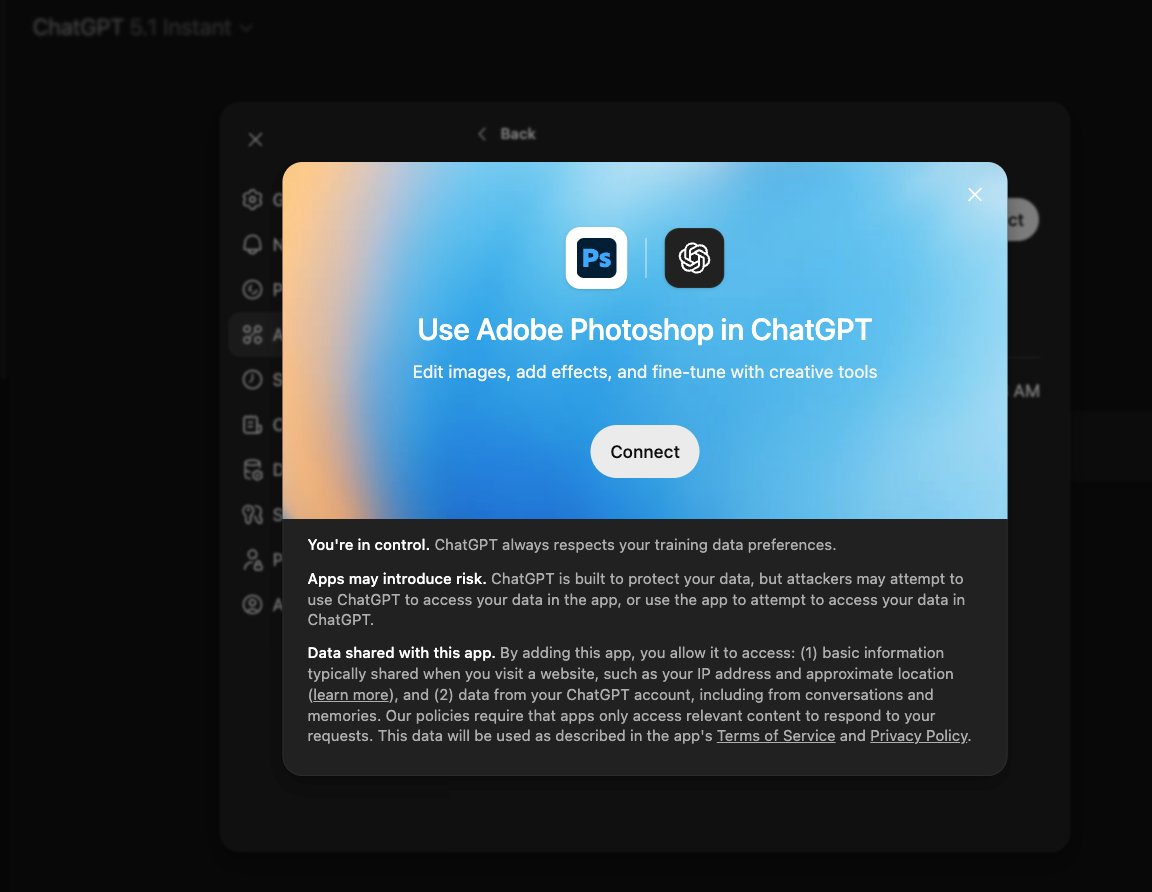
어도비는 이미지 편집과 생성 기능을 연결하는 애플리케이션으로 어도비 포토샵을 ChatGPT에 통합할 것이라고 발표했습니다. 공식 예시에 따르면, 사용자는 채팅에서 요구사항(예: 배경 흐림, 컷아웃, 색상 보정 등)을 직접 입력할 수 있으며, 시스템이 해당 앱을 자동으로...