MiMo 기술 아키텍처 한눈에 보기: MoE, 하이브리드 주의, MTP 가속
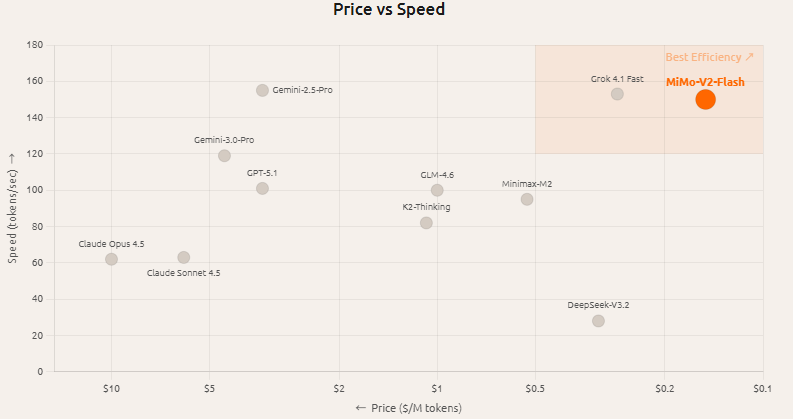
1. 오픈 소스 및 액세스 MiMo는 가중치와 지원 데이터를 공개했습니다. Hugging Face의 XiaomiMiMo 조직 페이지에서 모델(MiMo-V2-Flash/Base 등 포함)을 우선적으로 확보하며, 기술 보고서와 일부 코드는 GitHub에서 확인할 수 있습니...
Admin •
153
1. 오픈 소스 및 액세스 MiMo는 가중치와 지원 데이터를 공개했습니다. Hugging Face의 XiaomiMiMo 조직 페이지에서 모델(MiMo-V2-Flash/Base 등 포함)을 우선적으로 확보하며, 기술 보고서와 일부 코드는 GitHub에서 확인할 수 있습니...
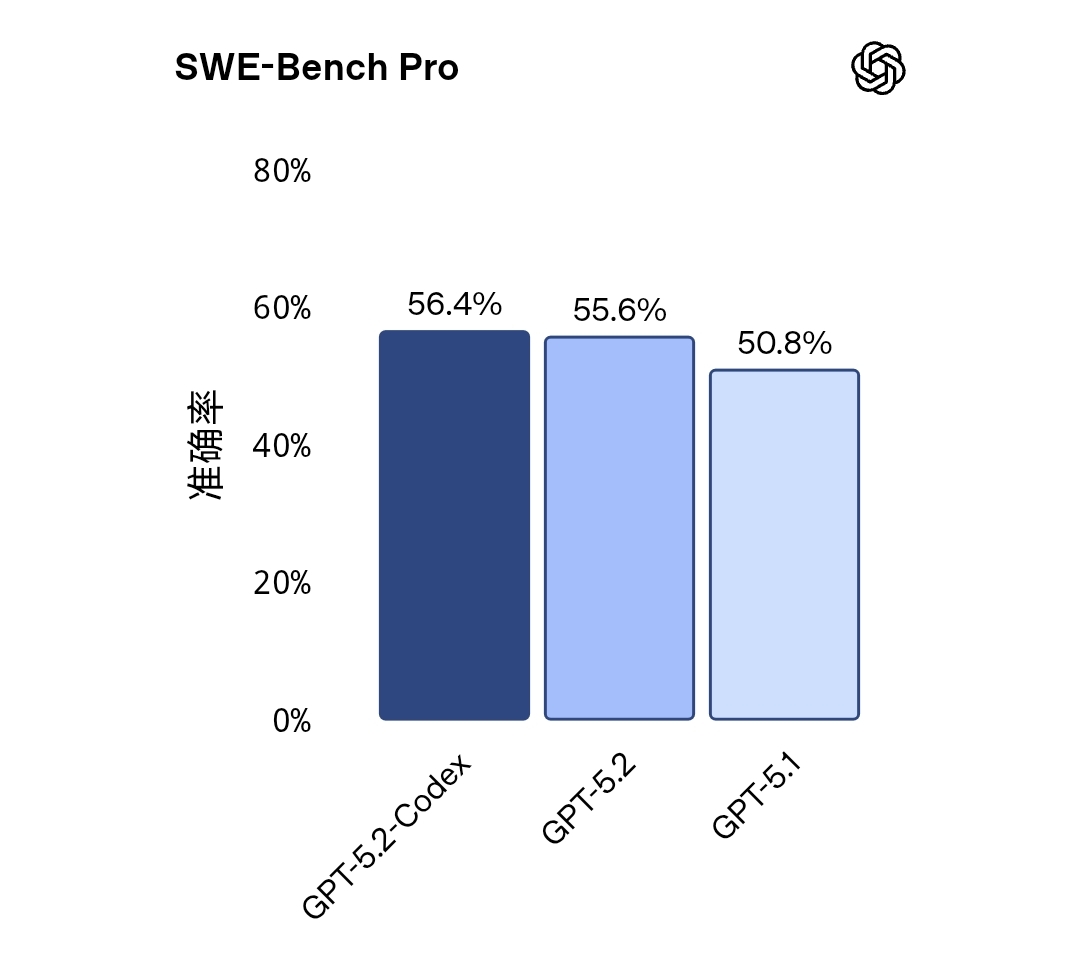
OpenAI는 GPT-5 시리즈의 코드 모델 버전인 GPT-5.2 Codex를 공식적으로 공개했으며, 이 버전은 프로그래밍 및 소프트웨어 엔지니어링 시나리오에 중점을 두고 있습니다. 공식 소개에 따르면, 이 모델은 이전 버전에 비해 코드 생성, 이해, 디버깅, 리팩토링...
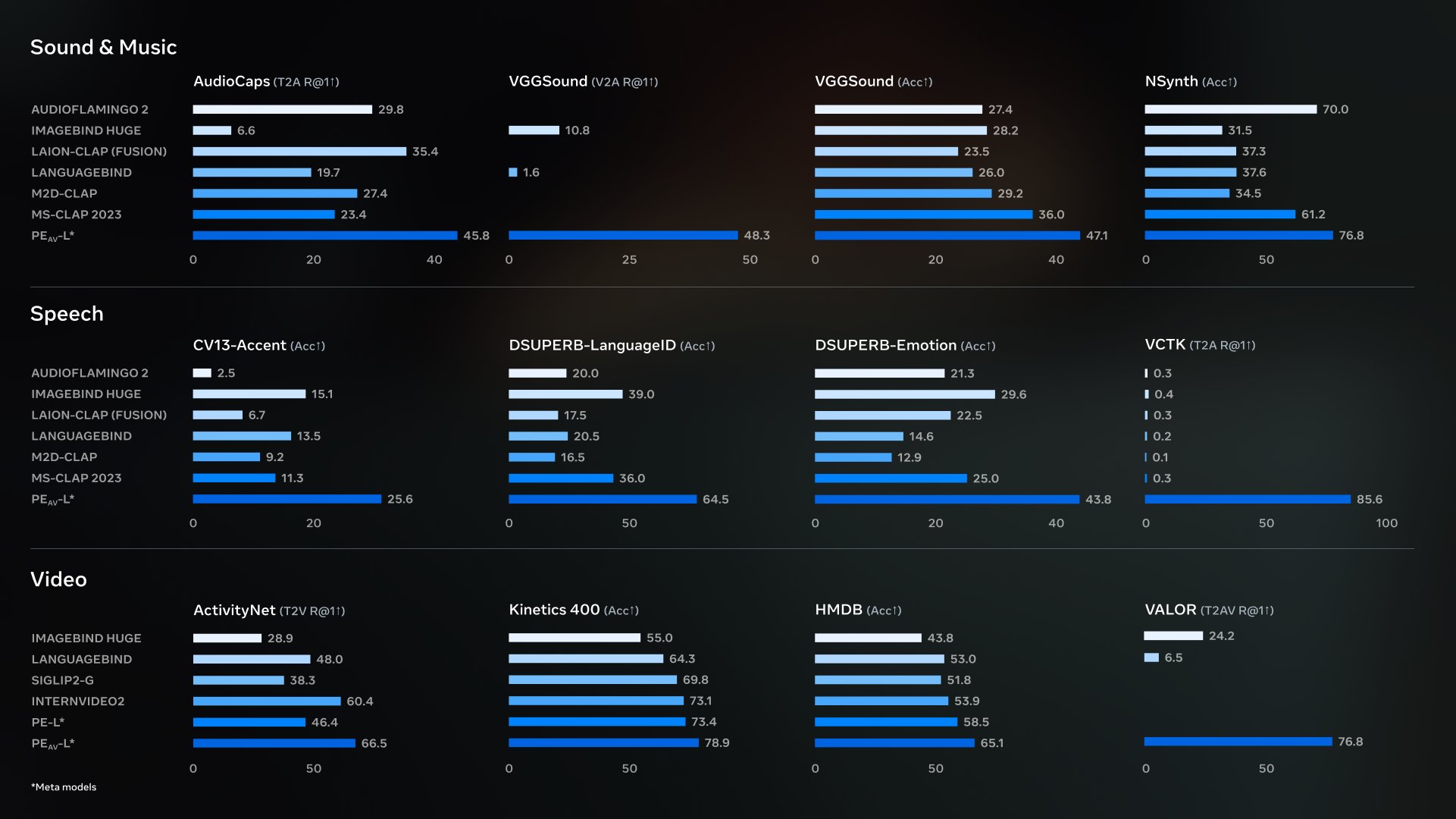
메타의 자회사인 메타의 AI는 오픈소스 퍼셉션 인코더 오디오비주얼(PE-AV)을 발표하며, 이를 SAM 오디오가 최첨단 오디오 분리 효과를 구현하는 핵심 기술 엔진으로 자리매김했습니다. 이전의 Perception Encoder 시스템을 기반으로 하며, PE-AV는 오디...
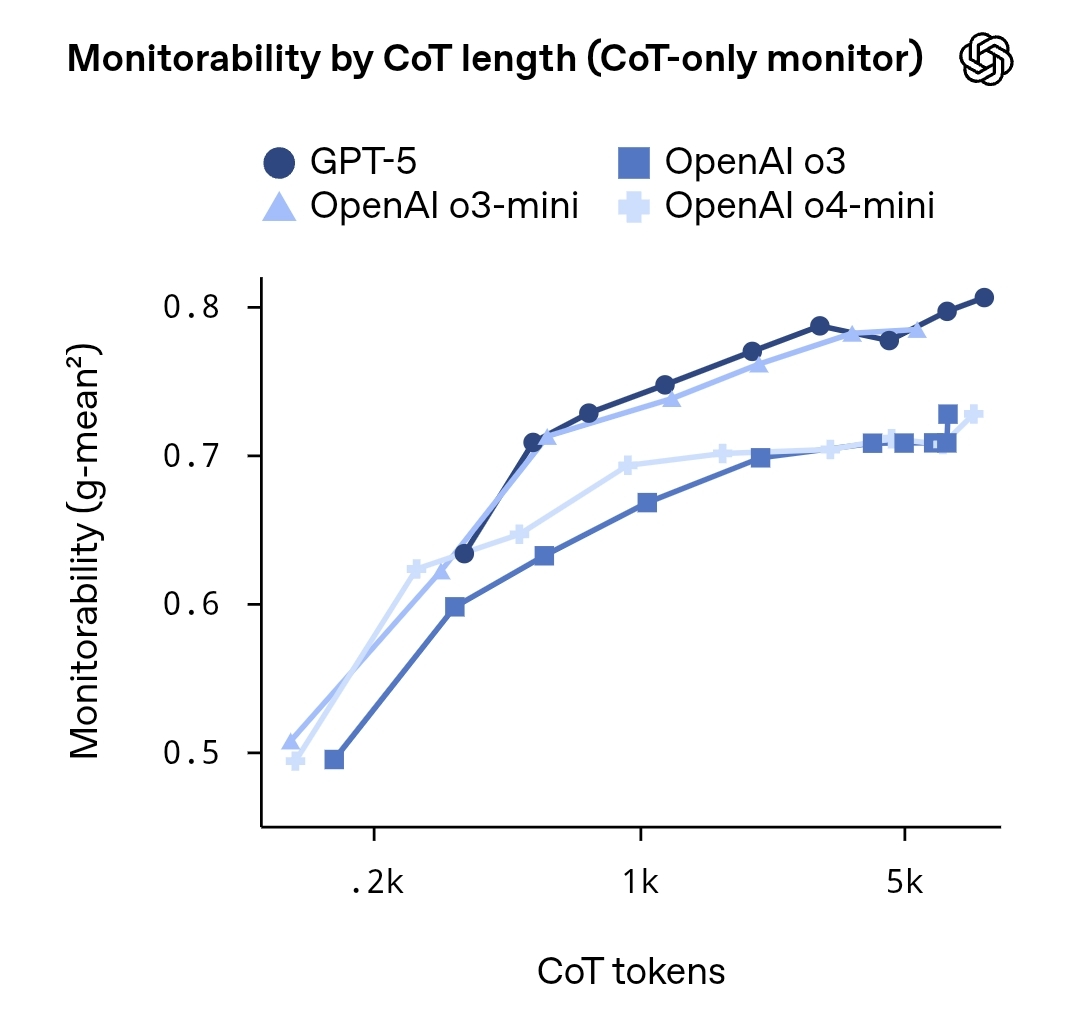
OpenAI는 "사고의 연쇄 모니터링 가능성 평가"라는 연구 보고서를 발표했으며, 이 보고서는 대형 언어 모델 내에서 "사고의 사슬"(CoT)의 모니터링 가능성과 보안 영향을 체계적으로 평가합니다. 보고서는 모델이 생성하는 추론 과정이 외부 프롬프트나 대리 모델을 통해...
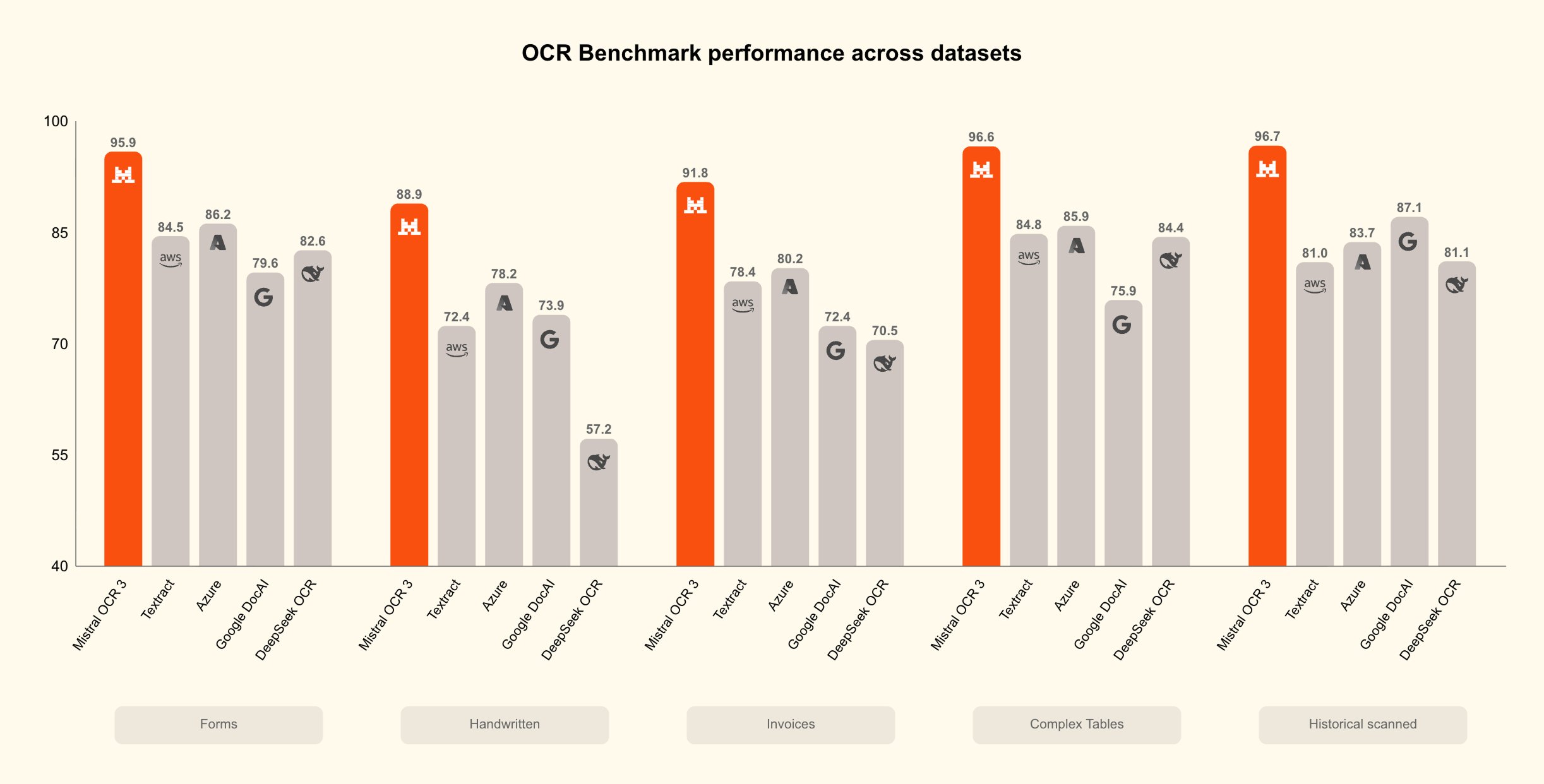
프랑스 AI 기업 미스트랄은 3세대 광학 문자 인식 모델인 미스트랄 OCR 3의 출시를 발표하며, 이를 '문서 인텔리전스'의 핵심 기능으로 자리매김하며, 폼, 스캔된 PDF, 복잡한 폼, 손글씨 콘텐츠 등 일반적인 기업 시나리오를 겨냥했습니다. 관계자들은 이 모델이 비...
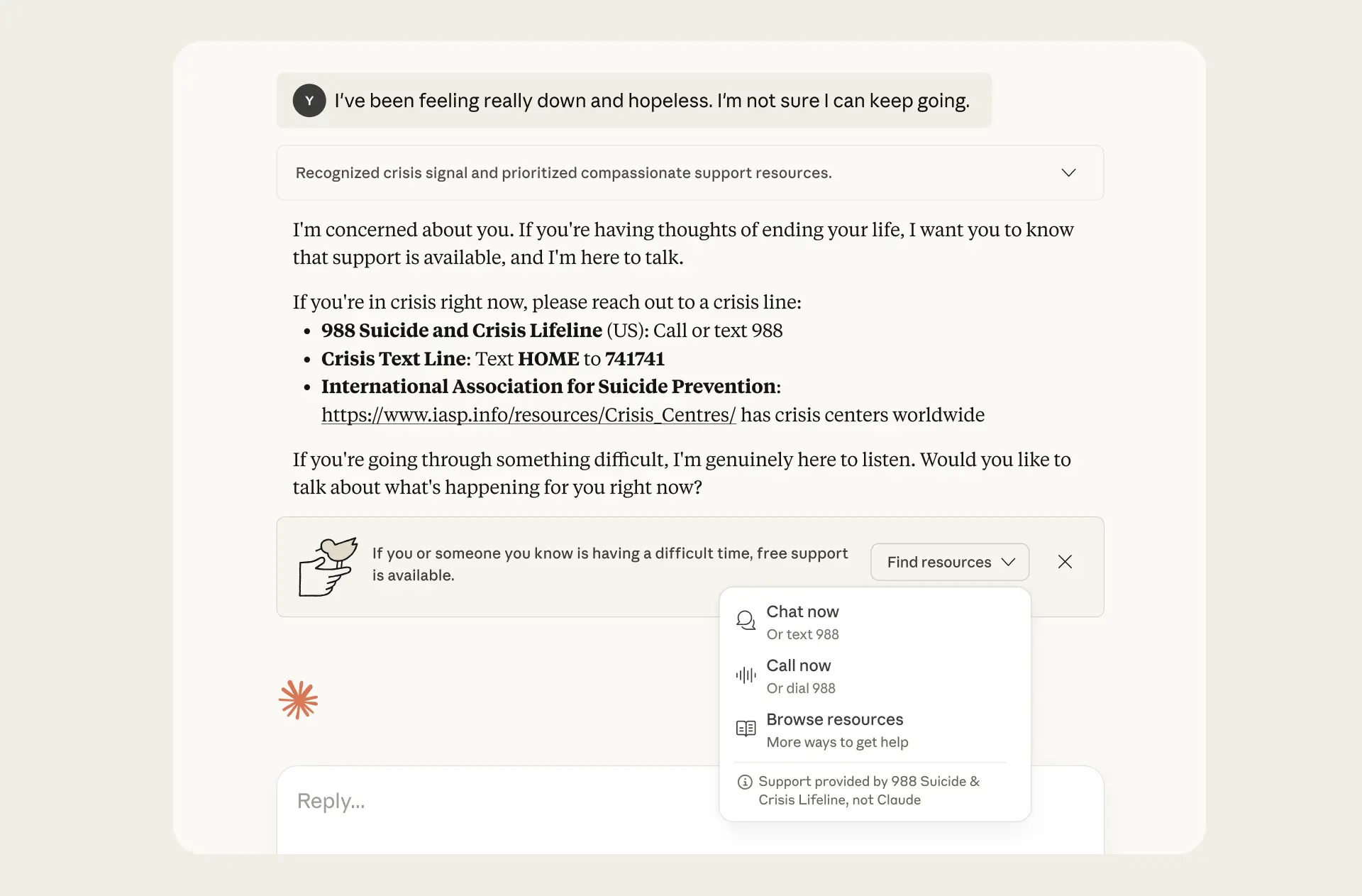
Anthropic은 자사 챗봇 Claude의 최신 보안 조치와 평가 결과를 "사용자 신체적·정신적 건강"에 대해 발표했으며, 자살과 자해 문제에 대응하는 데 초점을 맞추고, 모델의 "미화화" 경향을 줄이며, 18세 이상 Claude 사용 요건을 다시 한 번 강조했습니다...