
앤드류 보스워스는 메타가 새로운 AI 모델을 테스트 중이라고 밝혔으며, 이는 중요한 이정표로 해석되고 있습니다
최근 메타 CTO 앤드류 보스워스는 회사가 내부에서 "초지능 연구소"의 차세대 AI 모델을 테스트하기 시작했으며, 초기 진전을 "유망하다"고 평가했습니다. 이 발언은 Meta가 첨단 AI 연구 방향으로 내놓은 최신 신호로 여겨집니다. 관련 정보에 따르면, 이 모델들은 ...
Admin •
65
최근 메타 CTO 앤드류 보스워스는 회사가 내부에서 "초지능 연구소"의 차세대 AI 모델을 테스트하기 시작했으며, 초기 진전을 "유망하다"고 평가했습니다. 이 발언은 Meta가 첨단 AI 연구 방향으로 내놓은 최신 신호로 여겨집니다. 관련 정보에 따르면, 이 모델들은 ...

블룸버그에 따르면, 애플은 시리를 '캄포스(Campos)'라는 코드명으로 보다 완성도가 높은 AI 챗봇 경험으로 탈바꿈시키고, 아이폰, 아이패드, 맥의 운영체제에 깊이 내장되어 현재의 시리 인터페이스와 상호작용 방식을 대체할 계획입니다. 보고서는 새 버전이 음성 및 텍...
최근 한 개발자가 DeepSeek이 공개한 GitHub 코드베이스에서 "MODEL1"이라는 모델 식별자를 발견하여, DeepSeek이 새로운 모델을 개발하는지 테스트하는지 우려를 불러일으켰습니다. 관련 정보는 개발자가 코드 커밋을 읽고 토론한 결과로 나왔으며, Deep...

OpenAI는 ChatGPT 소비자 구독 계획에서 점진적으로 "연령 예측"을 도입해 계정이 18세 미만 사용자에게 속하는지 여부를 판단하고, 십대에게 더 적합한 경험 및 안전 장치를 자동으로 적용한다고 발표했습니다. OpenAI는 이 메커니즘이 사용자 자기 신고 연령 ...
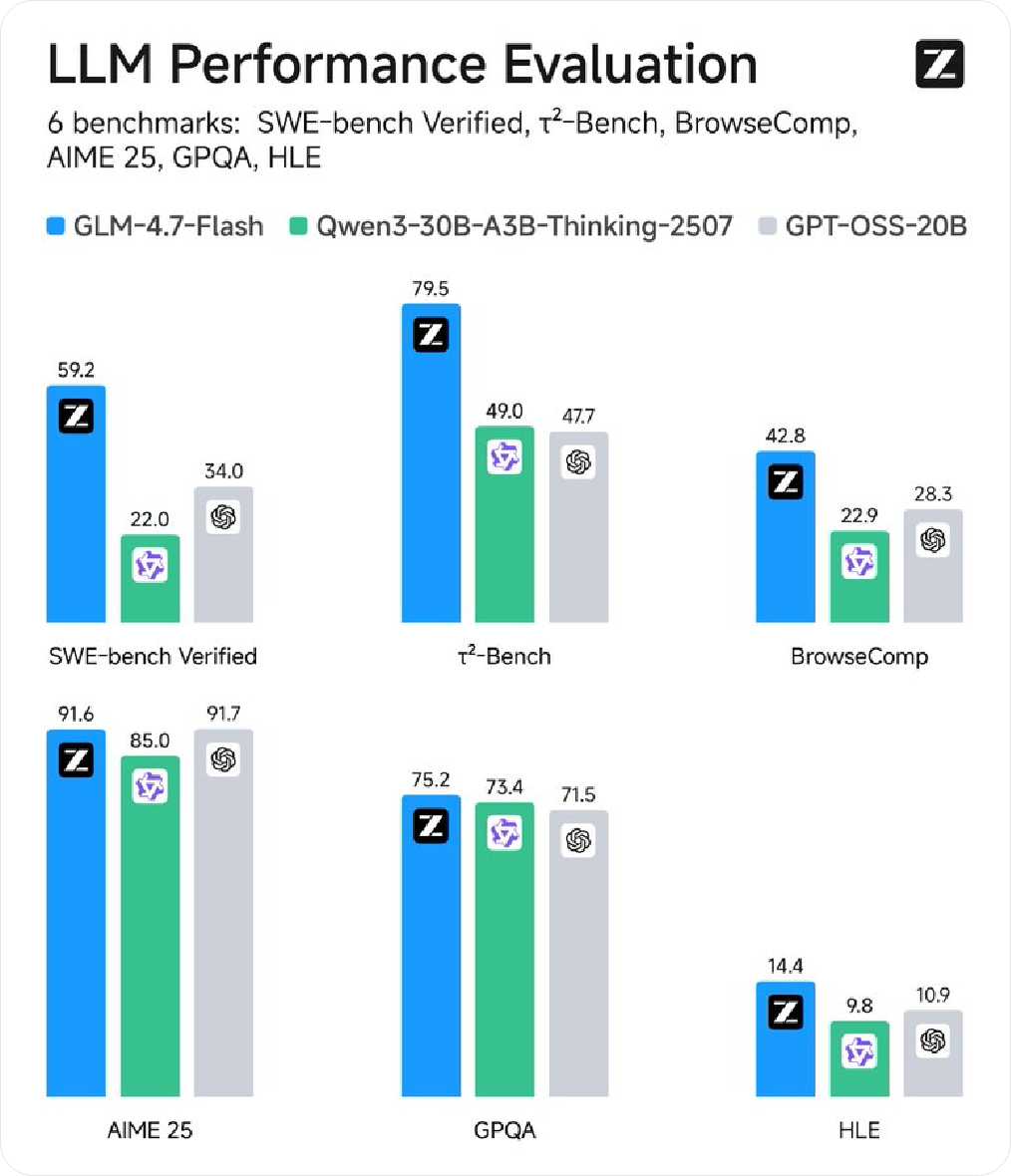
관련 Z.ai 관련 기사들은 X에 관한 정보를 게시하며, "로컬 코딩 및 에이전트 어시스턴트"로 포지셔닝된 새로운 모델 GLM-4.7-Flash를 소개하며, 30B 수준에서 높은 성능과 효율성을 균형 있게 유지하여 경량 배포 옵션으로 적합하다고 강조했습니다. 동기화 정...

최근 소셜 플랫폼에서 퍼진 성명에 따르면 OpenAI는 "마늘"이라는 새로운 모델 버전인 GPT-5.3을 출시할 준비를 하고 있으며, 이전에 공개된 GPT-5.2가 모델의 초기 체크포인트 중 하나일 수 있다고 지적했습니다. 이 주장은 소스가 "과거에는 비교적 신뢰할 만...