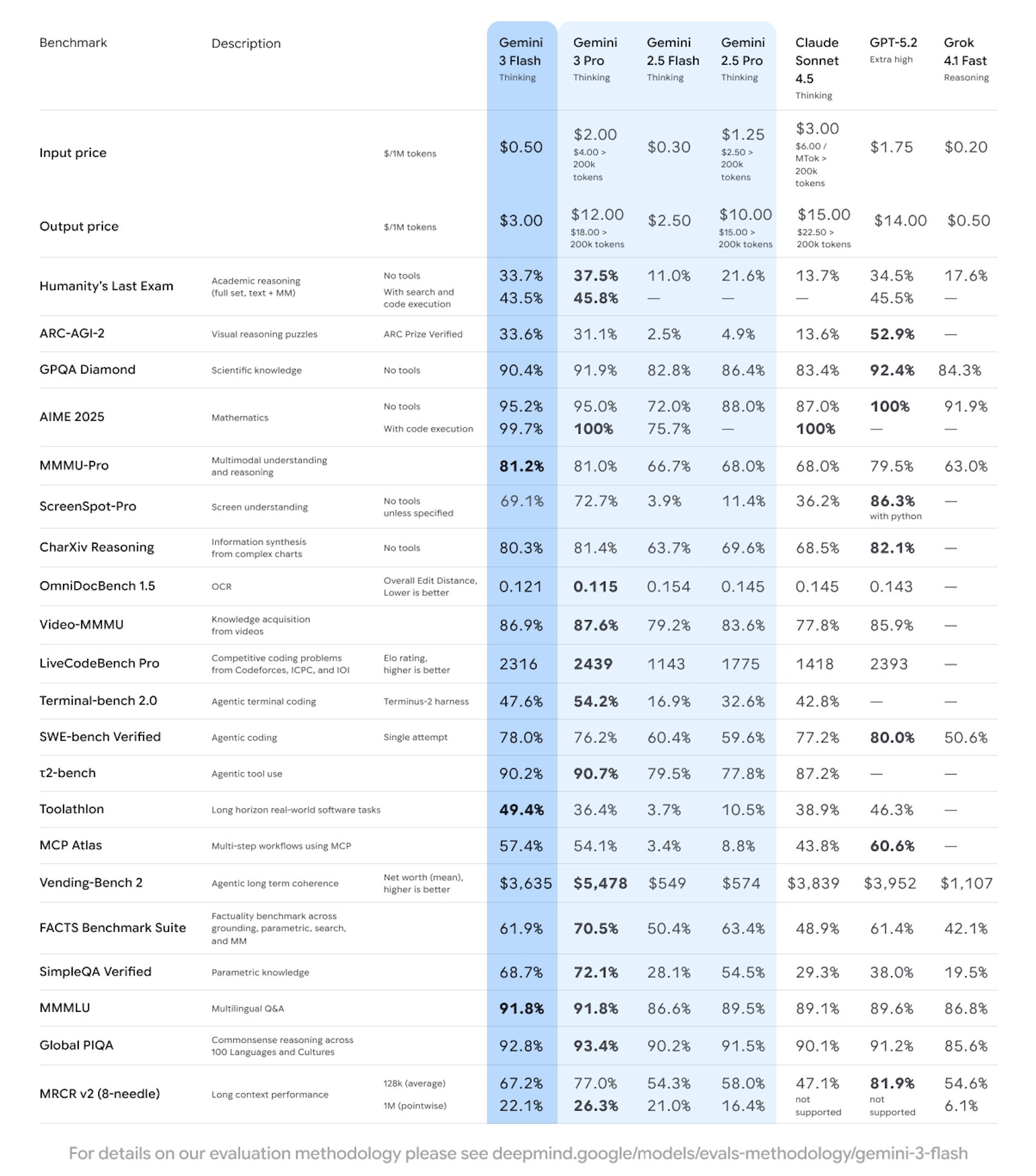
구글은 고속, 저지연, 대규모 가용성에 중점을 둔 신세대 경량 첨단 모델인 Gemini 3 Flash의 출시를 발표했으며, 대부분의 리뷰에서 Gemini 2.5 Pro보다 강력하며 코딩 및 툴 호출 기능을 크게 강화한다고 공식 발표했습니다. 이 모델은 Gemini API/AI Studio, Vertex AI, Gemini CLI에서 미리보기되었으며, 일부 제품 시나리오에서는 동시에 활성화되었습니다. 가격은 백만 토큰 입력당 0.50달러, 산출 백만 토큰(생각 토큰 포함)당 3.00달러입니다.
공식 소개에 따르면, Gemini 3 Flash는 추론과 다중 모드 이해 기능을 유지하면서 처리량과 비용을 최적화하여 고동시성 애플리케이션과 에이전트 워크플로우에 적합합니다. 기업과 개발자는 필요에 따라 '속도/깊이'를 상호 교환할 수 있습니다. 현재 버전은 미리보기 단계이며, 출시 진행에 따라 용량과 할당량이 조정될 수 있습니다. 각 플랫폼의 지역별 이용 가능 여부, 요금 제한, 청구 규칙은 각 플랫폼의 실제 규칙에 따라 달라집니다. 일부 프리미엄 기능이나 더 높은 할당량은 해당 서비스 구독이나 활성화가 필요합니다.
FAQ
Q: 제미니 3 플래시는 무엇이며 어떤 시나리오를 대상으로 하나요?
답변: 이 모델은 제미니 3 시리즈의 고속이자 효율적인 모델로, 코딩, 툴 호출, 멀티모달 추론과 같은 저지연 시나리오에 적합합니다.
Q: Gemini 3 Flash는 2.5 Pro와 어떻게 비교되나요?
답변: 관계자들과 여러 평가에 따르면 대부분의 지표에서 더 강하고 프록시 코딩과 같은 작업에서 더 나은 성과를 낸다고 합니다.
Q: 가격과 청구 방식은 어떻게 되나요?
A: 0.50달러/백만 토큰을 입력하고, 3.00달러/백만 토큰을 출력하며, 출력 가격에는 사고 토큰이 포함됩니다.
Q: 지금 어떻게 사용하나요?
A: Gemini API, AI Studio, Vertex AI, Gemini CLI에서 "preview" 형태로 호출할 수 있으며, 구체적인 할당량과 지역은 각 플랫폼에 따라 다릅니다.
Q: 완전하고 안정적으로 진행되었나요?
답변: 현재 미리보기 단계이며, 용량, 한도, 가용성 범위는 여전히 조정될 수 있습니다.



