Googleは、
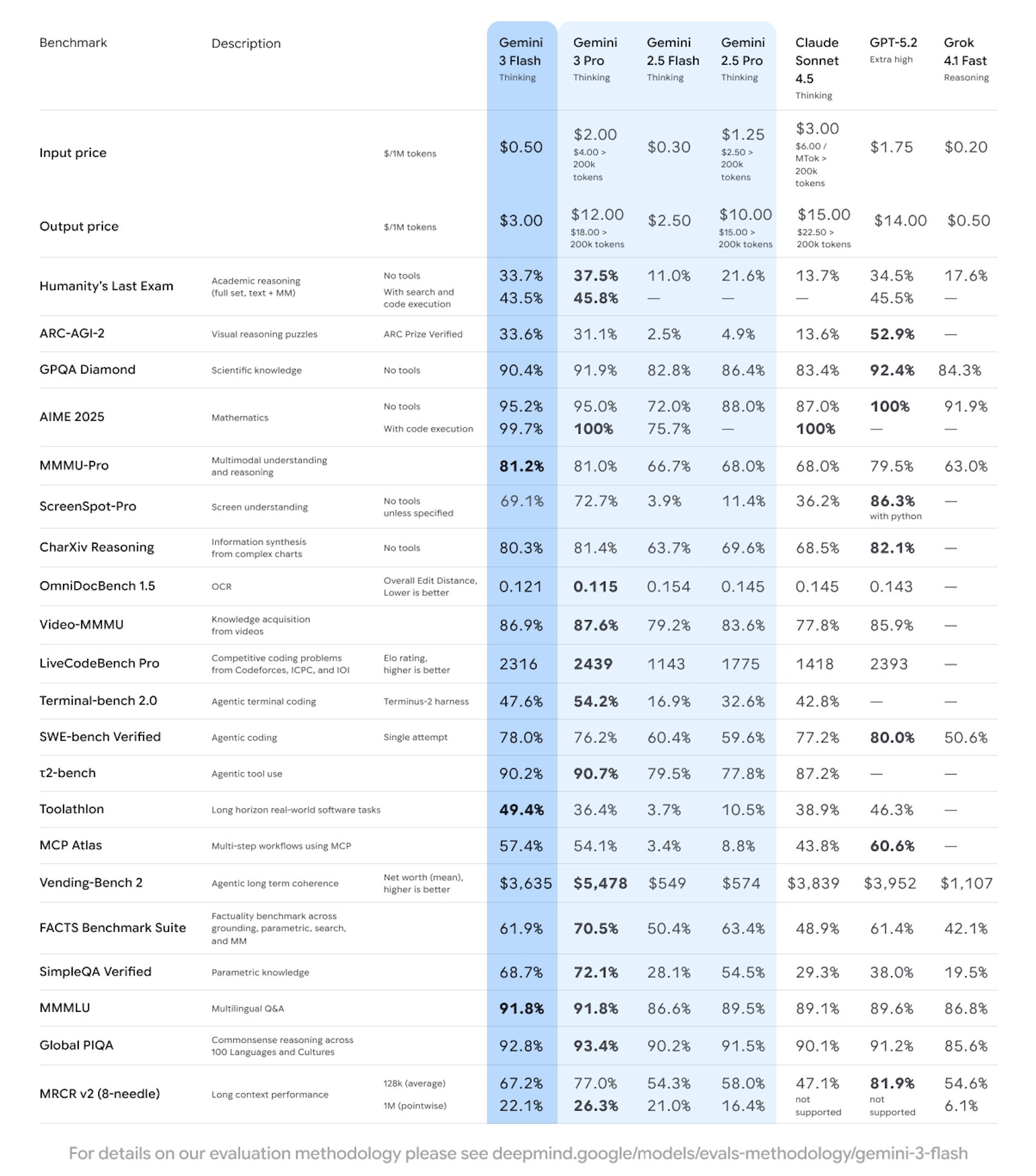
高速・低遅延・大規模利用に特化した新世代の軽量で最先端モデル「Gemini 3 Flash」の発売を発表しました。多くのレビューではGemini 2.5 Proよりも強力で、コーディングやツール呼び出し機能を大幅に強化しています。 このモデルはGemini API/AI Studio、Vertex AI、Gemini CLIでプレビューされており、一部の製品シナリオでは同時に有効化されています。 価格は、入力1百万トークンあたり0.50ドル、出力1百万トークン(思考トークンを含む)あたり3.00ドルです。
公式紹介によると、Gemini 3 Flashはスループットとコストを最適化しつつ、推論やマルチモーダル理解機能を維持し、高並行性アプリケーションやエージェントワークフローに適しています。 企業と開発者は必要に応じて「スピード/深さ」をトレードオフできます。 現在のバージョンはプレビュー段階で、リリースの進行に伴い容量やノルマが調整される可能性があります。 各プラットフォームの地域ごとの利用可能性、料金制限、請求ルールは、各プラットフォームの実際のルールに依存します。 一部のプレミアム機能やより高いノルマは、サブスクリプションや対応サービスのアクティベートが必要です。
FAQ
Q: Gemini 3 Flashとは何か、どのようなシナリオを対象としていますか?
A: これはGemini 3シリーズの高速かつ効率的なモデルであり、コーディング、ツール呼び出し、マルチモーダル推論などの低遅延シナリオに適しています。
Q: Gemini 3 Flashは2.5 Proと比べてどうですか?
A: 関係者や複数の評価では、ほとんどの指標でより強力で、プロキシコーディングなどのタスクでより良いパフォーマンスを発揮していると言われています。
Q: 料金と請求方法は何ですか?
A: 入力は$0.50/百万トークン、出力は$3.00/百万トークン、出力価格には思考トークンが含まれます。
Q: 今はどう使うのですか?
A: Gemini API、AI Studio、Vertex AI、Gemini CLIでは「プレビュー」の形で呼び出せ、具体的なクォータや地域は各プラットフォームによって異なります。
Q: 完全に安定していったのですか?
A: これは現在プレビュー段階であり、容量、制限、可用性の範囲は引き続き調整される可能性があります。



