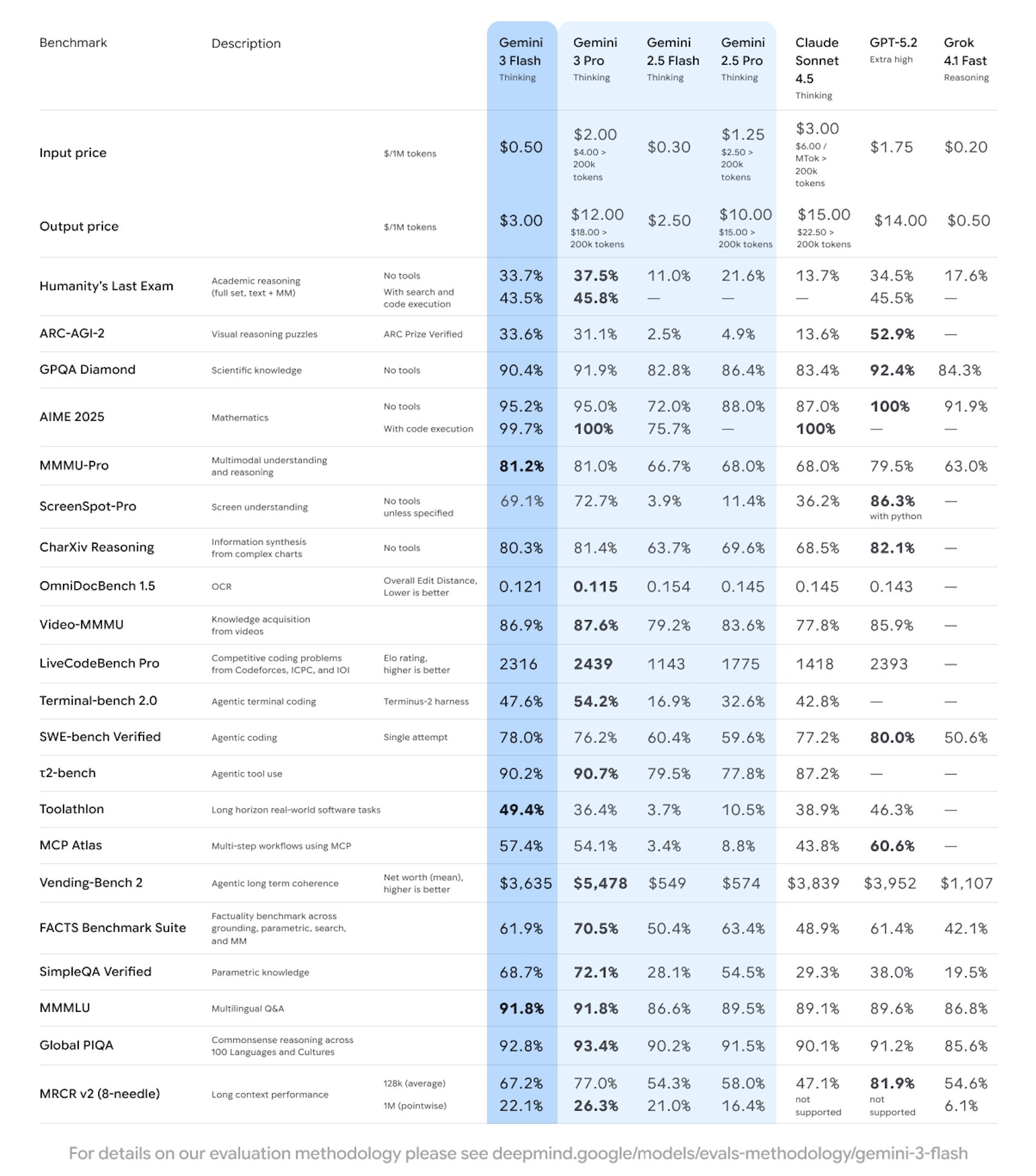
Google announced the launch of a new generation of lightweight cutting-edge model, Gemini 3 Flash, which focuses on high speed, low latency and large-scale availability, and officially says that it is stronger than Gemini 2.5 Pro in most reviews, and significantly strengthens coding and tool call capabilities. The model has been previewed in Gemini API/AI Studio, Vertex AI, and Gemini CLI, and has been enabled simultaneously in some product scenarios. Pricing is $0.50 per million tokens input and $3.00 per million tokens output (including thinking tokens).
According to the official introduction, Gemini 3 Flash optimizes throughput and cost while maintaining inference and multimodal understanding capabilities, making it suitable for high-concurrency applications and agent workflows. Enterprises and developers can trade off "speed/depth" as needed. The current version is in preview, and the capacity and quota may be adjusted as the release progresses. The regional availability, rate limiting, and billing rules of different platforms are subject to the actual rules of each platform. Some premium features or higher quotas require a subscription or activation of the corresponding service.
FAQ
Q: What is Gemini 3 Flash and what scenarios is it aimed at?
A: It is a high-speed and efficient model of the Gemini 3 series, suitable for low-latency scenarios such as coding, tool calling, and multimodal inference.
Q: How does Gemini 3 Flash compare to the 2.5 Pro?
A: Officials and multiple evaluations say that it is stronger on most indicators and performs better on tasks such as proxy coding.
Q: What is the price and billing method?
A: Input $0.50/million tokens, output $3.00/million tokens, and the output price includes thinking tokens.
Q: How to use it now?
A: It can be called in the form of "preview" in Gemini API, AI Studio, Vertex AI, and Gemini CLI, and the specific quota and region are subject to each platform.
Q: Has it been fully and stably?
A: This is currently in preview, and the capacity, limit, and availability range may still be adjusted.



