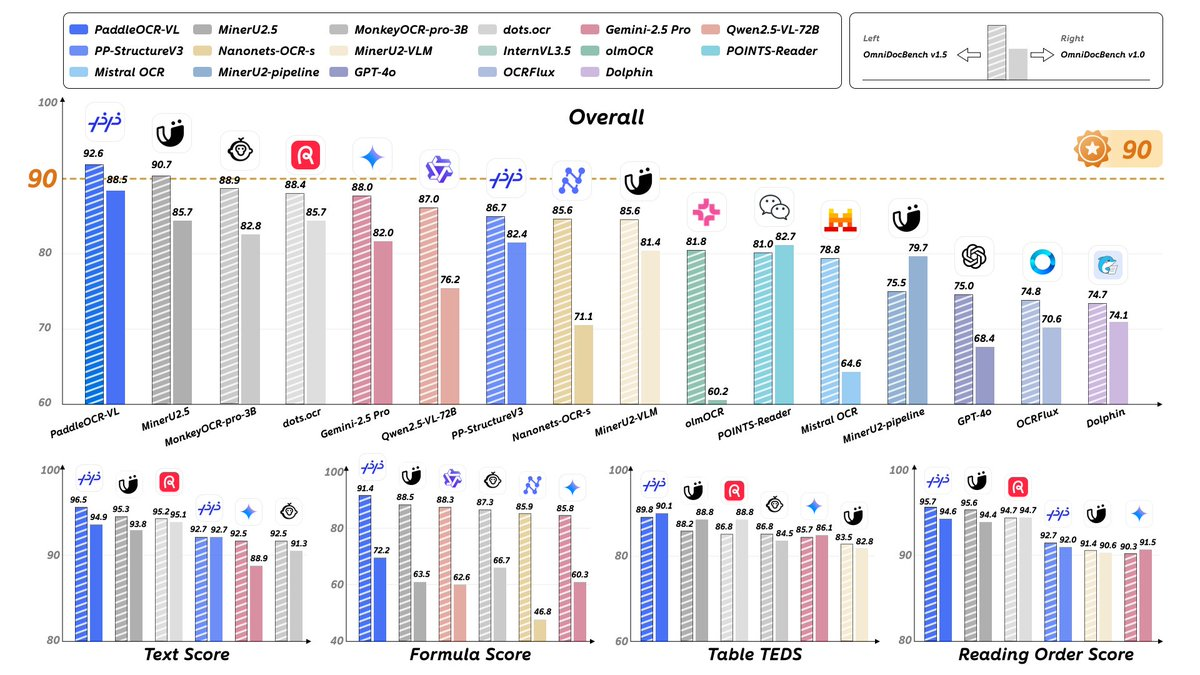
2025년 10월 16일, PaddleOCR은 멀티모달 문서 파싱 모델인 PaddleOCR-VL 출시를 발표했습니다. 이 모델은 버전 3.3.0의 핵심 기능으로 출시되었습니다. 약 0.9B 크기의 이 모델은 NaViT 스타일의 동적 해상도 시각 인코더와 ERNIE-4.5-0.3B 언어 모델을 결합하여 텍스트, 표, 수식, 차트, 필기 등의 요소에 대한 통합 인식 및 구조화된 출력을 구현합니다. OmniDocBench와 같은 공개 및 자체 구축 데이터세트에 대한 공식 평가 결과, PaddleOCR-VL은 페이지 수준 파싱 및 피처 수준 인식 모두에서 최첨단 성능을 달성하거나 능가하는 것으로 나타났습니다.
PaddleOCR-VL은 중국어, 영어, 일본어, 라틴어, 아랍어, 키릴 문자, 데바나가리 문자를 포함하여 109개 언어와 문자를 지원합니다. 실제 환경에서 추론 효율성을 최적화하며, PP-StructureV3 및 PP-OCRv5와 같은 PaddleOCR 구성 요소와 함께 사용할 수 있습니다. 모델과 문서는 GitHub, HuggingFace 및 공식 문서에서 확인할 수 있습니다. 자세한 벤치마크, 시각화 예시 및 배포 방법은 공식 웹사이트를 참조하세요. 데이터셋 버전 및 평가 범위 등 자세한 내용은 저장소 업데이트를 통해 안내해 드리겠습니다.
자주 묻는 질문
질문: PaddleOCR-VL이란 무엇인가요?
A: 텍스트, 표, 수식, 차트, 필기 등을 동시에 처리하고 구조화된 결과를 출력할 수 있는 엔드투엔드 문서 구문 분석을 위한 약 0.9B개의 매개변수를 갖춘 시각적 언어 모델입니다.
Q: 왜 "초소형"이라고 부르나요?
A: 다중 모드 VLM에서 0.9B는 크기가 비교적 작고 추론 효율이 높습니다. NaViT 동적 해상도와 ERNIE-4.5-0.3B를 결합하면 정확도를 유지하면서도 컴퓨팅 성능 요구 사항을 줄일 수 있습니다.
질문: 정말 SOTA에 도달했나요?
A: 저희는 OmniDocBench v1.5/v1.0과 자체 벤치마크에서 전반적인 성능, 읽기 순서, 표, 수식 등 여러 지표를 포괄하는 최고의 결과를 입증했습니다. 결론은 공개 보고서와 모델 카드에 제공된 차트와 설명을 기반으로 합니다.
질문: 어떤 언어와 애플리케이션 시나리오가 지원되나요?
A: 109개 언어를 지원하며 다중 스크립트 조판, 역사 문서, 복잡한 레이아웃 등의 시나리오에 적합합니다. PP-StructureV3의 레이아웃/테이블 구조화 기능과 연동하여 실제 비즈니스 분석을 수행할 수 있습니다.
질문: 어디서 구입할 수 있고, 어떻게 시도할 수 있나요?
A: GitHub은 버전 정보와 명령줄/Python API를 제공하고, HuggingFace는 모델 카드와 온라인 데모 링크를 제공하며, 문서 사이트에서는 배포 및 가속(예: vLLM/sglang 서버) 가이드를 제공합니다.