On October 16, 2025, PaddleOCR announced the launch of its multimodal document parsing model, PaddleOCR-VL, which was released as a core capability in version 3.3.0. This model, approximately 0.9B in size, utilizes a NaViT-style dynamic resolution visual encoder combined with the ERNIE-4.5-0.3B language model to achieve unified recognition and structured output for elements such as text, tables, formulas, charts, and handwriting. Official evaluations on public and self-built datasets such as OmniDocBench show that PaddleOCR-VL achieves or surpasses state-of-the-art performance in both page-level parsing and feature-level recognition.
PaddleOCR-VL claims to cover 109 languages and scripts, including Chinese, English, Japanese, Latin and Arabic, Cyrillic, and Devanagari. It optimizes inference efficiency for real-world production and can be used in conjunction with PaddleOCR components like PP-StructureV3 and PP-OCRv5. The model and documentation are available on GitHub, HuggingFace, and the official documentation. For detailed benchmarks, visualization examples, and deployment methods, please refer to the official website. Please stay tuned for updates to the repository for further details, such as dataset versions and evaluation scope.
Frequently Asked Questions
Q: What is PaddleOCR-VL?
A: A visual language model with approximately 0.9B parameters for end-to-end document parsing that can simultaneously process text, tables, formulas, charts, and handwriting, and output structured results.
Q: Why is it called "ultra-compact"?
A: In the multimodal VLM, 0.9B is relatively small in size and efficient in inference. By combining NaViT dynamic resolution with ERNIE-4.5-0.3B, computing power requirements are reduced while maintaining accuracy.
Q: Has it really reached SOTA?
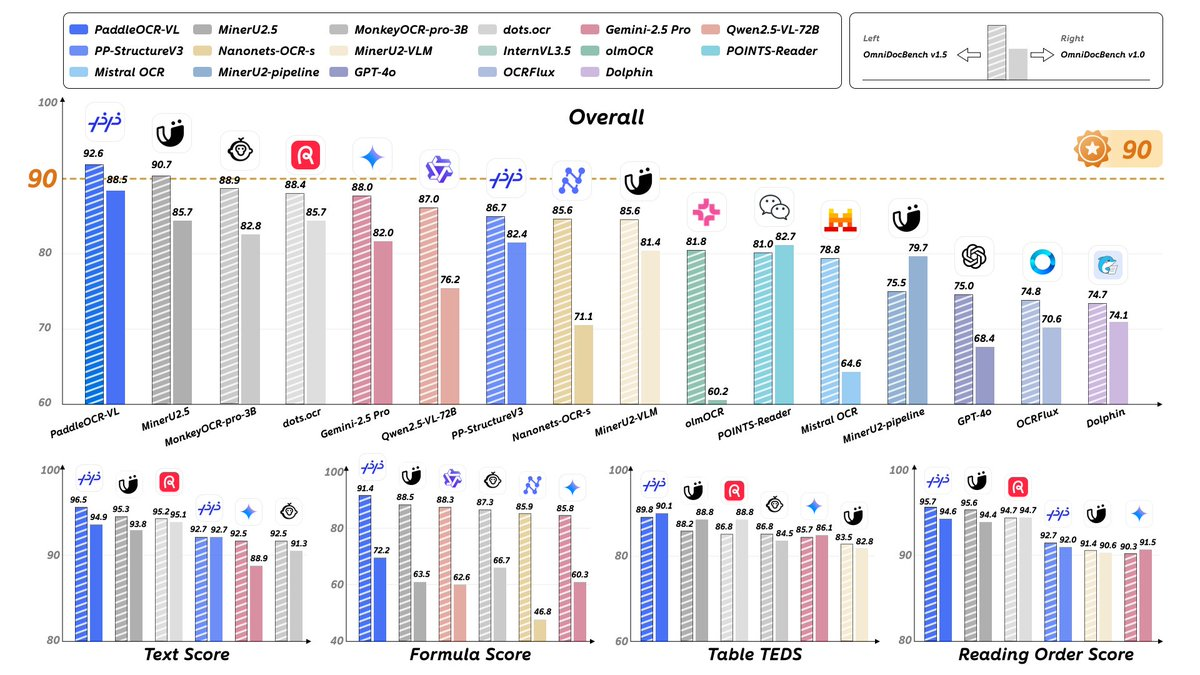
A: We have demonstrated leading results in benchmarks such as OmniDocBench v1.5/v1.0 and our own benchmarks, covering multiple indicators such as overall performance, reading order, tables, and formulas. The conclusions are based on the charts and explanations provided in public reports and model cards.
Q: What languages and application scenarios are supported?
A: It covers 109 languages and is suitable for scenarios such as multi-script typesetting, historical documents, and complex layouts. It can be linked with the layout/table structuring capabilities of PP-StructureV3 for real business analysis.
Q: Where can I get it and how can I try it?
A: GitHub provides version notes and command line/Python APIs; HuggingFace provides model cards and online demo links; the documentation site provides deployment and acceleration (such as vLLM/sglang server) guides.