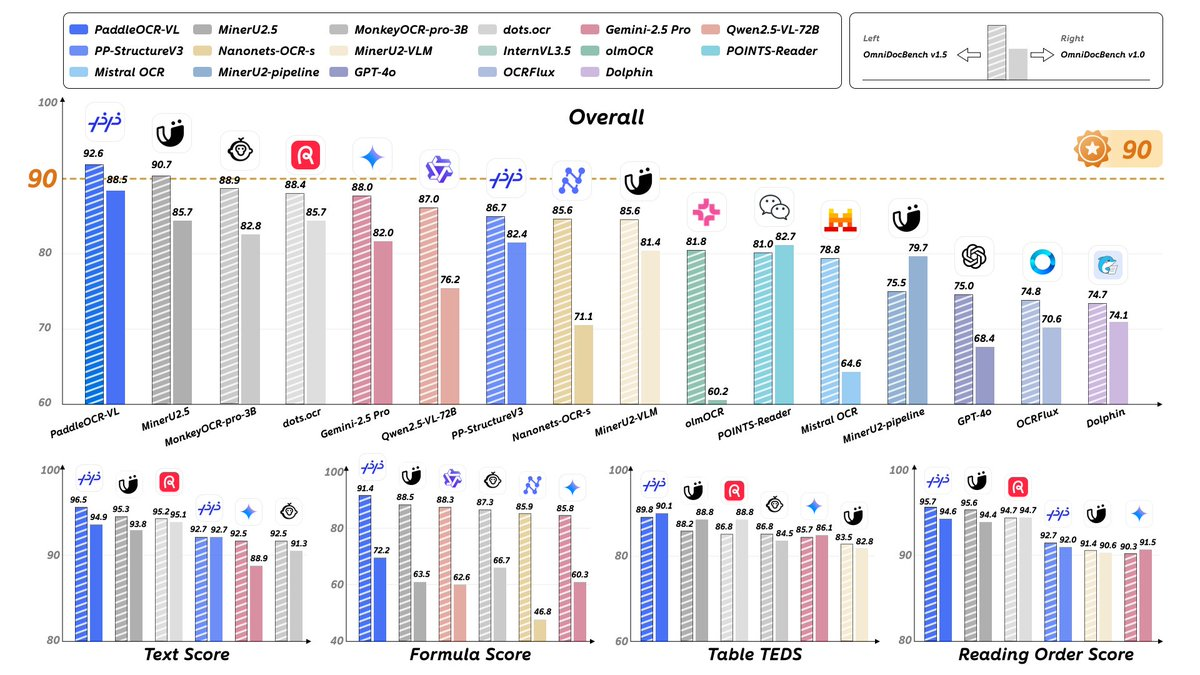
Am 16. Oktober 2025 kündigte PaddleOCR die Einführung seines multimodalen Dokumentanalysemodells PaddleOCR-VL an, das als Kernfunktion in Version 3.3.0 veröffentlicht wurde. Dieses etwa 0,9 B große Modell nutzt einen visuellen Encoder mit dynamischer Auflösung im NaViT-Stil in Kombination mit dem Sprachmodell ERNIE-4.5-0.3B, um eine einheitliche Erkennung und strukturierte Ausgabe von Elementen wie Text, Tabellen, Formeln, Diagrammen und Handschrift zu erreichen. Offizielle Evaluierungen öffentlicher und selbst erstellter Datensätze wie OmniDocBench zeigen, dass PaddleOCR-VL sowohl bei der Analyse auf Seitenebene als auch bei der Erkennung auf Featureebene die modernste Leistung erreicht oder übertrifft.
PaddleOCR-VL unterstützt nach eigenen Angaben 109 Sprachen und Schriften, darunter Chinesisch, Englisch, Japanisch, Latein, Arabisch, Kyrillisch und Devanagari. Es optimiert die Inferenzeffizienz für die reale Produktion und kann in Verbindung mit PaddleOCR-Komponenten wie PP-StructureV3 und PP-OCRv5 eingesetzt werden. Modell und Dokumentation sind auf GitHub, HuggingFace und in der offiziellen Dokumentation verfügbar. Detaillierte Benchmarks, Visualisierungsbeispiele und Bereitstellungsmethoden finden Sie auf der offiziellen Website. Weitere Informationen, wie z. B. zu Datensatzversionen und Evaluierungsumfang, erhalten Sie in Kürze im Repository.
Häufig gestellte Fragen
F: Was ist PaddleOCR-VL?
A: Ein visuelles Sprachmodell mit etwa 0,9 Milliarden Parametern für die End-to-End-Dokumentenanalyse, das Text, Tabellen, Formeln, Diagramme und Handschrift gleichzeitig verarbeiten und strukturierte Ergebnisse ausgeben kann.
F: Warum heißt es „ultrakompakt“?
A: Im multimodalen VLM ist 0,9B relativ klein und effizient in der Inferenz. Durch die Kombination der dynamischen Auflösung von NaViT mit ERNIE-4.5-0,3B wird der Rechenleistungsbedarf reduziert, während die Genauigkeit erhalten bleibt.
F: Hat es wirklich SOTA erreicht?
A: Wir haben in Benchmarks wie OmniDocBench v1.5/v1.0 und unseren eigenen Benchmarks führende Ergebnisse erzielt und dabei verschiedene Indikatoren wie Gesamtleistung, Lesereihenfolge, Tabellen und Formeln berücksichtigt. Die Schlussfolgerungen basieren auf den Diagrammen und Erklärungen in öffentlichen Berichten und Modellkarten.
F: Welche Sprachen und Anwendungsszenarien werden unterstützt?
A: Es deckt 109 Sprachen ab und eignet sich für Szenarien wie den Satz mehrerer Schriften, historische Dokumente und komplexe Layouts. Es kann mit den Layout-/Tabellenstrukturierungsfunktionen von PP-StructureV3 für echte Geschäftsanalysen verknüpft werden.
F: Wo kann ich es bekommen und wie kann ich es ausprobieren?
A: GitHub bietet Versionshinweise und Befehlszeilen-/Python-APIs; HuggingFace bietet Modellkarten und Links zu Online-Demos; die Dokumentationssite bietet Anleitungen zur Bereitstellung und Beschleunigung (wie z. B. vLLM/sglang-Server).