LongCat-Flash-Chat 출시: 560B 매개변수 대형 모델, 100 TPS로 AI 추론의 새로운 시대를 열다
Meituan 팀이 출시한 LongCat-Flash-Chat은 총 560B의 매개변수와 18.6B-31.3B의 동적 활성화를 핵심 하이라이트로 하고 20T 훈련 데이터와 100+ 토큰/s 추론 속도와 결합되어 TerminalBench 및 τ²-Bench에서 최고의 결과를 달성했습니다. 이는 대규모 모델의 성능 혁신일 뿐만 아니라 AI 도구, 자동화된 에이전트 및 지능형 워크플로를 위한 새로운 옵션을 제공합니다.

1. 핵심 하이라이트
1. 560B 매개변수 + 동적 활성화 아키텍처
LongCat-Flash-Chat은 Mixture-of-Experts(전문가 하이브리드 아키텍처)를 채택하여 총 매개변수가 560B에 달하지만 실제 추론은 약 27B 매개변수만 활성화하여 지능형 성능을 보장할 뿐만 아니라 컴퓨팅 비용도 제어합니다.
2. 고속 추론: 100+ token/s
인공 지능 모델은 초당 100개의 토큰의 추론 성능을 달성하여 대규모 애플리케이션의 짧은 대기 시간 요구 사항을 충족하며 에이전트 작업, 터미널 도구 호출 및 실시간 상호 작용 시나리오에 적합합니다.
(1) 성능 평가: TerminalBench vs. τ²-Bench
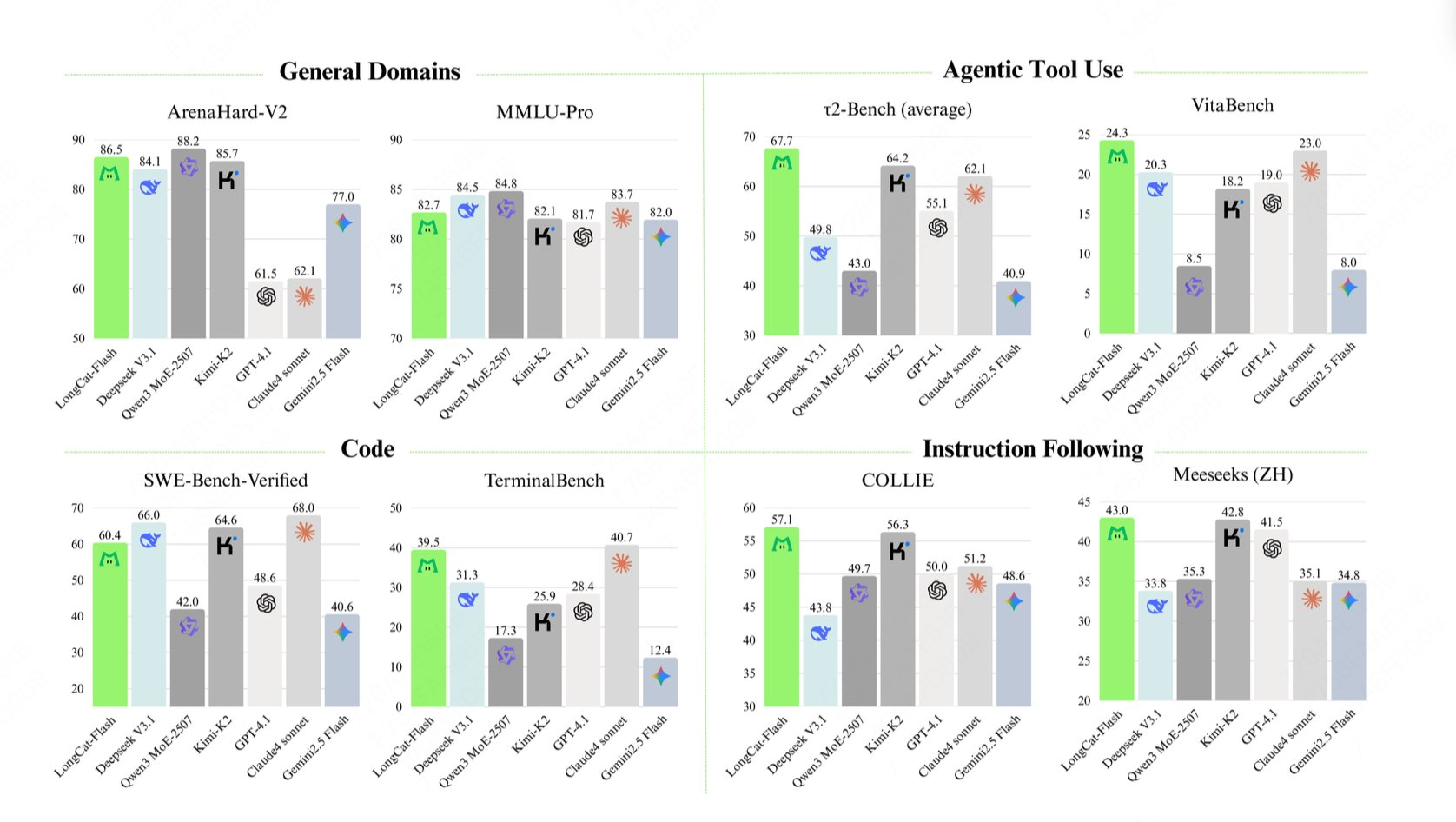
이모델은 TerminalBench에서 39.5점, τ²-Bench에서 67.7점을 획득하여 도구 사용 및 복잡한 작업에 대한 강력한 처리 능력을 입증하고 AI 도구 속성을 입증했습니다.
2. AI 툴스테이션의 가치
1. 지능형 에이전트 구현
AI툴스테이션은 ChatGPT와 결합하여 작업 계획을 생성하고, Claude와 결합하여 보안 로직을 확인하고, LongCat-Flash-Chat과 결합하여 복잡한 명령을 실행하여 프롬프트에서 실행까지 자동화된 프로세스를 달성할 수 있습니다.
2. 비용과 성능 간의 균형
동적 활성화는 중복 계산을 줄여 AI가 대규모 모델의 인텔리전스를 유지하면서 추론 효율성을 향상시킬 수 있도록 합니다. 이는 기업이 동일한 컴퓨팅 성능으로 더 높은 처리량을 달성할 수 있음을 의미합니다.
(1) 구현 계획 제안
:a. SGLang 또는 vLLM을 추론 엔진으로 사용
b. ChatGPT를 통해 프롬프트 및 대화 템플릿 생성
c. Claude가 보안 규정 준수 검사를 수행합니다.
d. LongCat은 효율적인 실행 및 작업 스케줄링
3. 애플리케이션
시나리오 1: 터미널 운영 및 자동화된 O&M
AI 도구는 명령줄 작업, 스크립트 실행 및 로그 분석을 신속하게 처리하여 DevOps 및 R&D 효율성을 향상시킬 수 있습니다.
2. 데이터 처리 및 멀티태스킹 상호 작용
Claude 및 ChatGPT와 결합된 LongCat은 데이터 스크래핑, 지식 구성 및 일괄 요약 생성과 같은 시나리오에서 역할을 수행하여 자동화된 워크플로 구축을 촉진할 수 있습니다.
4. 한계와 미래 동향
1. 엔지니어링 및 하드웨어 임계값
동적 활성화는 비디오 메모리에 대한 수요를 줄이지만 다중 기계 통신 및 분산 추론은 여전히 높은 엔지니어링 경험이 필요하며 경화 환경에는 적합하지 않습니다.
2. 향후 방향
대형 모델은 에이전트 및 실행 기능을 지속적으로 강화할 것이며, ChatGPT와 Claude는 계획 및 보안 제어에 있으며, LongCat은 고속으로 실행되고 있으며 세 가지가 함께 협력하여 인텔리전스와 자동화의 완전한 링크를 형성합니다.
5. LongCat
https://huggingface.co/meituan-longcat/LongCat-Flash-Chat
LongCat 모델 카드
참조공식 사이트: https://longcat.ai
LongCat-Flash 기술 보고서: 자주
묻는 질문(Q&A)
을 https://arxiv.org/abs/2509.01322Q: 기존 대형 모델에 비해 LongCat-Flash-Chat의 장점은 무엇입니까?
A: 동적 활성화 메커니즘을 사용하여 추론에는 약 27B의 계산만 필요하며, 이는 560B 모델의 지식 보유량을 가질 뿐만 아니라 빠른 속도와 낮은 대기 시간을 유지합니다.
Q: LongCat-Flash-Chat을 AI Toolstation과 어떻게 통합합니까?
A: 추론 서비스는 SGLang 또는 vLLM을 사용하여 배포할 수 있으며, ChatGPT는 업스트림에서 프롬프트를 생성하고, Claude는 보안 정책을 검토한 후 마지막으로 실행을 위해 LongCat에 넘겨줍니다.
Q: TerminalBench 대 τ²-Bench 점수는 무엇을 말합니까?
A: 둘은 실제 장면에 더 가깝고 높은 점수는 모델이 도구 호출, 터미널 작동 및 복잡한 작업 실행에서 우수한 성능을 발휘하고 지능형 에이전트 애플리케이션에 적합하다는 것을 나타냅니다.
Q: ChatGPT나 Claude를 완전히 대체할 수 있나요?
A: LongCat은 실행 및 추론 가속화에 더 적합한 반면 ChatGPT와 Claude는 계획 및 검토보다 더 강력합니다.