Sortie de LongCat-Flash-Chat : le grand modèle de paramètre 560B ouvre une nouvelle ère de l’inférence IA avec 100 TPS
Le LongCat-Flash-Chat lancé par l’équipe Meituan a un total de 560B de paramètres et une activation dynamique de 18,6B-31,3B comme points forts, combinés à des données d’entraînement de 20T et une vitesse d’inférence de 100+ jetons/s, et a obtenu des résultats de premier plan dans TerminalBench et τ²-Bench. Il s’agit non seulement d’une percée en termes de performances pour les grands modèles, mais aussi de nouvelles options pour les outils d’IA, les agents automatisés et les flux de travail intelligents.

1. Points forts du noyau
1. Paramètres 560B + architecture d’activation dynamique
LongCat-Flash-Chat adopte le Mixture-of-Experts (architecture hybride experte), bien que les paramètres totaux atteignent 560 B, mais l’inférence réelle n’active qu’environ 27 B de paramètres, ce qui garantit non seulement des performances intelligentes, mais contrôle également les coûts de calcul.
2. Inférence à haut débit : Le modèle d’intelligence artificielle 100+ jetons/s
atteint des performances d’inférence de 100 jetons par seconde, répondant aux exigences de faible latence des applications à grande échelle, et convient aux tâches d’agent, aux appels d’outils de terminal et aux scénarios d’interaction en temps réel.
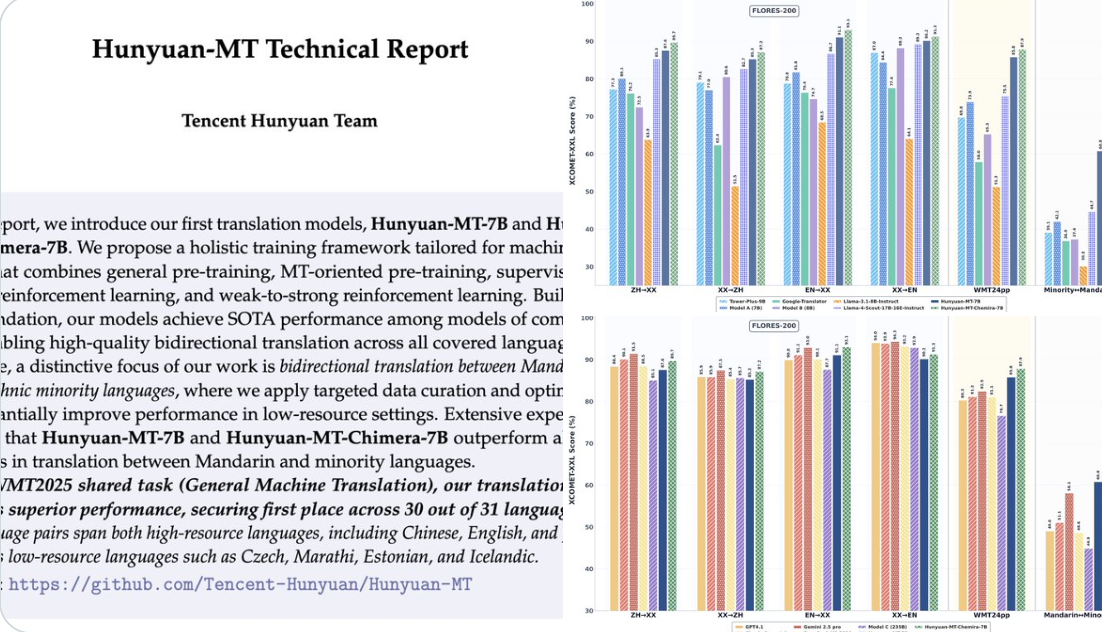
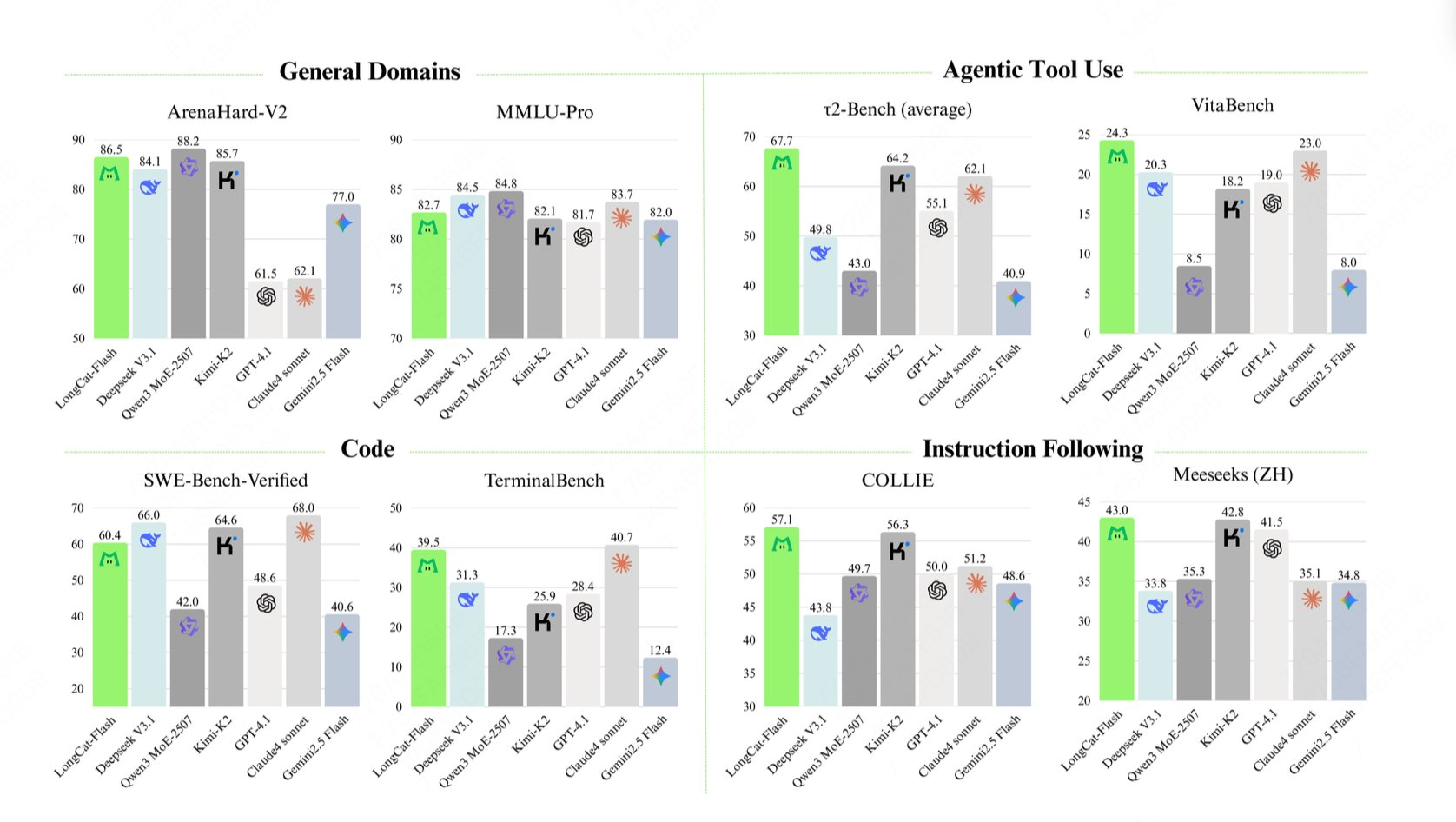
(1) Évaluation des performances : TerminalBench vs. τ²-Bench
Le modèle a obtenu un score de 39,5 sur TerminalBench et de 67,7 sur τ²-Bench, démontrant ainsi ses solides capacités de traitement pour l’utilisation d’outils et les tâches complexes, prouvant ainsi ses attributs d’outil d’IA.
2. Valeur pour AI Toolstation
1. Mise en œuvre d’un agent intelligent
AIToolstation peut être combiné avec ChatGPT pour générer des plans de tâches, Claude pour vérifier la logique de sécurité, puis LongCat-Flash-Chat pour exécuter des commandes complexes afin de réaliser un processus automatisé de l’invite à l’exécution.
2. Équilibre entre coût et performance
L’activation dynamique réduit les calculs redondants, ce qui permet à l’IA d’améliorer l’efficacité de l’inférence tout en conservant l’intelligence des grands modèles. Cela signifie que les entreprises peuvent atteindre un débit plus élevé avec la même puissance de calcul.
(1) Suggestions de plan de mise en œuvre
:a. Utiliser SGLang ou vLLM comme moteur d’inférence
b. ChatGPT pour générer des invites et des modèles de dialogue
c. Claude effectue des contrôles de conformité de sécurité
d. LongCat est responsable de l’exécution efficace et de la planification des
3.
Scénario d’application 1 : Les outils d’IA d’exploitation et de maintenance automatisés
peuvent gérer rapidement les tâches de ligne de commande, l’exécution de scripts et l’analyse des journaux, améliorant ainsi l’efficacité DevOps et R&D.
2. Traitement des données et interaction multitâche
Combiné à Claude et ChatGPT, LongCat peut jouer un rôle dans des scénarios tels que le grattage de données, l’organisation des connaissances et la génération de résumés par lots, favorisant ainsi la construction de flux de travail automatisés.
4. Limites et tendances futures
1. Ingénierie et seuil matériel
Bien que l’activation dynamique réduise la demande de mémoire vidéo, la communication multi-machines et l’inférence distribuée nécessitent toujours une expérience élevée en ingénierie et ne conviennent pas aux environnements légers.
2. Orientation future
Le grand modèle continuera à renforcer les capacités d’agent et d’exécution, ChatGPT et Claude sont en planification et en contrôle de la sécurité, et LongCat exécute à grande vitesse, et les trois travaillent ensemble pour former un lien complet d’intelligence et d’automatisation.
5. Références
Carte modèle LongCat-Flash-Chat
https://huggingface.co/meituan-longcat/LongCat-Flash-Chat
LongCat Site officiel : https://longcat.ai
Rapport technique LongCat-Flash : https://arxiv.org/abs/2509.01322
Foire aux questions (Q&R).
Q : Quels sont les avantages de LongCat-Flash-Chat par rapport aux grands modèles traditionnels ?
R : À l’aide d’un mécanisme d’activation dynamique, l’inférence ne nécessite qu’environ 27 B de calcul, ce qui permet non seulement de disposer de la réserve de connaissances du modèle 560 B, mais aussi de maintenir une vitesse élevée et une faible latence.
Q : Comment puis-je intégrer LongCat-Flash-Chat à AI Toolstation ?
R : Les services d’inférence peuvent être déployés à l’aide de SGLang ou vLLM, et ChatGPT génère des invites en amont, Claude examine les politiques de sécurité et les transmet enfin à LongCat pour exécution.
Q : Que dit le score TerminalBench par rapport au score τ²-Bench ?
R : Les deux sont plus proches de la scène réelle, et le score élevé indique que le modèle fonctionne bien dans l’appel d’outils, le fonctionnement du terminal et l’exécution de tâches complexes, et qu’il est adapté aux applications d’agents intelligents.
Q : Est-il possible de remplacer complètement ChatGPT ou Claude ?
R : LongCat est plus adapté à l’exécution et à l’accélération du raisonnement, tandis que ChatGPT et Claude sont plus forts que la planification et la révision.