LongCat-Flash-Chat wird veröffentlicht: Das 560B große Modell eröffnet mit 100 TPS eine neue Ära der KI-Inferenz
Der vom Meituan-Team gestartete LongCat-Flash-Chat hat 560B Gesamtparameter und eine dynamische Aktivierung von 18,6B-31,3B als Kern-Highlights, kombiniert mit 20T Trainingsdaten und 100+ Token/s Inferenzgeschwindigkeit, und hat führende Ergebnisse in TerminalBench und τ²-Bench erzielt. Es ist nicht nur ein Leistungsdurchbruch für große Modelle, sondern bietet auch neue Optionen für KI-Tools, automatisierte Agenten und intelligente Workflows.

1. Kern-Highlights
1. 560B-Parameter + dynamische Aktivierungsarchitektur
LongCat-Flash-Chat verwendet Mixture-of-Experts (Experten-Hybrid-Architektur), obwohl die Gesamtparameter bis zu 560B betragen, aber die tatsächliche Inferenz aktiviert nur etwa 27B Parameter, was nicht nur eine intelligente Leistung gewährleistet, sondern auch die Rechenkosten kontrolliert.
2. Hochgeschwindigkeits-Inferenz: Das Modell der künstlichen Intelligenz mit 100+ Token/s
erreicht eine Inferenzleistung von 100 Token pro Sekunde und erfüllt damit die Anforderungen an die geringe Latenz großer Anwendungen und eignet sich für Agentenaufgaben, Terminal-Tool-Aufrufe und Echtzeit-Interaktionsszenarien.
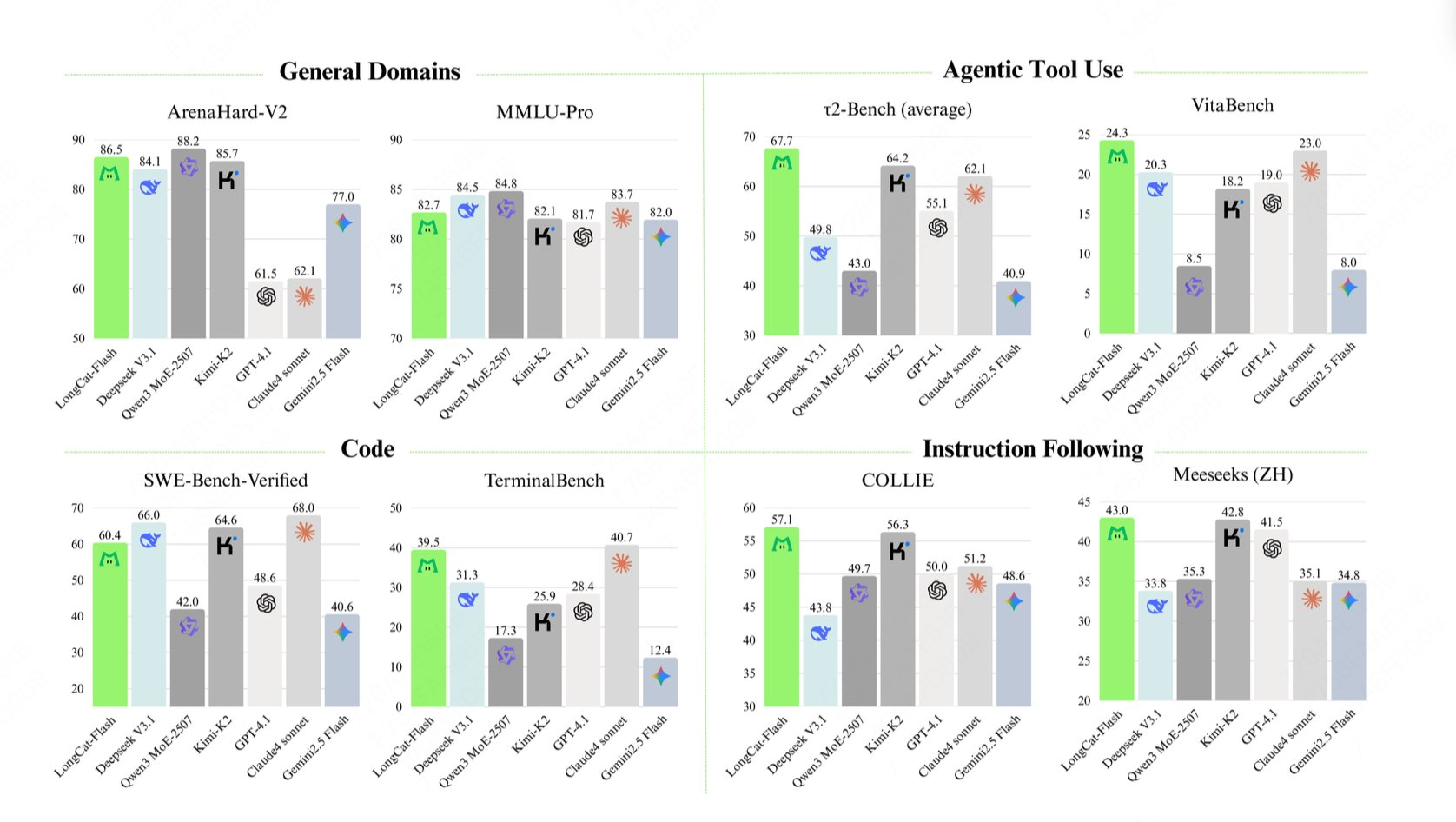
(1) Leistungsbewertung: TerminalBench vs. τ²-Bench
Das Modell erzielte 39,5 Punkte auf der TerminalBench und 67,7 Punkte auf der τ²-Bench, was seine starken Verarbeitungsfähigkeiten für die Werkzeugnutzung und komplexe Aufgaben unter Beweis stellt und seine KI-Tool-Eigenschaften unter Beweis stellt.
2. Wert für die KI-Toolstation
1. Intelligente Agentenimplementierung
DieKI-Toolstation kann mit ChatGPT kombiniert werden, um Aufgabenpläne zu erstellen, Claude zur Überprüfung der Sicherheitslogik und dann mit LongCat-Flash-Chat, um komplexe Befehle auszuführen und einen automatisierten Prozess von der Eingabeaufforderung bis zur Ausführung zu erreichen.
2. Gleichgewicht zwischen Kosten und Leistung
Diedynamische Aktivierung reduziert redundante Berechnungen und ermöglicht es der KI, die Inferenzeffizienz zu verbessern und gleichzeitig die Intelligenz großer Modelle zu erhalten. Das bedeutet, dass Unternehmen bei gleicher Rechenleistung einen höheren Durchsatz erzielen können.
(1) Vorschläge für einen Implementierungsplan
:a. Verwenden Sie SGLang oder vLLM als Inferenz-Engine
b. ChatGPT zur Generierung von Eingabeaufforderungen und Dialogvorlagen
c. Claude führt Sicherheitsüberprüfungen durch
d. LongCat ist für die effiziente Ausführung und Aufgabenplanung
3. Anwendungsszenario
1: Terminalbetrieb und automatisierte O&M-KI-Tools
können Befehlszeilenaufgaben, Skriptausführung und Protokollanalyse schnell bewältigen und so die DevOps- und F&E-Effizienz verbessern.
2. Datenverarbeitung und Multitasking-Interaktion
In Kombination mit Claude und ChatGPT kann LongCat eine Rolle in Szenarien wie Daten-Scraping, Wissensorganisation und Generierung von Batch-Zusammenfassungen spielen und den Aufbau automatisierter Workflows fördern.
4. Einschränkungen und zukünftige Trends
1. Engineering- und Hardware-Schwellenwerte
Obwohl die dynamische Aktivierung den Bedarf an Videospeicher reduziert, erfordern die Kommunikation mit mehreren Maschinen und die verteilte Inferenz immer noch viel technische Erfahrung und sind nicht für leichtgewichtige Umgebungen geeignet.
2. Zukünftige Ausrichtung
Das große Modell wird die Agenten- und Ausführungsfähigkeiten weiter stärken, ChatGPT und Claude sind in der Planung und Sicherheitskontrolle, und LongCat führt mit hoher Geschwindigkeit aus, und die drei arbeiten zusammen, um eine vollständige Verbindung von Intelligenz und Automatisierung zu bilden.
5. Referenzen
LongCat-Flash-Chat Modellkarte
https://huggingface.co/meituan-longcat/LongCat-Flash-Chat
LongCat Offizielle Website: https://longcat.ai
Technischer Bericht von LongCat-Flash: https://arxiv.org/abs/2509.01322
Häufig gestellte Fragen (Fragen und Antworten).
F: Was sind die Vorteile von LongCat-Flash-Chat gegenüber herkömmlichen großen Modellen?
A: Bei Verwendung eines dynamischen Aktivierungsmechanismus erfordert die Inferenz nur etwa 27 B Rechenleistung, was nicht nur über die Wissensreserve des 560B-Modells verfügt, sondern auch eine hohe Geschwindigkeit und geringe Latenz beibehält.
F: Wie integriere ich LongCat-Flash-Chat mit AI Toolstation?
A: Inferenzdienste können mit SGLang oder vLLM bereitgestellt werden, und ChatGPT generiert Eingabeaufforderungen im Upstream, Claude überprüft Sicherheitsrichtlinien und übergibt sie schließlich zur Ausführung an LongCat.
F: Was sagt der TerminalBench vs. τ²-Bench-Score aus?
A: Die beiden sind näher an der realen Szene, und die hohe Punktzahl deutet darauf hin, dass das Modell bei Werkzeugaufrufen, Terminalbedienung und komplexer Aufgabenausführung gut abschneidet und für intelligente Agentenanwendungen geeignet ist.
F: Ist es möglich, ChatGPT oder Claude vollständig zu ersetzen?
A: LongCat eignet sich eher für die Beschleunigung der Ausführung und des logischen Denkens, während ChatGPT und Claude stärker sind als das Planen und Überprüfen.