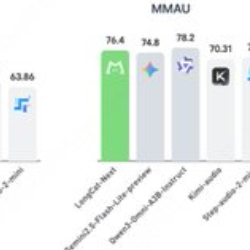
LongCat-Next オープンソースリリース:テキスト、画像、音声を統合するネイティブのマルチモーダルモデル
- 要旨 LongCat-Nextは、MeituanのLongCatチームによるオープンソースの離散ネイティブ自己回帰マルチモーダルモデルで、テキスト、ビジュアル、音声を同じフレームワークで統合することを目指しています。 本プロジェクトはMoEアーキテクチャを採用しており、総パラメータは約68.5B...
Admin •
129
- 要旨 LongCat-Nextは、MeituanのLongCatチームによるオープンソースの離散ネイティブ自己回帰マルチモーダルモデルで、テキスト、ビジュアル、音声を同じフレームワークで統合することを目指しています。 本プロジェクトはMoEアーキテクチャを採用しており、総パラメータは約68.5B...
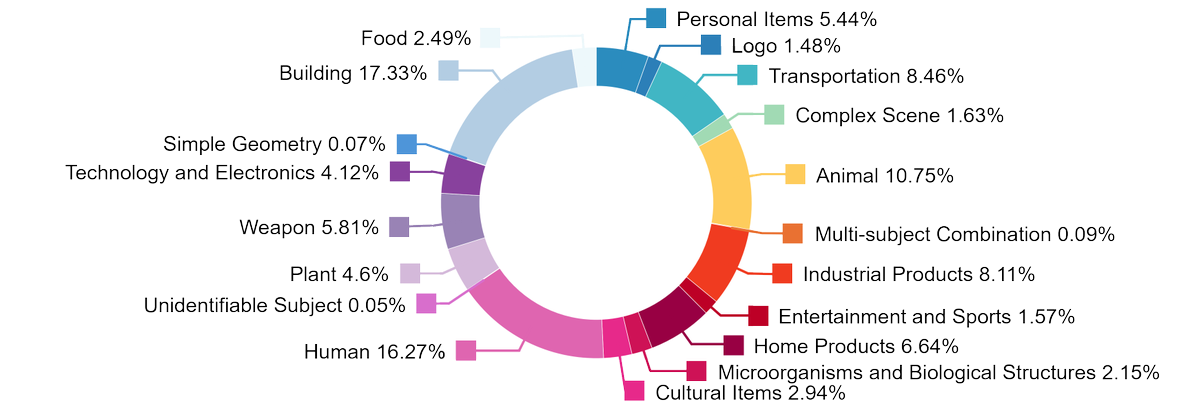
1. 要旨 HY3D-Benchは、騰訊のHunyuanチームによるオープンソースの統一3D資産データエコシステムであり、3D生成分野における「データ希少性、高いノイズ、評価の一貫性の欠如」という共通の課題を緩和することを目的としています。 プロジェクトは、フルレベル(252K+完全オブジェクト)、...
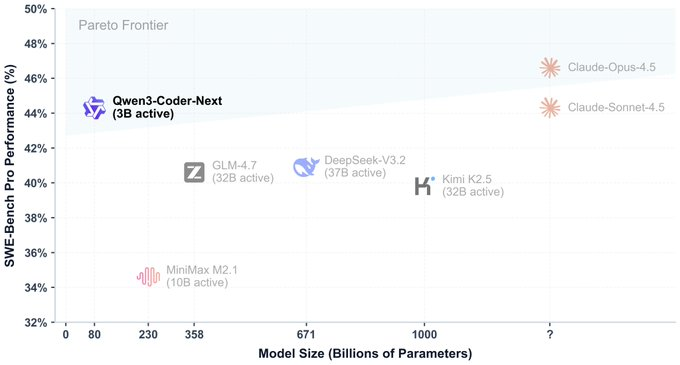
1. 要旨 Qwen3-Coder-Nextは、Qwen Teamがリリースしたオープンソースの重み付きコードモデルで、コーディングエージェントやローカル開発シナリオに適しています。 その核心的な考え方は「超スパースMoE + エージェントトレーニング」であり、パラメータ数は約80Bですが、トークン...
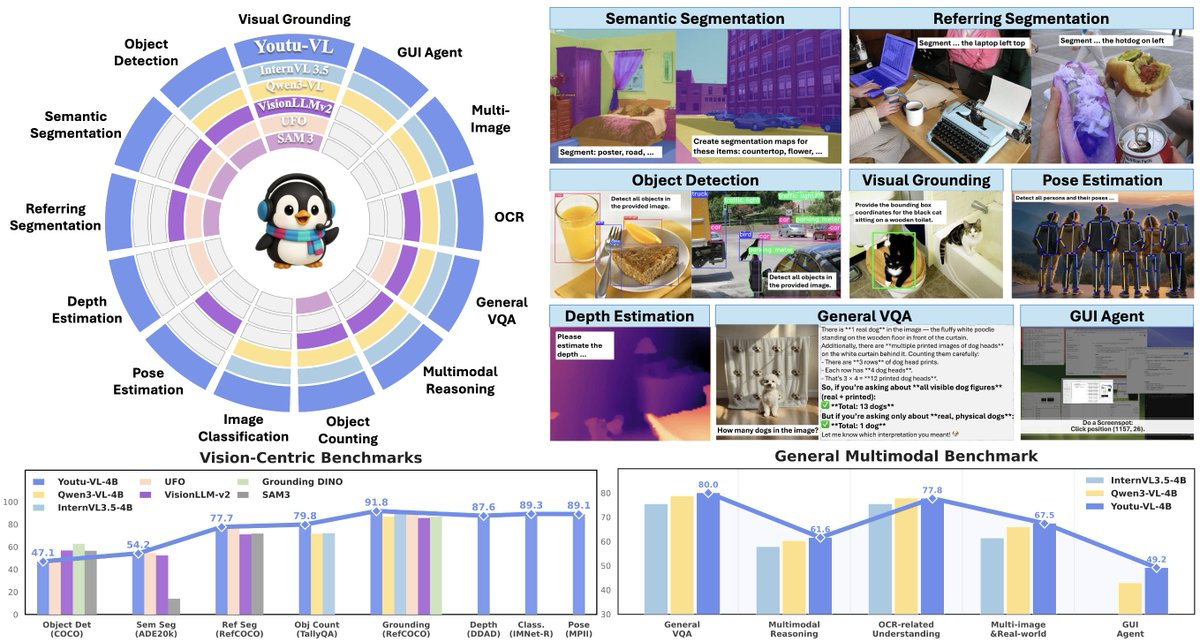
1. 要旨 Youtu-VL-4B-Instructは、Tencent Youtuが提供するコンパクトな視覚言語モデル(4Bパラメータ)で、VLUAS(Vision-Language Unified Autoregressive Supervision)を提案しています。これは「視覚を入力から予測可...
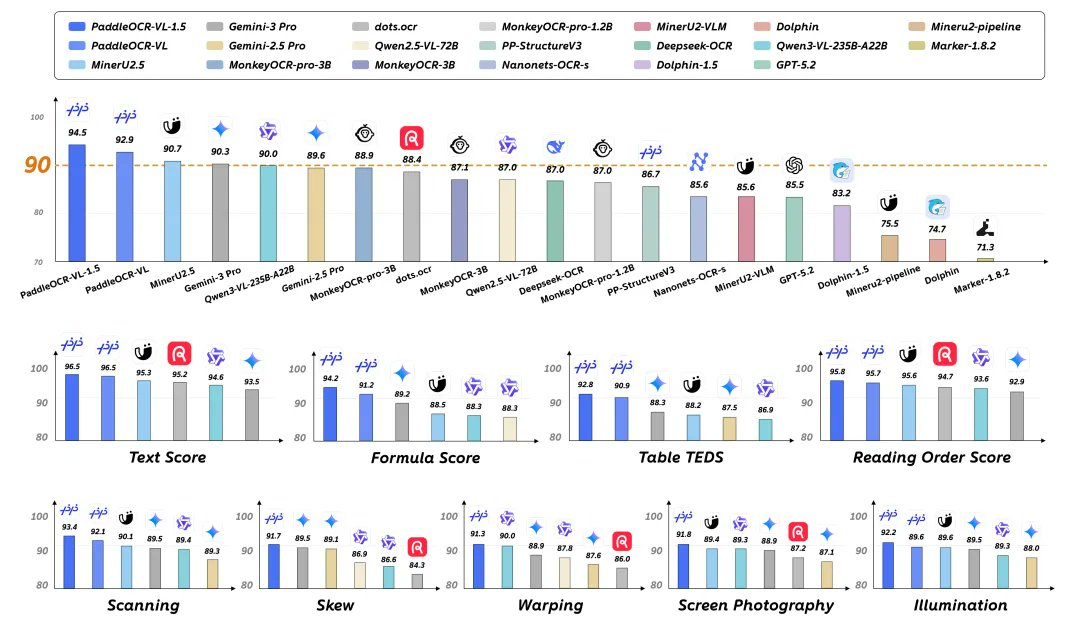
1. 要旨 PaddleOCR-VL-1.5は、PaddlePaddleのオープンソース0.9Bパラメトリックドキュメントマルチモーダルモデルであり、レイアウトの位置付け、読み取り順からテキスト・表・数式などの構造化解析まで、実際の取得シナリオ(「曲げ、歪み、傾斜、スクリーン撮影、複雑な照明」など)...

1. 要旨 PaddleOCRは、PaddlePaddleをベースにしたオープンソースのOCRおよび文書解析ツールボックスで、画像やPDFに対して「テキスト認識+構造化抽出」を提供します。 3.xシステムでは、PP-OCRv5は一般的なテキスト検出と認識をカバーし、PP-StructureV3は複雑...