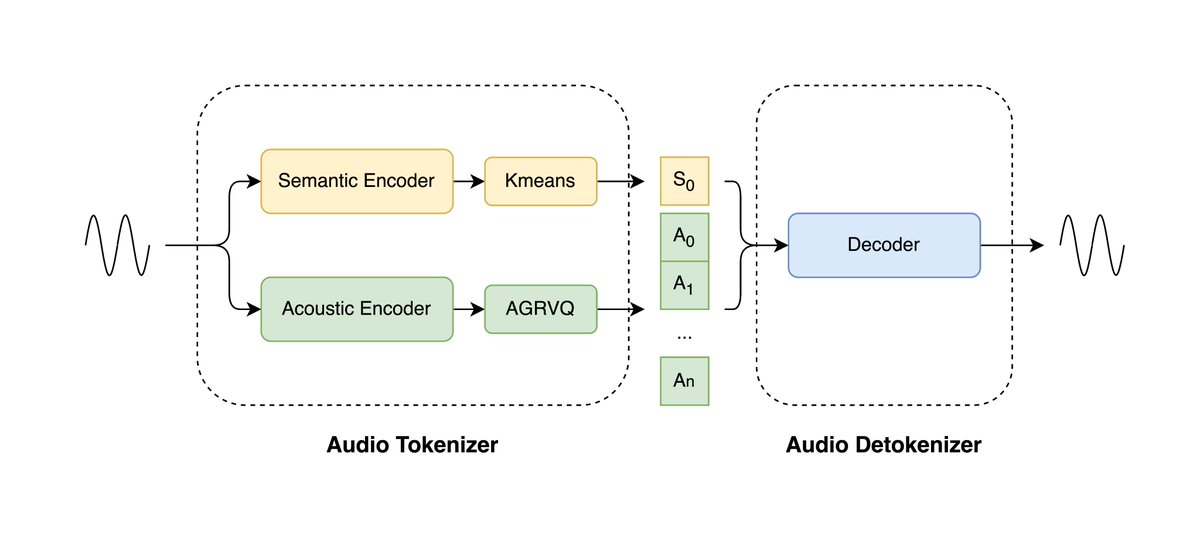
LongCat-Audio-Codec オープンソース: 大規模音声モデル向けの超低ビットレートオーディオコーデック
I. 要約 LongCat-Audio-Codecは、Meituan LongCatチームによって開発されたオープンソースのオーディオコーデックソリューションで、音声大規模モデル(LLM)向けに最適化されています。このプロジェクトは、デュアルトークンアーキテクチャを採用し、意味情報と音響情報を同時に...
Admin •
137
I. 要約 LongCat-Audio-Codecは、Meituan LongCatチームによって開発されたオープンソースのオーディオコーデックソリューションで、音声大規模モデル(LLM)向けに最適化されています。このプロジェクトは、デュアルトークンアーキテクチャを採用し、意味情報と音響情報を同時に...

I. 要約 Qwen3Guardは、Alibaba Cloud Qwenチームが立ち上げたオープンソースのセキュリティ保護システムで、推論と出力の両方において大規模言語モデルのセキュリティを向上させるように設計されています。このシステムは、強化学習アライメントモデルである Qwen3-4B-Safe...
I. 要約 HunyuanImage 3.0は、Tencent Hunyuanが提供するオープンソースのネイティブマルチモーダルテキスト画像変換モデルです。MoEアーキテクチャとトランスフュージョンアプローチを採用し、テキストと画像のトレーニングを統合しています。公式情報によると、このモデルは80バ...

I. 要約 Hunyuan3D-Partは、Tencent Hunyuanが提供するオープンソースのコンポーネントレベルの3D形状生成・分解ソリューションです。P3 -SAM (ネイティブ3Dパーツセグメンテーション)と X-Part (制御可能なパーツ生成)で構成されています。トレーニングは2D ...

I. 要約 Qwen3-VLは、Alibaba Cloud Qwenチームによって開発されたオープンソースの視覚言語モデルです。画像、動画、テキストの統合的な理解と推論を目的として設計されています。主な特徴としては、ネイティブ256KBのコンテキスト(1MBまで拡張可能)、最大約2時間の動画における...
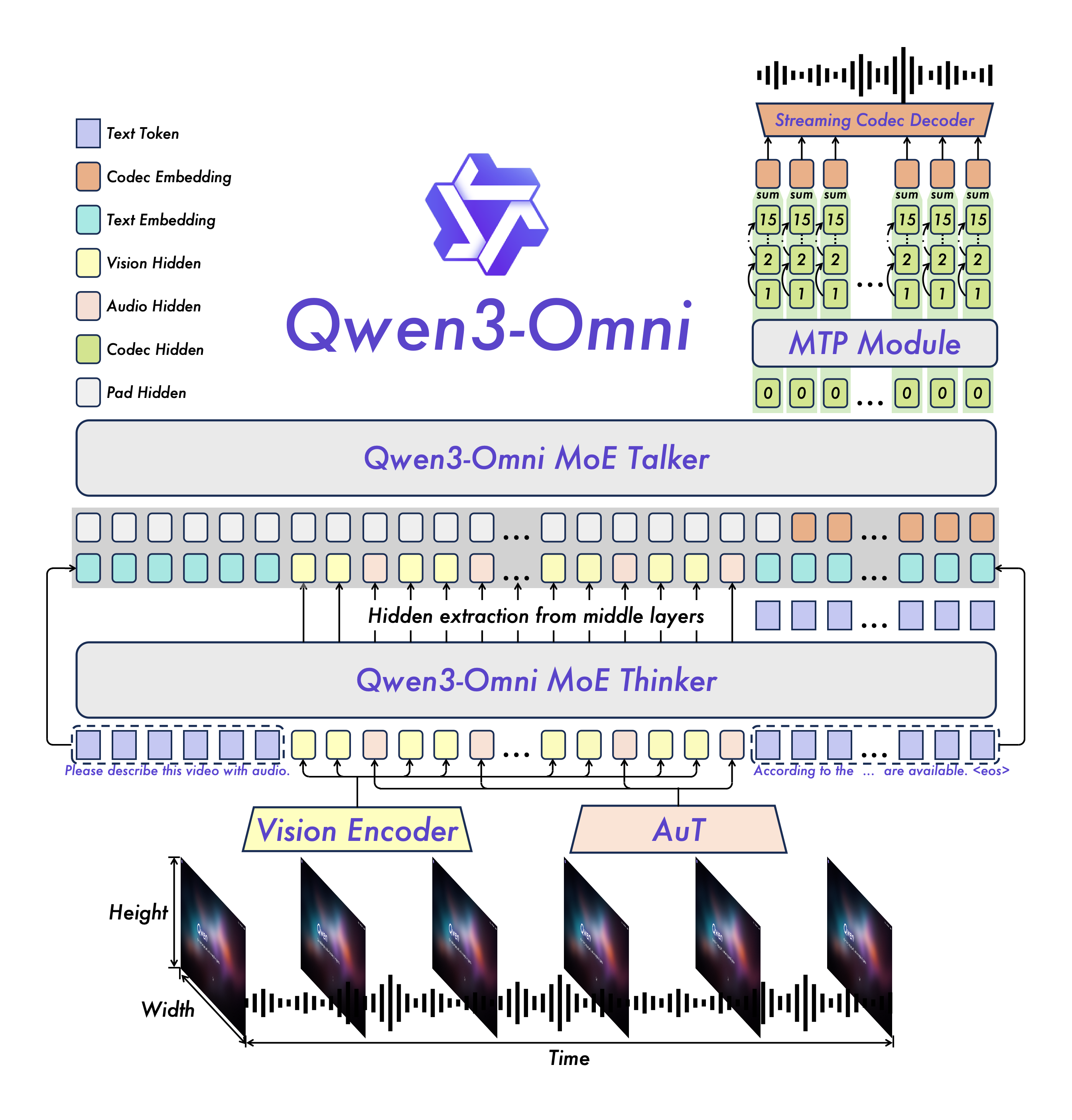
Qwen3-Omniは、マルチモーダルAIとエンドツーエンドの推論技術を融合させています。単一のモデルでテキスト、画像、音声、動画の入出力を統合し、速度と精度のバランスを実現します。公開テストでは、Qwen3-Omniは幅広い音声および動画ベンチマークで優れた結果を達成し、多様な重み付けオプションを...