
アンドリュー・ボズワース氏は、Metaが新しいAIモデルをテストしていることを明かし、これは重要な節目とみなされています
最近、MetaのCTOアンドリュー・ボズワース氏は、同社が「スーパーインテリジェンス研究所」からの新世代AIモデルのテストを社内で開始し、初期の進展を「有望」と表現しました。 この声明は、Metaが先進的なAI研究の方向に向けた最新のシグナルと見なされています。 関連情報によると、これらのモデルは現...
Admin •
65
最近、MetaのCTOアンドリュー・ボズワース氏は、同社が「スーパーインテリジェンス研究所」からの新世代AIモデルのテストを社内で開始し、初期の進展を「有望」と表現しました。 この声明は、Metaが先進的なAI研究の方向に向けた最新のシグナルと見なされています。 関連情報によると、これらのモデルは現...

ブルームバーグによると、AppleはSiriをより完全なAIチャットボット体験(コードネーム「Campos」)に変貌させる計画で、iPhone、iPad、MacのOSに深く組み込まれ、現在のSiriインターフェースとインタラクション方式に取って代わる予定です。 報道によると、新バージョンは音声入力と...
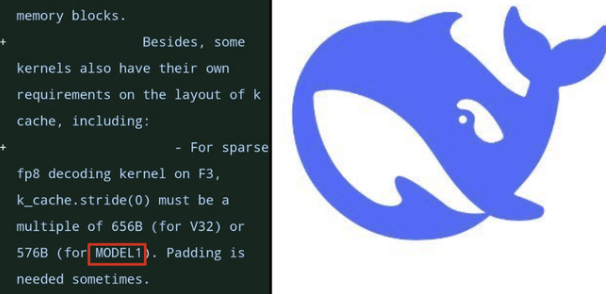
最近、ある開発者がDeepSeekが公開したGitHubコードベースに「MODEL1」というモデル識別子を発見し、新しいモデルの開発やテストを行っているのかという懸念が高まりました。 関連情報は開発者がコードコミットを読み議論した結果から得られており、DeepSeekが「MODEL1」に直接関連する...

OpenAIは、ChatGPTの消費者サブスクリプションプランに段階的に「年齢予測」を開始し、アカウントが18歳未満のユーザーに属しているかどうかを判断し、10代により適した経験および安全保障を自動的に適用すると発表しました。 OpenAIは、この仕組みはユーザー自身の年齢保護に加えて機能しており、...
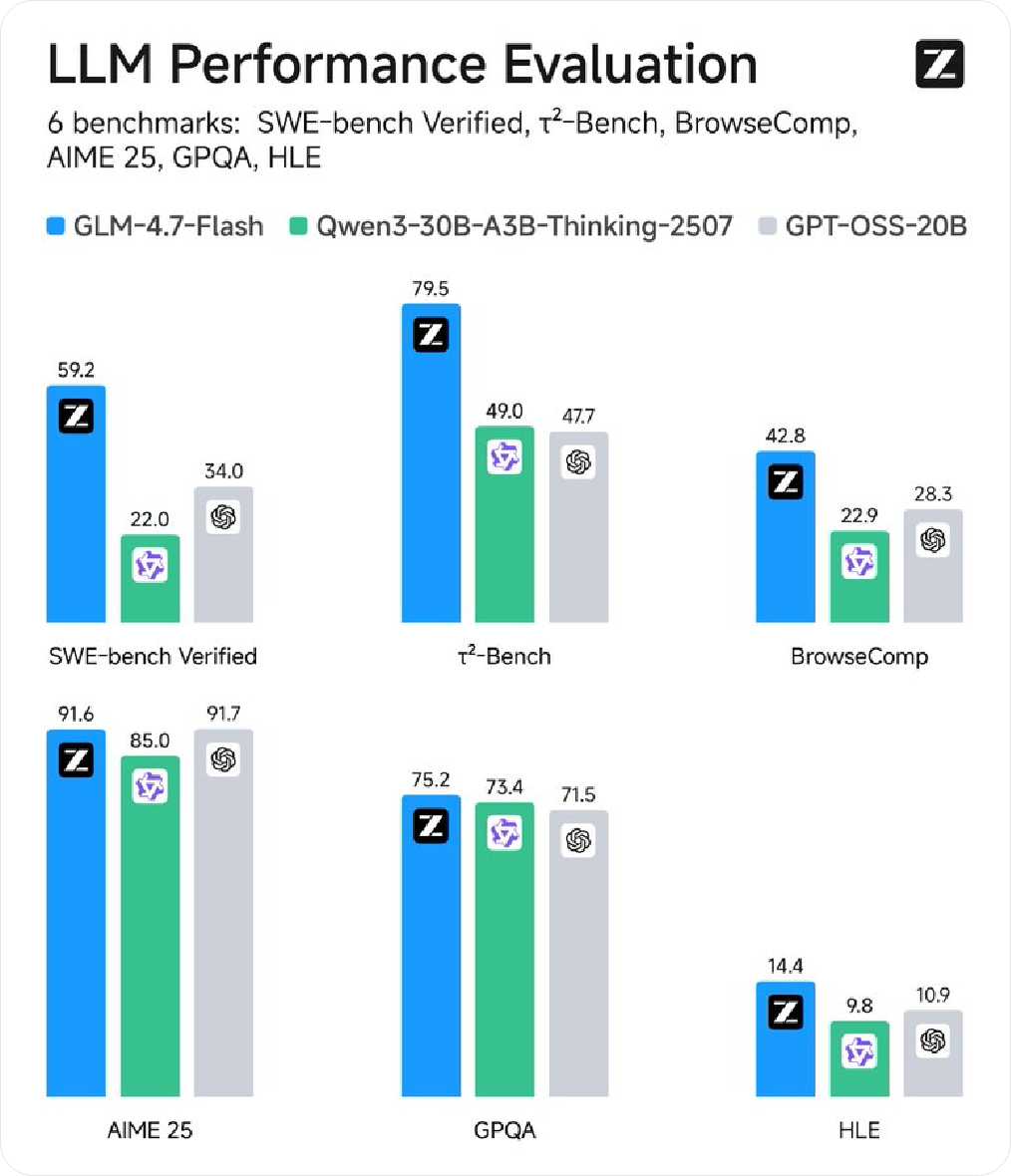
関連アカウント Z.ai Xに関する情報を掲載し、「ローカルコーディングおよびエージェントアシスタント」として位置づけられた新モデルGLM-4.7-Flashを紹介し、30Bレベルでの高いパフォーマンスと効率をバランスよく両立させ、軽量な展開オプションとして適していることを強調しました。 同期情報に...

最近、ソーシャルプラットフォームで拡散された声明によると、OpenAIは「Garlic」と呼ばれる新しいモデルバージョンであるGPT-5.3のリリース準備を進めており、以前にリリースされたGPT-5.2はモデルの初期のチェックポイントの一つに過ぎない可能性があると指摘されました。 この主張は「過去に...