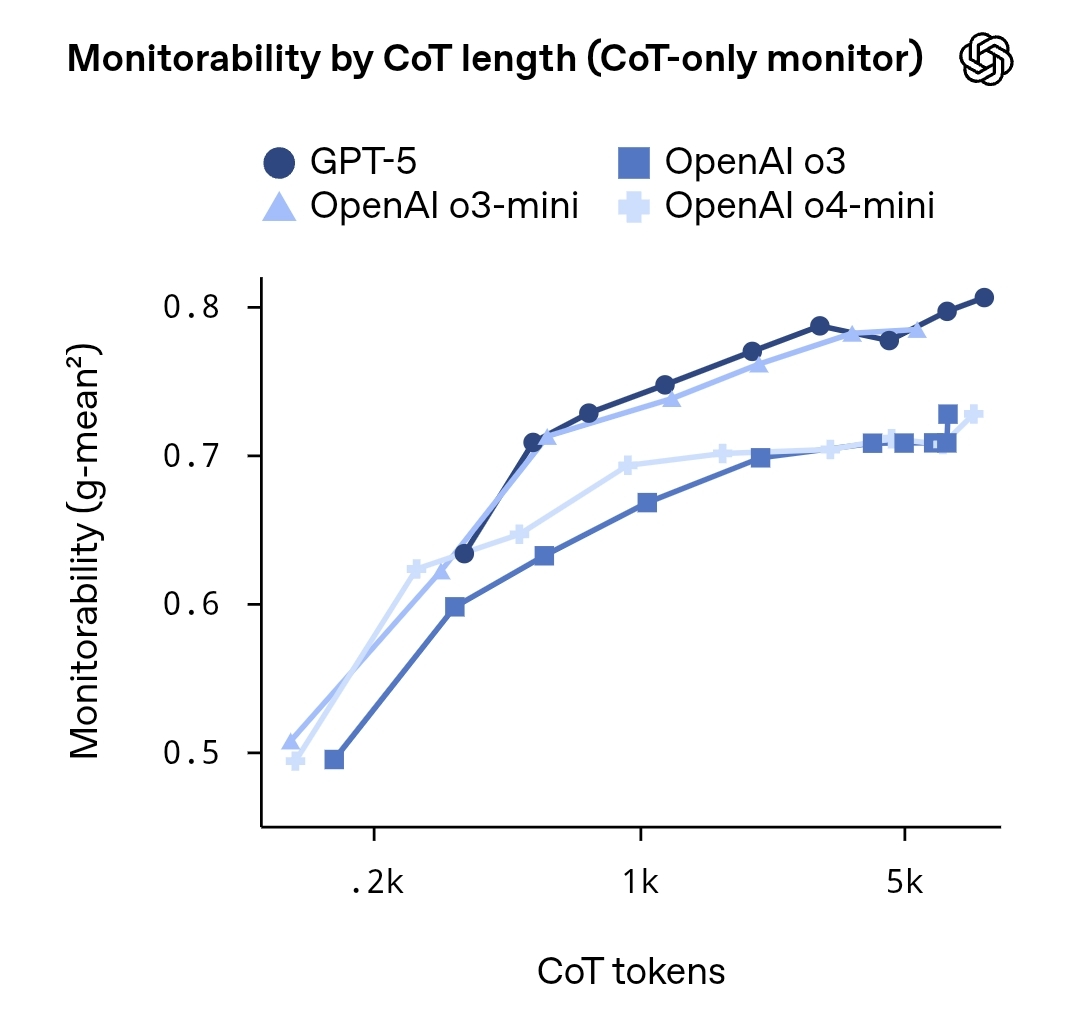
OpenAIは「Evaluating Chain-of-Thought Monitorability」という研究報告書を発表し、大規模言語モデルにおける「Chain-of-Thought(CoT)」の監視可能性とセキュリティへの影響を体系的に評価しています。 報告書は、モデルが生成する推論過程は外部のプロンプトや代理モデルを通じてある程度予測可能であるものの、その完全かつ正確な思考の軌跡は依然として非常に不確実で再現性がないと指摘しました。
研究チームは、異なるモデルサイズとタスクタイプを複数の実験で用いて、「代理モデルモニタリング」や「暗黙的ラベリング推論ステップ」を通じてモデルの思考連鎖の透明性と監査可能性を評価する方法を分析しました。 結果は、より高レベルの推論ターゲットは部分的に監視可能であることを示していますが、詳細にはランダム性や機密情報漏洩のリスクが依然として存在します。 報告書は、セキュリティとプライバシーのバランスを維持することを推奨しており、将来的には特定の監督メカニズム、サンドボックス推論、説明的注釈フレームワークを通じてミッションクリティカルなシナリオでAIを改善できると考えています。
OpenAIは記事の最後に、この研究はAIガバナンス、リスク監査、科学研究のセキュリティに関する技術的参照を提供することを目的としており、現在の公開モデルが内部に「完全な思考の連鎖」を持っている、あるいは露出しているという意味ではないと強調しました。 今後の研究では、モデル性能に影響を与えずに推論の透明性とプロセス検証を向上させる方法に焦点を当てます。
FAQsQ: この研究のテーマは何ですか?
A: この研究は主に、大規模言語モデル内の「思考の連鎖」が監視・解釈・部分的に予測可能かどうか、そしてその可視性がもたらすセキュリティ上の影響を探っています。
Q: 「思考の連鎖」とは何ですか?
A: 回答を生成する前のモデルの中間的な推論ステップや論理的プロセスを指し、通常は出力には表示されませんが最終結果に影響を与えます。
Q: この研究で得られた主な結論は何ですか?
A: 思考の連鎖は部分的に予測できますが、完全に再現可能ではなく、ランダム性、プライバシー、悪用のリスクがあります。
Q: なぜ思考の連鎖の監視可能性を研究するのですか?
A: AIシステムのセキュリティと監査性を向上させるために、研究者は重要なタスクにおけるモデルの推論行動をより深く理解できるようになります。
Q: この研究はOpenAIが内部の推論メカニズムを公開したことを意味しますか?
A: いいえ。 本レポートは学術評価およびセキュリティガバナンスの参考用であり、モデルの内部推論にアクセスできるインターフェースや機能については開示していません。