OpenAI veröffentlichte einen Forschungsbericht mit dem Titel "Evaluating Chain-of-Thought Monitoringability", der systematisch die Überwachungs- und Sicherheitsauswirkungen der "Chain-of-Thought" (CoT) innerhalb großer Sprachmodelle bewertet. Der Bericht wies darauf hin, dass der vom Modell erzeugte Schlussfolgerungsprozess zwar bis zu einem gewissen Grad durch externe Eingaben oder Proxy-Modelle vorhergesagt werden kann, sein vollständiger und genauer Denkweg jedoch weiterhin sehr unsicher und nicht reproduzierbar ist.
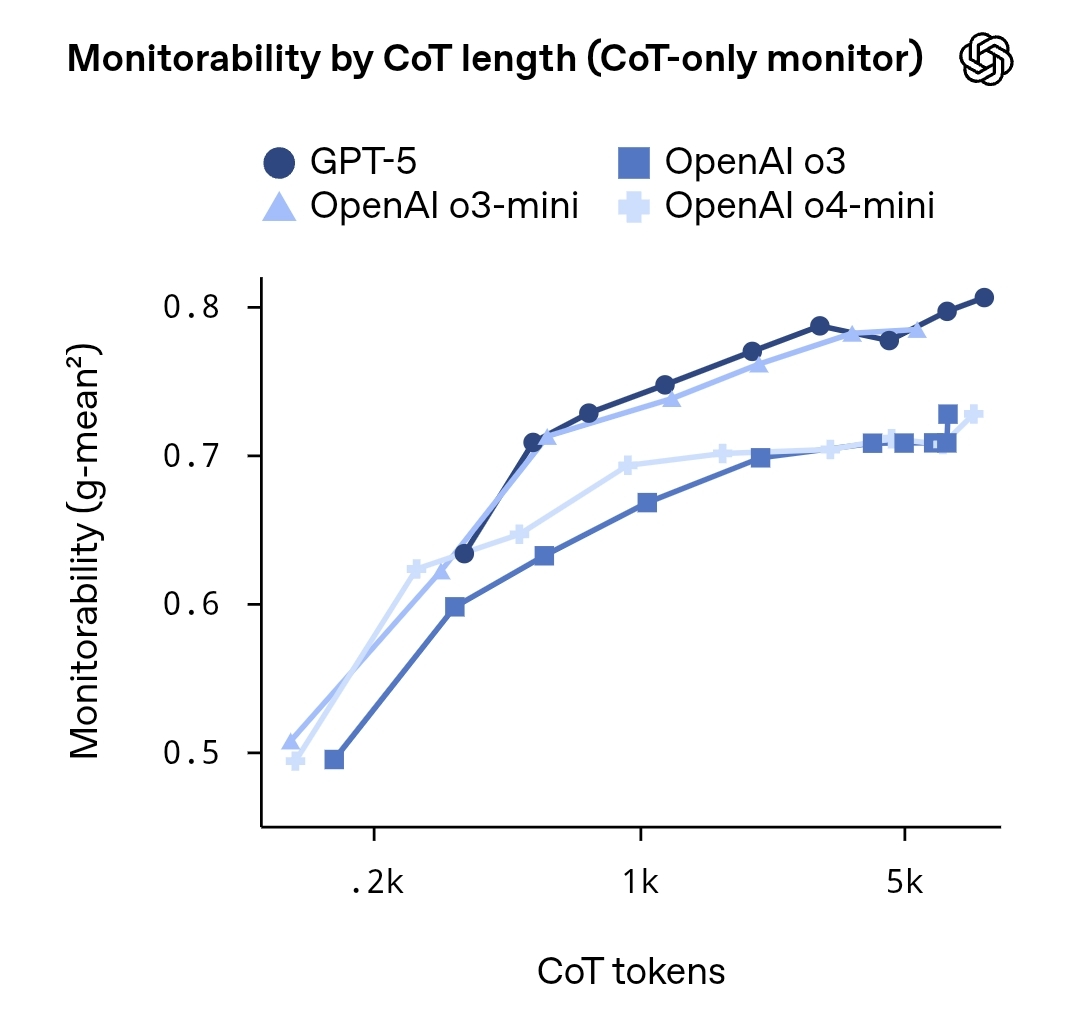
Das Forschungsteam verwendete verschiedene Modellgrößen und Aufgabentypen in mehreren Experimenten, um zu analysieren, wie man die Transparenz und Überprüfbarkeit der Modellkette durch "Proxy-Modellüberwachung" und "implizite Labeling-Denkschritte" bewerten kann. Die Ergebnisse zeigen, dass Inferenzziele auf höherer Ebene teilweise überwacht werden können, aber es besteht weiterhin ein Risiko von Zufälligkeit und dem Leak sensibler Informationen in den Details. Der Bericht empfiehlt, ein Gleichgewicht zwischen Sicherheit und Privatsphäre zu wahren, und in Zukunft kann KI in geschäftskritischen Szenarien durch spezifische Kontrollmechanismen, Sandbox-Argumentation und erklärende Annotationsrahmen verbessert werden.
OpenAI betonte am Ende des Artikels, dass die Studie darauf abzielt, technische Referenzen für KI-Governance, Risikoprüfungen und Sicherheit wissenschaftlicher Forschung zu liefern und nicht bedeutet, dass das aktuelle öffentliche Modell eine interne "vollständige Denkkette" besitzt oder offenlegt. Weitere Forschung konzentriert sich darauf, wie die Inferenztransparenz und Prozessverifikation verbessert werden können, ohne die Modellleistung zu beeinträchtigen.
FAQsQ: Was ist das Thema dieser Studie?
A: Die Forschung untersucht hauptsächlich, ob die "Gedankenkette" in großen Sprachmodellen überwacht, interpretiert oder teilweise vorhergesagt werden kann und welche Sicherheitsimplikationen diese Sichtbarkeit hat.
F: Was ist eine "Gedankenkette"?
A: Bezieht sich auf die zwischenliegenden Schlussfolgerungsschritte oder logischen Prozesse des Modells vor der Erzeugung von Antworten, die in der Regel im Output nicht sichtbar sind, aber das Endergebnis beeinflussen.
F: Was sind die wichtigsten Schlussfolgerungen der Studie?
A: Gedankenketten können teilweise vorhergesagt werden, aber sie können nicht vollständig reproduzierbar sein, und es gibt Risiken für Zufall, Privatsphäre und Missbrauch.
F: Warum sollte man die Überwachungsfähigkeit von Denkketten untersuchen?
A: Um die Sicherheit und Überprüfbarkeit von KI-Systemen zu verbessern, können Forscher das Denkverhalten von Modellen bei kritischen Aufgaben besser verstehen.
F: Bedeutet die Forschung, dass OpenAI seine internen Denkmechanismen offengelegt hat?
A: Nein. Der Bericht dient ausschließlich der akademischen Bewertung und der Referenz zur Sicherheitsgovernance und offenbart keine Schnittstellen oder Funktionen, die auf die interne Inferenz des Modells zugreifen können.