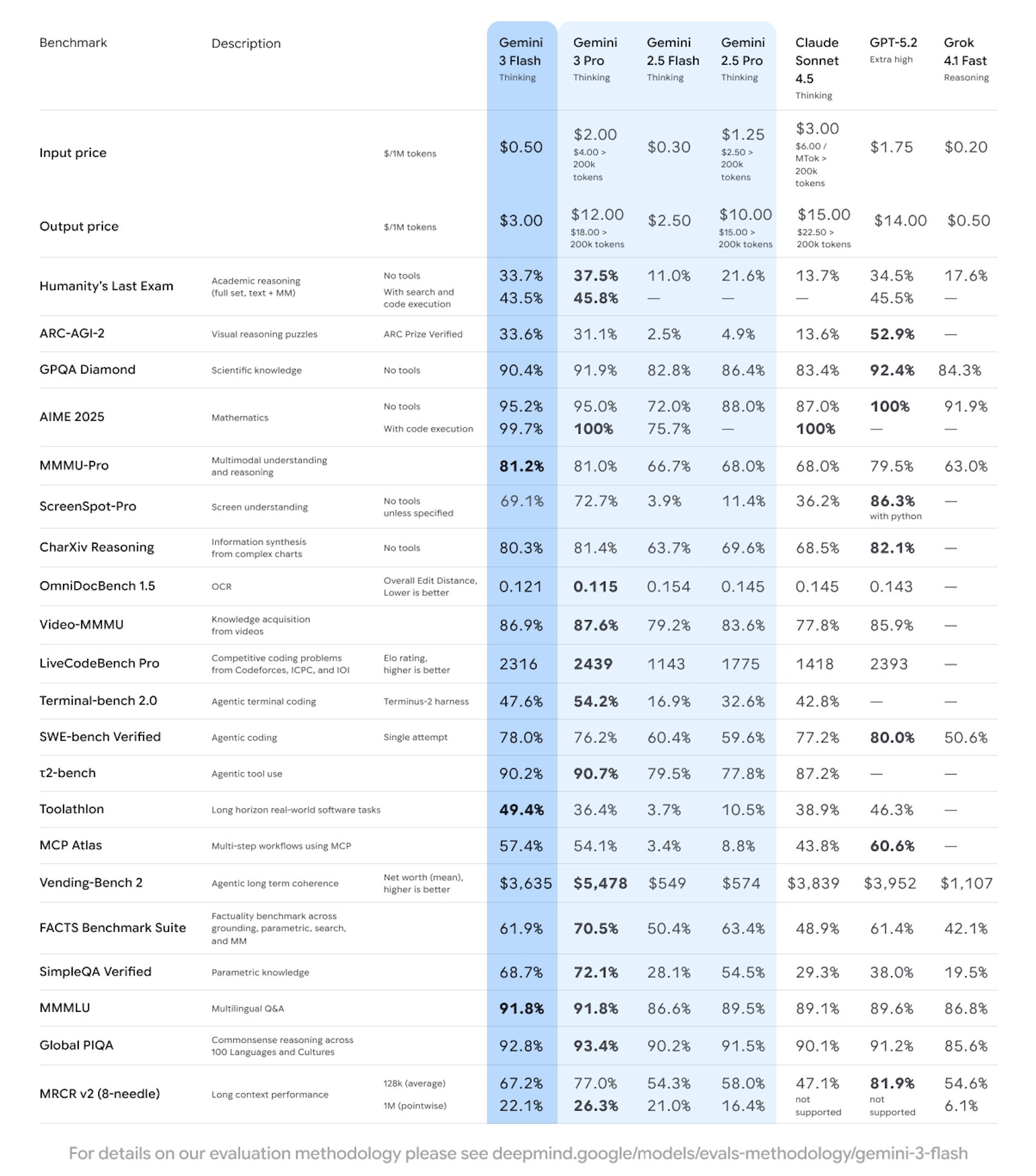
Google a annoncé le lancement d’une nouvelle génération de modèle léger et de pointe, Gemini 3 Flash, qui met l’accent sur la grande vitesse, la faible latence et la disponibilité à grande échelle, et déclare officiellement qu’il est plus puissant que Gemini 2.5 Pro dans la plupart des tests, renforçant considérablement les capacités de codage et d’appel d’outils. Le modèle a été présenté en avant-première dans Gemini API/AI Studio, Vertex AI et Gemini CLI, et a été activé simultanément dans certains scénarios produits. La tarification est de 0,50 $ par million de jetons en entrée et de 3,00 $ par million de jetons en production (y compris les jetons pensants).
Selon l’introduction officielle, Gemini 3 Flash optimise le débit et les coûts tout en maintenant des capacités d’inférence et de compréhension multimodale, ce qui le rend adapté aux applications à forte concurrence et aux flux de travail d’agents. Les entreprises et les développeurs peuvent alterner entre « vitesse/profondeur » selon les besoins. La version actuelle est en aperçu, et la capacité ainsi que le quota peuvent être ajustés au fur et à mesure de la sortie. La disponibilité régionale, la limitation des tarifs et les règles de facturation des différentes plateformes sont soumises aux règles réelles de chaque plateforme. Certaines fonctionnalités premium ou quotas supérieurs nécessitent un abonnement ou l’activation du service correspondant.
FAQ
Q : Qu’est-ce que Gemini 3 Flash et à quels scénarios est-il destiné ?
R : Il s’agit d’un modèle à grande vitesse et efficace de la série Gemini 3, adapté à des scénarios à faible latence tels que le codage, l’appel d’outils et l’inférence multimodale.
Q : Comment la Gemini 3 Flash se compare-t-elle à la 2.5 Pro ?
R : Les responsables et plusieurs évaluations affirment qu’il est plus solide sur la plupart des indicateurs et qu’il performe mieux sur des tâches telles que le codage proxy.
Q : Quel est le prix et la méthode de facturation ?
R : Entrer 0,50 $/million de tokens, sortir 3,00 $/million de tokens, et le prix de sortie inclut les jetons pensants.
Q : Comment l’utiliser maintenant ?
R : Il peut être appelé sous forme de « preview » dans Gemini API, AI Studio, Vertex AI et Gemini CLI, et le quota et la région spécifiques sont soumis à chaque plateforme.
Q : Est-ce que c’est entièrement et stable ?
R : Ceci est actuellement en aperçu, et la capacité, la limite et la plage de disponibilité peuvent encore être ajustées.



