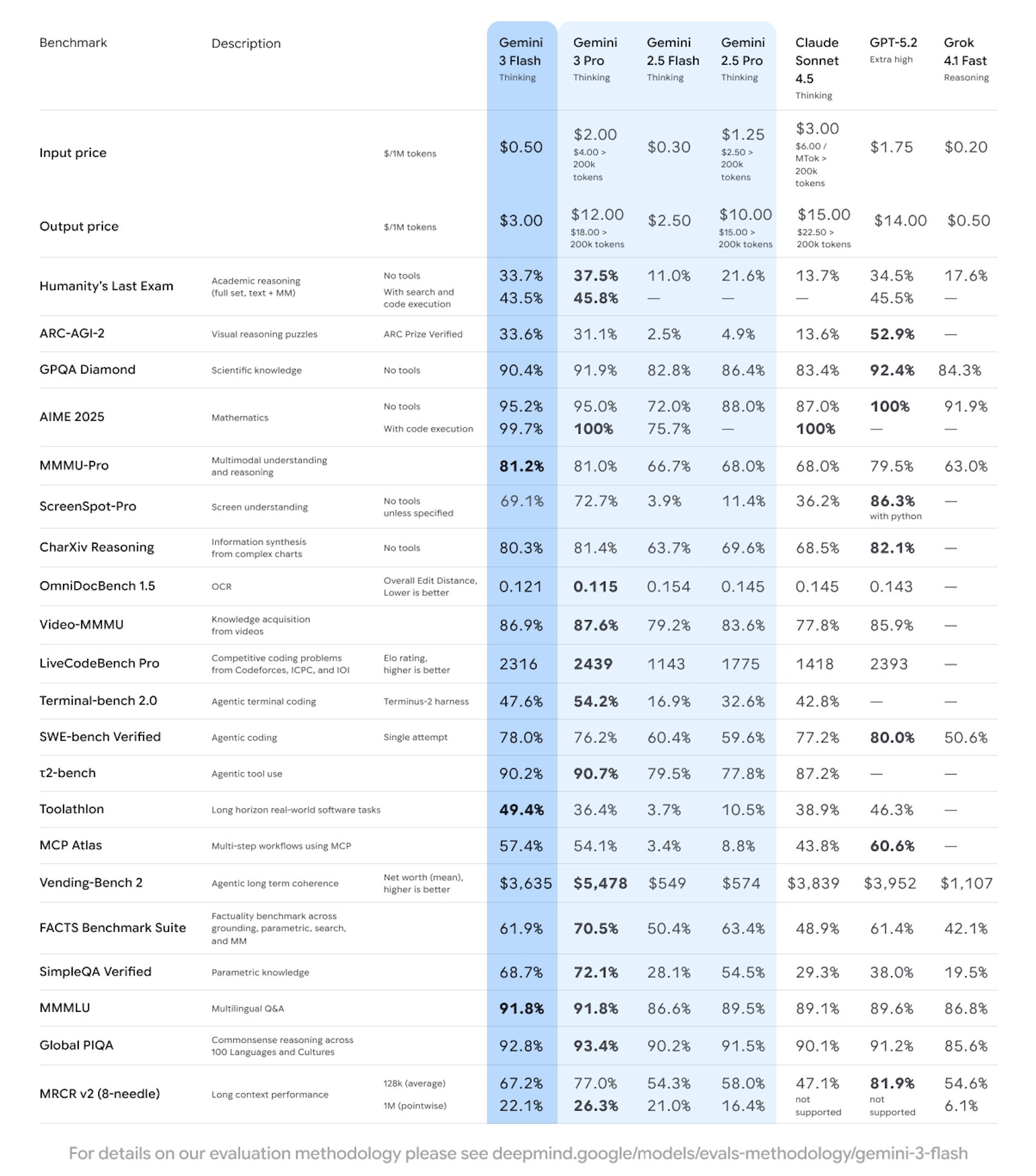
Google宣布推出新一代轻量前沿模型 Gemini 3 Flash,主打高速、低延迟与规模化可用,官方称其在多数评测上强于 Gemini 2.5 Pro,并显著强化编码与工具调用能力。该模型已在 Gemini API/AI Studio、Vertex AI 与 Gemini CLI 等渠道提供预览使用,部分产品场景同步启用。定价为输入每百万tokens 0.50 美元、输出每百万tokens 3.00 美元(含思考tokens)。
官方介绍称,Gemini 3 Flash在保持推理与多模态理解能力的同时优化吞吐与成本,适合高并发应用与智能体工作流;企业与开发者可按需在“速度/深度”间权衡。当前版本处于预览阶段,能力与配额可能随发布推进而调整;不同平台的地区可用性、速率限制与计费细则以各平台实际规则为准。部分高级功能或更高配额需订阅或开通相应服务。
常见问题
Q:Gemini 3 Flash是什么模型,面向哪些场景?
A:它是Gemini 3系列的高速高效模型,适合编码、工具调用与多模态推理的低延迟场景。
Q:Gemini 3 Flash与2.5 Pro相比如何?
A:官方与多家测评称其在多数指标上更强,并在代理式编码等任务上表现更优。
Q:价格与计费方式是什么?
A:输入0.50美元/百万tokens,输出3.00美元/百万tokens,输出价格包含思考tokens。
Q:现在如何使用?
A:可在Gemini API、AI Studio、Vertex AI与Gemini CLI中以“预览”形式调用,具体配额与地区以各平台为准。
Q:是否已经全面稳定上线?
A:目前为预览阶段,能力、限额与可用范围仍可能调整。



