1. Abstract
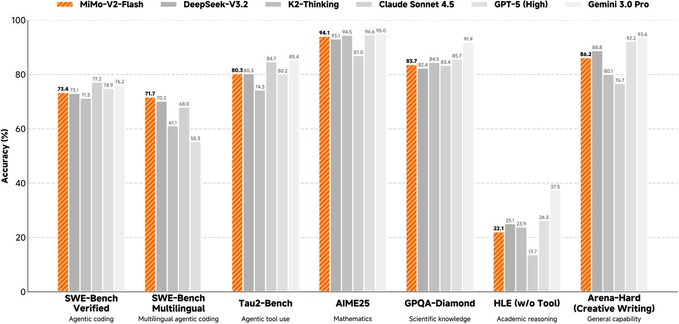
MiMo-V2-Flash ist ein Open-Source-Hybrid-Experten (MoE) großes Sprachmodell des Xiaomi MiMo-Teams mit einem Gesamtparameter von etwa 309B und einem Aktivierungsparameter von etwa 15B während der Inferenz, wobei der Fokus darauf liegt, Inferenz-, Programmierungs- und Agentenworkflows mit niedrigen Inferenzkosten auszubalancieren. Es betont das Gleichgewicht zwischen Langkontext-Fähigkeiten (bis zu 256K) und Inferenzeffizienz und liefert reproduzierbare technische Berichte, Gewichtungen und Beispiele für Inferenzdeployments.
2. Kernfunktionen
- MoE-kosteneffizientes Denken: Die gesamte Parameterskala ist groß, aber nur einige Experten werden jedes Mal aktiviert, was den Rechenleistungsverbrauch pro Anfrageeinheit reduziert.
- Hybride Aufmerksamkeitsarchitektur: Gestaffelte Nutzung von Stinging-Window-Aufmerksamkeit und globaler Aufmerksamkeit, um den Druck des KV-Caches zu verringern und dabei langfristige Kontexteffekte beizubehalten.
- Multi-Token-Vorhersage (MTP): Ein Multi-Token-Vorhersagemodul, das in Training/Inferenz integriert ist, um den Generierungsdurchsatz und die Gesamtgeschwindigkeit der Inferenz zu verbessern.
- Nachschulung für Agenten: Kombiniert Multi-Lehrer-Destillation mit groß angelegtem Agenten-Reinforcement-Learning, um es in Code-Agenten und komplexen Argumentationsevaluationen "ausführbarer" zu machen.
- Langes Kontext-Support: Bietet Konfigurations- und Inferenzvorschläge für die Länge der nativen Trainingssequenzen von 32K und ein bis zu 256K Kontextfenster (der tatsächliche Effekt hängt stark mit den Ressourcenanforderungen zusammen).
3. Installation
- Gewichte holen: Das entsprechende Modell (wie XiaomiMiMo/MiMo-V2-Flash) aus Hugging Face ziehen.
- Installieren Sie das Inferenz-Framework: Der Offizielle empfiehlt, SGLang (pip install sglang) zu verwenden und den Server gemäß dem Beispiel zu starten.
- Start und Anruf: Stellen Sie eine Anfrage über die kompatible Chat-/Abschluss-Schnittstelle von OpenAI; Es wird empfohlen, zunächst die offizielle Temperatur/top_p mit dem Parameter der Kontextlänge auszurichten.
4. Typische Anwendungsfälle
- Codegenerierung und -reparatur: Für Aufgaben wie Repository-Probleme, Patchgenerierung und einzelne, testgetriebene Reparaturen.
- Tool-Call-Agents: Durchsuchen, abrufen, Skripte ausführen und mehrstufige Aufgaben orchestrieren (müssen mit Tool-Management und Berechtigungsisolation zusammenarbeiten).
- Lange Dokumentenargumentation: lange Textzusammenfassung, kapitelübergreifende Frage-und-Antwort-Szenarien, langes Dialoggedächtnis (besser geeignet für "strukturierte Eingaben + klare Ziele"-Szenarien).
- Online-Inferenz mit hoher Nebenläufigkeit: Mit MoE und effizientem Aufmerksamkeitsdesign eignet es sich für serverseitige Szenarien, die auf Durchsatz und Kosten achten.
5. Ökosystem und Wettbewerber
- Ökosystem: GitHub-Repositories, technische Berichte und Hugging Face-Gewichte bereitstellen. Und gib SGLang als wichtigen Bereitstellungspfad.
- Konkurrenzprodukte: Können mit Open-Source-Modellen verglichen werden, die ebenfalls Argumentation/Code/Agent betonen (wie DeepSeek, Kimi usw.). Der Unterschied zwischen MiMo-V2-Flash konzentriert sich stärker auf die Kombination von "Langkontext + KV-freundlich + MTP-Beschleunigung + kleine MoE-Aktivierungsparameter". Verschiedene Unternehmen müssen sich selbst testen lassen.
6. Einschränkungen und Vorsichtsmaßnahmen
- Ressourcenschwelle: Selbst wenn die Aktivierungsparameter klein sind, erfordert die Einführung von MoE auf 309B-Ebene hohe Anforderungen an Mehrkartenverbindungen, Videospeicher und Engineering-Stack.
- Kosten für lange Kontexte: 256K Eingaben können den Speicherverbrauch und die Latenz erheblich erhöhen, daher müssen Abschnitts-Prefill-, Nebenläufigkeits- und Kontextmanagement-Richtlinien sorgfältig eingestellt werden.
- "Historikerbewahrung"-Anforderungen für Werkzeugaufrufe: Mehrrunden-Denk- und Werkzeugaufrufszenarien müssen korrekt Inferenzfelder und historische Nachrichten speichern und zurückgeben, sonst ist es leicht, die Kette zu unterbrechen.
- Lizenz und Compliance: Die Lagerhaus-LIZENZ hat Vorrang; Kommerziell und Vertrieb erfordern die Überprüfung von Lizenzbedingungen, gewichteten Nutzungsbedingungen und Anforderungen an die Datenkonformität.
7. Projektadresse
https://github.com/XiaomiMiMo/MiMo-V2-Flash
8. FAQ
F: Wichtige Spezifikationen von MiMo-V2-Flash (309B/15B, 256K) steht für jeden?
A: 309B ist die Gesamtparameterskala, und 15B ist die Parameterskala für eine einzelne Inferenzaktivierung; 256K ist die maximale Kontextfenster-Konfiguration, und je länger es ist, desto mehr Speicher und Latenz verbraucht es.
F: Wie wird empfohlen, Inferenz mit MiMo-V2-Flash einzusetzen?
A: Der Offizielle empfiehlt die SGLang-Route, die den Server gemäß dem Beispiel startet und über eine kompatible Schnittstelle aufruft. Ultra-lange Kontexte und hohe Nebenläufigkeit erfordern eine Kombination aus Multi-Card-Parallelität und Caching-Strategien.
F: Was sind für mich die wirklichen Vorteile von MiMo-V2-Flashs Hybrid Attention und MTP?
A: Der Hauptvorteil besteht darin, den Druck des Langkontext-KV-Caches zu verringern und den Erzeugungsdurchsatz zu erhöhen, wodurch die Inferenzkosten bei ähnlicher Qualität gesenkt werden; Der genaue Gewinn hängt von der Hardware, der Batchgröße und der Servicekonfiguration ab.
F: Ist MiMo-V2-Flash für den lokalen Betrieb mit einer einzelnen Karte geeignet?
A: Im Allgemeinen nicht geeignet; Ein realistischerer Weg ist eine Multi-Card-Server-Bereitstellung oder die Nutzung eines Drittanbieter-Hosting-/API-Erlebnisses.