I. Summary
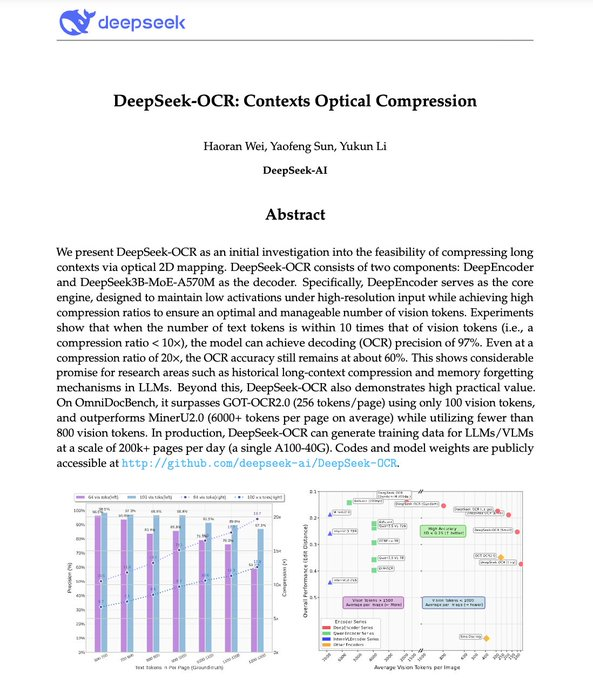
DeepSeek-OCR is DeepSeek's open-source "contextual optical compression" model. It encodes document text into visual tokens and then decodes them back into text. Its goal is to significantly reduce the contextual token cost of LLM while maintaining recognition accuracy. Community and media reports indicate that it achieves approximately 97% decoding accuracy at approximately 10× compression , and maintains approximately 60% usable accuracy at 20× compression. The model offers multiple resolutions and dynamic cropping modes, making it suitable for high-throughput inference on PDFs and images. The performance above is based on official and media reports based on experimental results. The actual effectiveness requires verification with in-house data.
2. Core Features
1. Visual-text compression : Replace plain text tokens with visual encodings, significantly reducing context length and inference costs.
2. Multi-resolution modes : Tiny/Small/Base/Large (64/100/256/400 visual tokens) and dynamic resolution ("Gundam" solution).
3. Flexible reasoning path : Provides both vLLM and Transformers reasoning scripts, and supports image and PDF batch processing.
4. Document structure understanding : Examples of Markdown conversion and structured extraction instructions for layout/table/diagram.
5. Open source and reproducible : MIT license, the repository contains installation, configuration and visualization examples.
3. Installation
1. Clone the repository: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git and enter the directory.
2. Create environment: conda create -n deepseek-ocr python=3.12.9 -y && conda activate deepseek-ocr.
3. Dependency installation: Install the CUDA/PyTorch version specified in the README, pip install -r requirements.txt, and install the matching vLLM/Flash-Attention.
4. Weighting and Inference: Pull deepseek-ai/DeepSeek-OCR from Hugging Face and run image/PDF OCR and evaluation according to the vLLM or Transformers script provided in the repository.
Typical Use Cases
1. Long document OCR → Markdown : quickly convert journals/reports into editable text, reducing manual cleaning.
2. Enterprise Archiving and Retrieval : Use visual tokens to compress context in RAG (Retrieval Enhanced Generation) to expand the scope of retrieval and question-answering.
3. Structuring of bills/forms : Position and analyze the layout/form/diagram to produce semi-structured results.
4. Batch PDF Throughput : Concurrently process multiple PDF pages in a single card environment, reducing computing power and cost pressure.
5. Ecosystem and Competitive Products
1. Ecosystem : Natively compatible with Hugging Face; scripts cover vLLM/Transformers; README provides PDF/images and batch evaluation examples.
2. Comparison with Competitive Products : Community reports indicate that this product outperforms GOT-OCR2.0 and MinerU in terms of compression/accuracy-token efficiency, and significantly reduces token usage. However, different benchmarks and data distributions significantly impact the results, requiring retesting using the same data and evaluation procedures.
VI. Limitations and Precautions
1. Indicator transferability : 10×≈97% and 20×≈60% are official/media experimental values. Transfer to legal, medical, and other scenarios requires separate verification.
2. Image quality dependency : Low definition/complex layouts will affect decoding quality. It is recommended to combine layout analysis and resampling.
3. Computing power and environment : Although there are fewer tokens, visual coding still requires GPU memory and appropriate CUDA/driver versions.
4. Compliance and Privacy : When processing documents containing sensitive information, local deployment should be prioritized and data compliance policies should be followed.
7. Project Address
https://github.com/deepseek-ai/DeepSeek-OCR
8. Frequently Asked Questions
Q: How do you understand DeepSeek-OCR's "10× compression ≈ 97% decoding accuracy" and "20× ≈ 60%"?
A: This refers to the accuracy level of decoding back to text when the ratio of visual tokens to text tokens reaches approximately 1:10/1:20. For laboratories and media to disclose results, they must be verified based on their own data.
Q: What are the differences in token usage and throughput compared to GOT-OCR2.0 and MinerU?
A: The official README and media reports claim that it has advantages in compression rate and token efficiency; however, different benchmarks, hardware, and concurrency strategies will affect the comparison. We recommend that you use a unified evaluation script and retest data.
Q: What is the recommended path for deployment and inference (vLLM vs Transformers)?
A: vLLM is suitable for high-throughput/concurrency scenarios; Transformers facilitates secondary development and integration. Scripts for both are available in the repository, allowing you to choose based on your scenario.
Q: When will Dynamic Resolution (Gundam) be enabled?
A: When a page contains a mix of small text and large icons, dynamic cropping + high-resolution main view can take into account both details and the overall layout.



