2025年10月16日、PaddleOCRはマルチモーダル文書解析モデルPaddleOCR-VLのリリースを発表しました。これはバージョン3.3.0のコア機能としてリリースされました。約0.9Bサイズのこのモデルは、NaViTスタイルの動的解像度ビジュアルエンコーダーとERNIE-4.5-0.3B言語モデルを組み合わせることで、テキスト、表、数式、グラフ、手書きなどの要素の統合認識と構造化出力を実現します。OmniDocBenchなどの公開データセットおよび自社構築データセットによる公式評価では、PaddleOCR-VLはページレベルの解析と特徴レベルの認識の両方において、最先端のパフォーマンスを達成または上回ることが示されています。
PaddleOCR-VLは、中国語、英語、日本語、ラテン語、アラビア語、キリル文字、デーバナーガリー文字を含む109の言語と文字体系をカバーしていると主張しています。実世界の生産に合わせて推論効率を最適化し、PP-StructureV3やPP-OCRv5などのPaddleOCRコンポーネントと併用できます。モデルとドキュメントは、GitHub、HuggingFace、および公式ドキュメントで入手できます。詳細なベンチマーク、可視化例、導入方法については、公式ウェブサイトをご覧ください。データセットのバージョンや評価範囲など、詳細についてはリポジトリの更新情報にご注目ください。
よくある質問
Q: PaddleOCR-VLとは何ですか?
A: エンドツーエンドのドキュメント解析用の約 9 億のパラメータを備えたビジュアル言語モデルで、テキスト、表、数式、グラフ、手書きを同時に処理し、構造化された結果を出力できます。
Q: なぜ「超小型」というのですか?
A: マルチモーダルVLMにおいて、0.9Bは比較的サイズが小さく、推論効率も優れています。NaViTの動的解像度とERNIE-4.5-0.3Bを組み合わせることで、精度を維持しながら計算能力の要件を削減できます。
Q: 本当に SOTA に到達したのでしょうか?
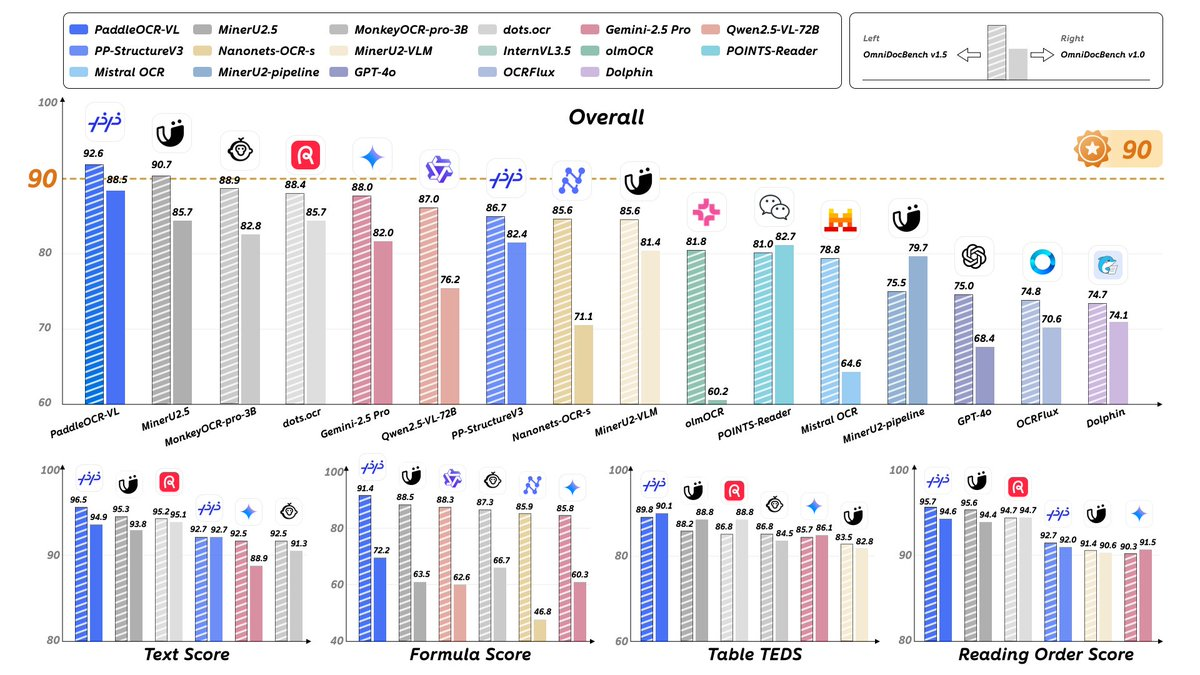
A: OmniDocBench v1.5/v1.0などのベンチマークや、当社独自のベンチマークにおいて、全体的なパフォーマンス、読み上げ順序、表、数式など、複数の指標において優れた結果を示しました。結論は、公開レポートおよびモデルカードに記載されているグラフと説明に基づいています。
Q: どのような言語とアプリケーションシナリオがサポートされていますか?
A: 109言語をカバーし、多言語組版、歴史的文書、複雑なレイアウトといったシナリオに適しています。PP-StructureV3のレイアウト/表構造化機能と連携することで、実際のビジネス分析に活用できます。
Q: どこで入手し、どのように試すことができますか?
A: GitHub ではバージョンノートとコマンドライン/Python API が提供されており、HuggingFace ではモデルカードとオンラインデモのリンクが提供されており、ドキュメント サイトではデプロイメントとアクセラレーション (vLLM/sglang サーバーなど) のガイドが提供されています。