Le 16 octobre 2025, PaddleOCR a annoncé le lancement de son modèle d'analyse de documents multimodal, PaddleOCR-VL, intégré à la version 3.3.0. Ce modèle, d'environ 0,9 milliard de pages, utilise un encodeur visuel à résolution dynamique de type NaViT, associé au modèle de langage ERNIE-4.5-0,3 milliard de pages, pour une reconnaissance unifiée et une sortie structurée d'éléments tels que le texte, les tableaux, les formules, les graphiques et l'écriture manuscrite. Des évaluations officielles réalisées sur des bases de données publiques et auto-construites, telles qu'OmniDocBench, montrent que PaddleOCR-VL atteint, voire surpasse, les performances de pointe en matière d'analyse de pages et de reconnaissance de caractéristiques.
PaddleOCR-VL prétend couvrir 109 langues et écritures, dont le chinois, l'anglais, le japonais, le latin, l'arabe, le cyrillique et le devanagari. Il optimise l'efficacité de l'inférence pour la production en conditions réelles et peut être utilisé conjointement avec des composants PaddleOCR tels que PP-StructureV3 et PP-OCRv5. Le modèle et la documentation sont disponibles sur GitHub, HuggingFace et la documentation officielle. Pour des benchmarks détaillés, des exemples de visualisation et des méthodes de déploiement, veuillez consulter le site web officiel. Restez à l'écoute des mises à jour du référentiel pour plus d'informations, notamment sur les versions des jeux de données et le périmètre d'évaluation.
Questions fréquemment posées
Q : Qu'est-ce que PaddleOCR-VL ?
A : Un modèle de langage visuel avec environ 0,9 milliard de paramètres pour l’analyse de documents de bout en bout qui peut traiter simultanément du texte, des tableaux, des formules, des graphiques et de l’écriture manuscrite, et générer des résultats structurés.
Q : Pourquoi l'appelle-t-on « ultra-compact » ?
R : Dans le VLM multimodal, 0,9 B est relativement petit et efficace en inférence. En combinant la résolution dynamique NaViT avec ERNIE-4,5-0,3 B, la puissance de calcul requise est réduite tout en maintenant la précision.
Q : Est-ce que cela a vraiment atteint SOTA ?
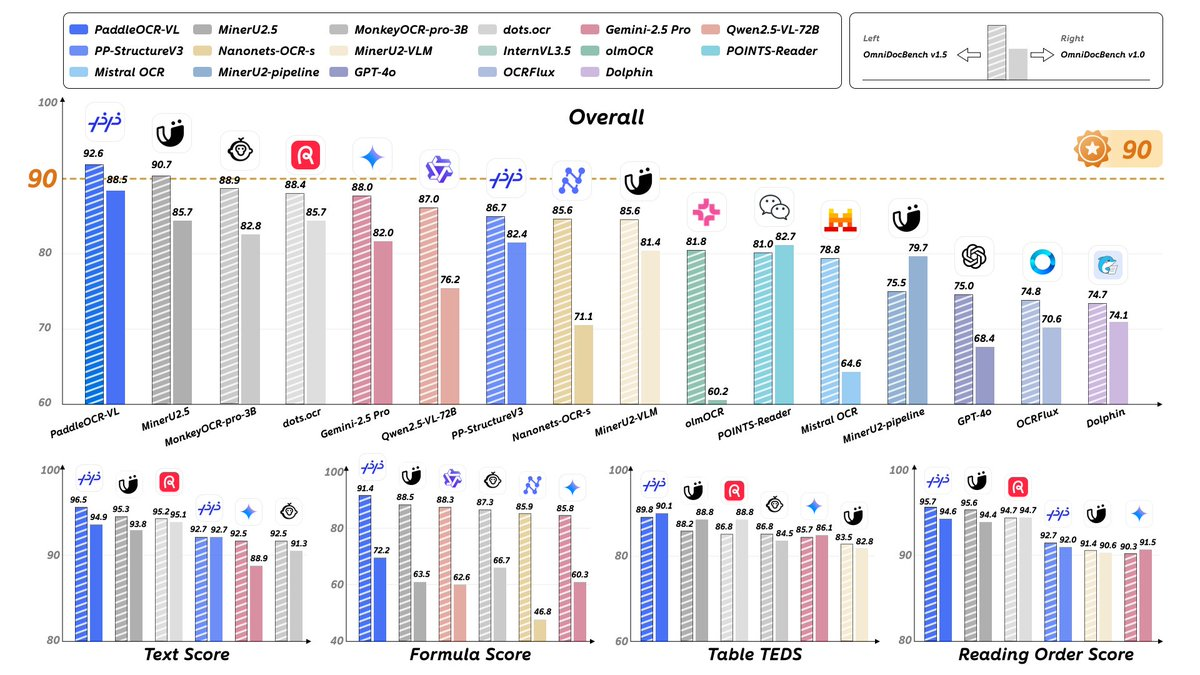
R : Nous avons obtenu des résultats exceptionnels lors d'analyses comparatives telles qu'OmniDocBench v1.5/v1.0 et nos propres analyses, couvrant de nombreux indicateurs tels que la performance globale, l'ordre de lecture, les tableaux et les formules. Nos conclusions s'appuient sur les graphiques et les explications fournis dans les rapports publics et les fiches modèles.
Q : Quelles langues et quels scénarios d’application sont pris en charge ?
R : Il couvre 109 langues et convient à des scénarios tels que la composition multi-écritures, les documents historiques et les mises en page complexes. Il peut être associé aux fonctionnalités de structuration de mise en page et de tableaux de PP-StructureV3 pour une analyse métier concrète.
Q : Où puis-je l'obtenir et comment puis-je l'essayer ?
R : GitHub fournit des notes de version et des API de ligne de commande/Python ; HuggingFace fournit des cartes de modèles et des liens de démonstration en ligne ; le site de documentation fournit des guides de déploiement et d'accélération (tels que le serveur vLLM/sglang).