LongCatチームはLongCat-Audio DiTをリリースし、コード、テクニカルレポート、Hugging Faceウェイトを公開しました。主にWaveform Latent Spaceで直接TTSを拡散させ、メルのような中間表現に戻ることはありません。Voice Circleの注目を集めたのは、音色クローンスコア、モデル重み、推論コードをテーブルに並べたことです。
一,今回最も重要なのはパラメータではなく,生成経路が変更された
LongCat-AudioDiTは非自己回帰拡散経路をとり,構造上はWav − VAE + Diffusionの2段に押されている.これはカスケードエラーを低減し、音声生成リンクを短縮し、拡散TTSの一般的な歪み問題に対処するためです。
第二に、この波は論文だけではなく、1 Bと3.5 Bはすでに
開発者にとっては、通常のTTSとPrompt Audioを使用したボイスクローニングの両方が直接検証できるため、1つのレポートだけを与えるよりもはるかに現実的です。
3、公式は最も強調したいのはSeed Benchmarkのサウンドクローンのスコア
HTML_TAG_TAG_TAG_12 このスコアは印象的ですが、より安全な理解は“公式ベンチマークでリードしている”ことであり、より多くのコミュニティのオーディションと再現結果を見る必要があります。
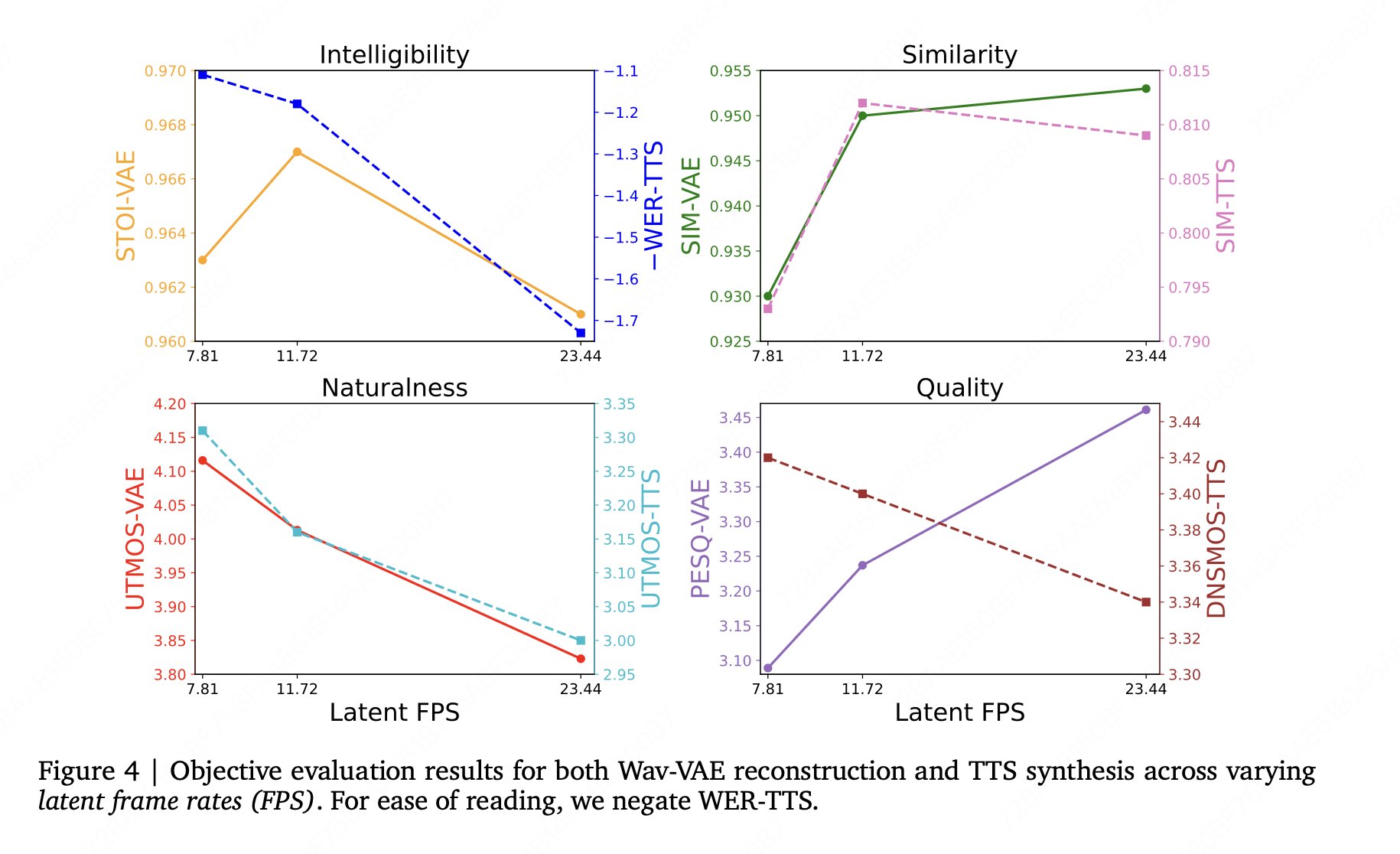
報告書のもう一つの簡単な結論は直感に反するものです。VAEの再構築は優れており、必ずしも全体的なTTS性能の向上と直接相関しません。
V、このセットの価値がないと判断する方法は、今すぐ試してみてください
を見てください:最初にリポジトリが完全な推論エントリを提供しているかどうかを見てください。今では両方が導入されているので、単にコンセプトデモで止まるのではなく、実行可能なリサーチベースのオープンソースのセットのようなものです。