LongCat 团队已发布 LongCat-AudioDiT,并同步放出代码、技术报告和 Hugging Face 权重。它主打直接在 waveform latent space 做扩散 TTS,不再绕回 mel 这类中间表示。最能吸引语音圈注意的,是它把音色克隆分数、模型权重和推理代码一起摆上桌。
一、这次最重要的不是参数,而是生成路径变了
LongCat-AudioDiT 走的是非自回归扩散路线,结构上压成 Wav-VAE 加 Diffusion 两段。官方给出的核心说法很直接:这样做是为减少级联误差,把语音生成链路缩短,也把扩散 TTS 常见的失真问题往前处理。
二、这波不是只发论文,1B 和 3.5B 都已经能下
仓库已经放出推理代码,模型页也给了 1B 和 3.5B 两个版本,支持中文和英文音频生成。对开发者来说,这比只给一篇报告更实在,因为普通 TTS 和带 prompt audio 的 voice cloning 都能直接验证。
三、官方最想强调的是 Seed Benchmark 上的音色克隆成绩
按公开模型卡,3.5B 版本在 Seed-ZH 和 Seed-Hard 的 SIM 分别到 0.818 和 0.797,1B 版本也到 0.812 和 0.787。这个分数很抓眼,但更稳妥的理解仍是“按官方公布基准表现领先”,后续还要看更多社区试听和复现结果。
四、真正有技术含量的点,是 APG 和 mismatch 处理
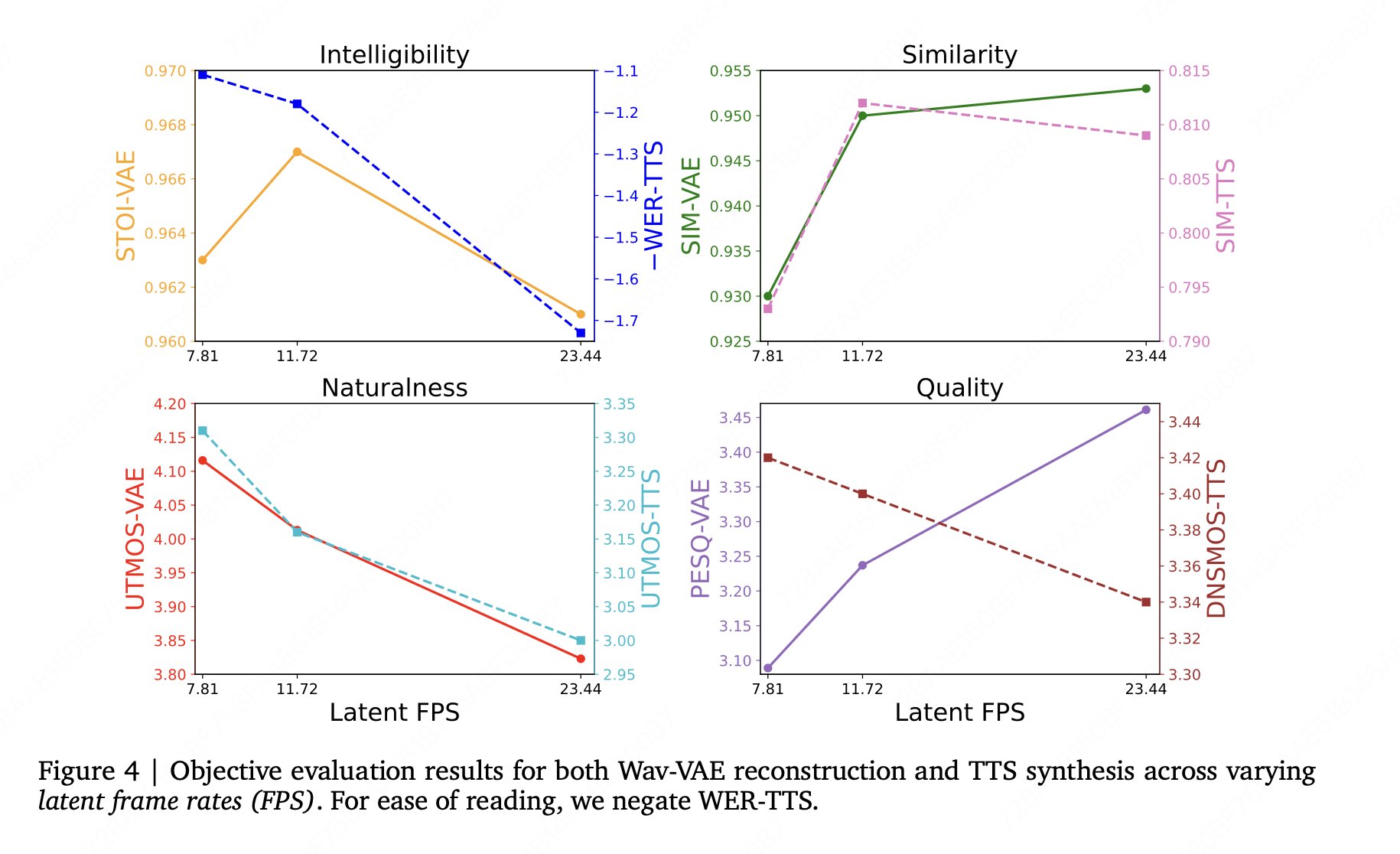
这次不只是把 CFG 换成了 APG,团队还把 diffusion TTS 里长期存在的 training-inference mismatch 单独拿出来解决。报告里另一个容易被记住的结论也很反直觉:VAE 重建更好,不一定直接换来更强的整体 TTS 表现。
五、怎么判断这套东西值不值得你现在就试
看两步就够:先看仓库是否已提供完整推理入口,再看模型页是否已挂出可直接调用的权重。现在这两项都已到位,所以它更像一套可跑的研究型开源,而不只是停在概念演示。