Das LongCat-Team hat LongCat-AudioDiT veröffentlicht und gleichzeitig den Code, den technischen Bericht und das Hugging Face-Gewicht veröffentlicht. Es ist wichtig, TTS direkt im latenten Raum der Wellenform zu verbreiten und nicht mehr zurückzukehren, um die mittleren Darstellungen wie Mel. Was die Aufmerksamkeit der Sprachsphäre am meisten auf sich zieht, ist, dass es Ton-Klon - Punkte, Modellgewichte und Inferenzcode zusammen auf den Tisch bringt.
Der Kern des offiziellen Statements ist unkompliziert: Dies soll die Kaskadenfehler reduzieren, die Sprachgenerierung verringern und die häufigen Verzerrungen bei Diffusion-TTS vorantreiben. Für Entwickler ist dies viel realistischer, als nur einen Bericht zu geben, da sowohl normale TTS als auch Voice Cloning mit prompt Audio direkt überprüft werden können.Dritten, die offiziell am meisten betonen möchte, ist die Tonal-Kloning - Leistung auf Seed Benchmark
Nach dem öffentlichen Modellkarte, 3.5B-Version in Seed-ZH und Seed-Hard SIM zu 0,818 und 0,797, 1B-Version auch zu 0,812 und 0,787. Diese Punktzahl ist sehr auffällig, aber ein sichereres Verständnis ist immer noch "Leiter in der offiziellen Benchmark", und es wird nach weiteren Community Auditions und Wiederholungsergebnissen erwartet.
Viert, wirklich technischer Inhalt Punkt, ist APG und Mismatch-Verarbeitung
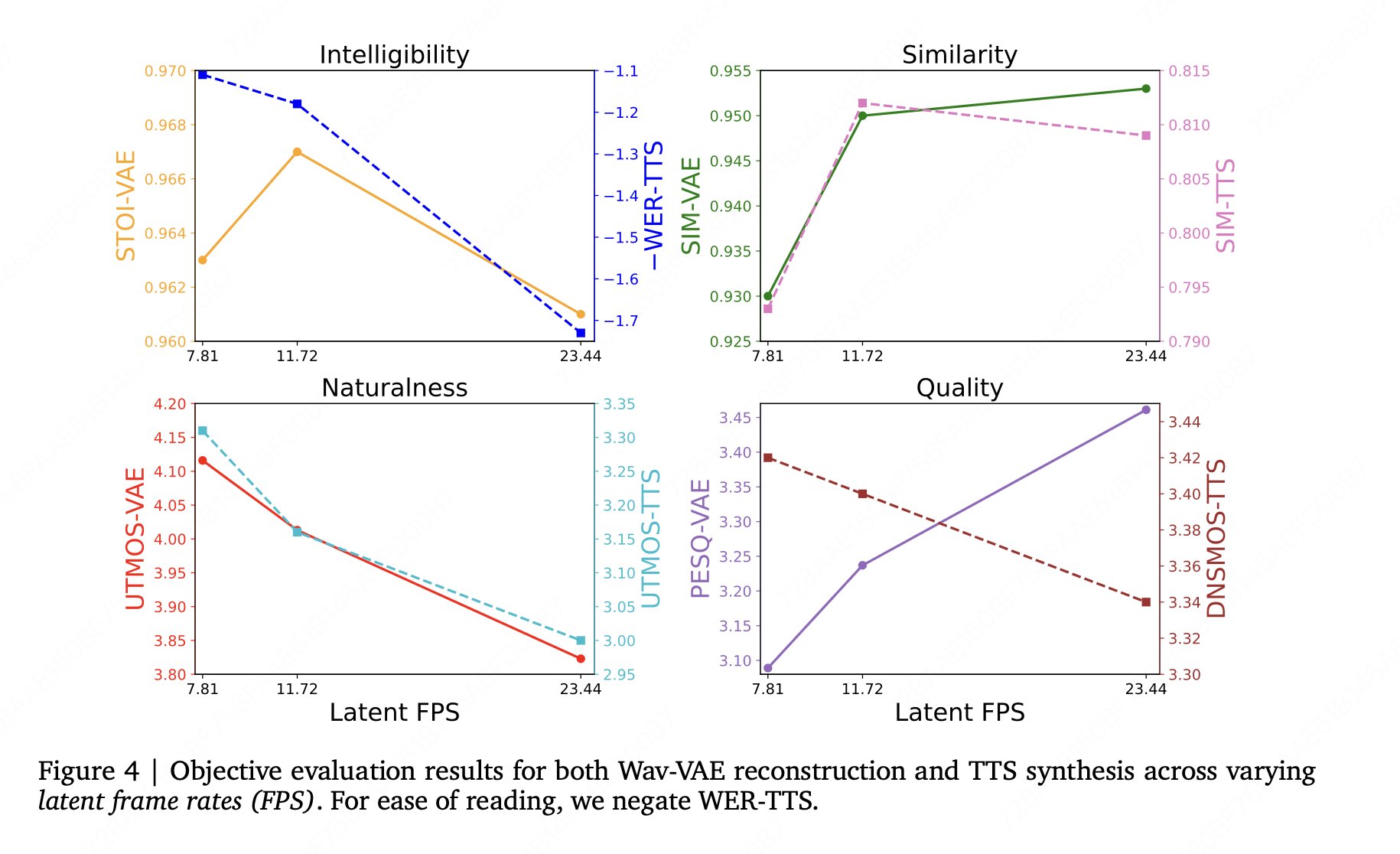
Dieses Mal nicht nur CFG in APG ersetzt, das Team auch die langjährige Training-Inference - Mismatch in diffusion TTS allein zu lösen. Ein weiteres Ergebnis des Berichts, das leicht zu erinnern ist, ist auch kontraintuitiv: Eine bessere VAE-Rekonstruktion führt nicht unbedingt direkt zu einer stärkeren Gesamtleistung von TTS. Jetzt sind beides vorhanden, so dass es eher wie eine laufbare, forschungsorientierte Open-Source - Suite aussieht, anstatt nur bei einer Konzept-Demonstration zu bleiben.